Command Palette
Search for a command to run...
ReMix:LLM 微調整における LoRA 混合物のための強化学習ルーティング
ReMix:LLM 微調整における LoRA 混合物のための強化学習ルーティング
概要
低ランクアダプタ(LoRA)は、事前学習済みモデルに学習可能な低ランク行列を注入して新たなタスクに適応させる、パラメータ効率的なファインチューニング手法である。LoRA の混合(Mixture-of-LoRAs)モデルは、各層の入力をその層に属する少数の専門化された LoRA のサブセットへルーティングすることで、ニューラルネットワークを効率的に拡張する。既存の LoRA 混合モデルにおけるルーティング器は、各 LoRA に学習済みのルーティング重みを割り当てることで、ルーティング器のエンドツーエンド学習を可能にしている。しかし、実用上はこれらのルーティング重みが LoRA 間で極めて不均衡になりがちであり、しばしば 1 つまたは 2 つの LoRA のみが重みを支配している。この現象は事実上、有効に機能する LoRA の数を制限し、既存の LoRA 混合モデルの表現能力を著しく阻害する。本研究では、この課題の根源を学習可能なルーティング重みの本質に求め、ルーティング器の基本的な設計を再考する。この重要な課題に対処するため、我々は「LoRA 混合のための強化学習ベースのルーティング(Reinforcement Routing for Mixture-of-LoRAs: ReMix)」と名付けた新たなルーティング器を提案する。その核心となるアイデアは、学習不可能なルーティング重みを用いることで、アクティブなすべての LoRA が均等に機能し、どの LoRA も重みを支配しないようにすることである。ただし、学習不可能な重みを用いるため、従来の勾配降下法ではルーティング器を直接学習できない。そこで我々は、強化学習において監督損失を報酬、ルーティング器を方策と見なす「レインフォース・リーブ・ワン・アウト(RLOO)」手法を採用し、ルーティング器のための不偏勾配推定量を新たに提案する。本勾配推定量により、学習計算規模を拡大して ReMix の予測性能を向上させることが可能となる。広範な実験により、本手法が同程度の活性化パラメータ数において、最先端のパラメータ効率的ファインチューニング手法を大幅に上回ることを実証した。
One-sentence Summary
Researchers from the University of Illinois Urbana-Champaign and Meta AI propose ReMix, a novel Mixture-of-LoRAs framework that replaces learnable routing weights with non-learnable ones to prevent router collapse. By employing an unbiased gradient estimator and RLOO technique, ReMix ensures all active adapters contribute equally, significantly outperforming existing parameter-efficient finetuning methods.
Key Contributions
- Existing Mixture-of-LoRAs models suffer from routing weight collapse where learned weights often concentrate on a single adapter, effectively wasting the computation of other activated LoRAs and limiting the model's expressive power.
- The authors propose ReMix, a novel router design that enforces constant non-learnable weights across all active LoRAs to ensure equal contribution and prevent any single adapter from dominating the routing process.
- To enable training with these non-differentiable weights, the paper introduces an unbiased gradient estimator using the reinforce leave-one-out technique, which allows ReMix to significantly outperform state-of-the-art methods across diverse benchmarks under strict parameter budgets.
Introduction
Low-rank adapters (LoRAs) enable efficient fine-tuning of large language models by injecting trainable matrices into frozen weights, while Mixture-of-LoRAs architectures aim to further boost capacity by routing inputs to specialized subsets of these adapters. However, existing approaches that rely on learned routing weights suffer from a critical flaw where weights collapse to a single dominant LoRA, effectively wasting the computational resources of the other active adapters and limiting the model's expressive power. To resolve this, the authors introduce ReMix, a reinforcement routing framework that enforces equal contribution from all active LoRAs by using non-learnable constant weights and training the router via an unbiased gradient estimator based on the REINFORCE leave-one-out technique.
Method
The authors propose ReMix, a reinforcement routing method for Mixture-of-LoRAs designed to mitigate routing weight collapse. The method fundamentally alters the adapter architecture and training procedure to ensure diverse LoRA utilization.
In the adapter architecture, the router computes a categorical distribution q(l) over the available LoRAs for a given layer input. Instead of using these probabilities as continuous weights, the model selects a subset of k LoRAs. Crucially, the routing weights for these activated LoRAs are set to a constant value ω, while non-activated LoRAs receive zero weight. This design guarantees that the effective support size remains fixed at k, preventing the router from concentrating probability mass on a single LoRA. The layer output is then computed as the sum of the frozen model output and the weighted contributions of the selected LoRAs.
To train the router parameters, the authors address the non-differentiability of the discrete selection process by framing it as a reinforcement learning problem. The SFT loss serves as the negative reward signal. During finetuning, the model samples M distinct selections of LoRA subsets. For each selection, the SFT loss is calculated. These losses are then used to estimate the gradient for the router parameters via the RLOO gradient estimator. This estimator leverages the variance reduction technique of using the average loss across samples as a baseline. The gradient estimator is defined as: GP(l):=M−11∑m=1M(L(Jm)−L)∇P(l)logQ(Jm) where L represents the average SFT loss across the M selections.
As shown in the figure below, the framework visualizes the ReMix architecture where the router generates selection probabilities that guide the activation of specific LoRA pools across multiple layers. The process involves generating multiple selections, computing the SFT loss for each, and aggregating these signals through the RLOO gradient estimator to update the router.
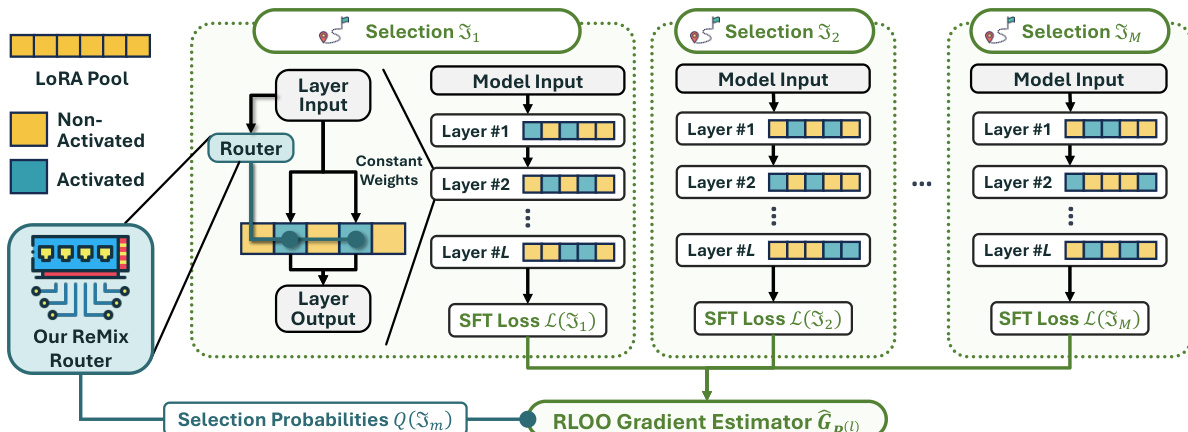
During inference, the authors employ a top-k selection strategy. Theoretical analysis shows that if the router is sufficiently trained, selecting the k LoRAs with the highest probabilities guarantees the optimal subset. This deterministic approach improves upon random sampling used during training.
Experiment
- Analysis of existing Mixture-of-LoRAs methods reveals a critical routing weight collapse where only one LoRA dominates per layer, severely limiting model expressivity and rendering other LoRAs ineffective.
- The proposed ReMix method consistently outperforms various baselines across mathematical reasoning, code generation, and knowledge recall tasks while maintaining superior parameter efficiency.
- Comparisons with single rank-kr LoRA demonstrate that ReMix successfully activates diverse LoRA subsets rather than relying on a fixed subset, validating its ability to leverage mixture capacity.
- Ablation studies confirm that both the RLOO training algorithm and top-k selection mechanism are essential components for achieving peak performance.
- Experiments show that ReMix benefits from scaling the number of activated LoRAs and increasing training compute via sampled selections, unlike deterministic baselines which cannot utilize additional compute resources.
- The method exhibits robustness to different routing weight initialization schemes, maintaining stable performance regardless of the specific weight configuration used.