Command Palette
Search for a command to run...
大規模言語モデルにおけるツール利用のためのコンテキスト内強化学習
大規模言語モデルにおけるツール利用のためのコンテキスト内強化学習
Yaoqi Ye Yiran Zhao Keyu Duan Zeyu Zheng Kenji Kawaguchi Cihang Xie Michael Qizhe Shieh
概要
大規模言語モデル(LLM)は優れた推論能力を示す一方で、複雑なタスクにおける性能は、その内部知識の限界によってしばしば制約を受ける。この課題を克服する有力なアプローチとして、数学的計算用の Python インタプリタや事実情報検索用の検索エンジンといった外部ツールをモデルに付与することが挙げられる。しかし、モデルがこれらのツールを効果的に利用できるようにすることは、依然として大きな課題である。既存の手法は、通常、教師あり微調整(SFT)に始まり、その後に強化学習(RL)を行うコールドスタート型パイプラインに依存している。これらのアプローチは SFT に多量のアノテーション済みデータを必要とし、その注釈付けや合成には多大なコストがかかる。本研究では、SFT を不要とし、RL のロールアウト段階においてファウショット・プロンプティングを活用することで、SFT を排除する RL のみのフレームワーク「インコンテキスト強化学習(In-Context Reinforcement Learning: ICRL)」を提案する。具体的には、ICRL はロールアウトプロンプト内にインコンテキスト例を導入し、モデルに外部ツールの呼び出し方法を学習させる。さらに、訓練が進むにつれてインコンテキスト例の数を段階的に削減し、最終的にはモデルが単独でツールを呼び出せるゼロショット設定に至るまで学習を進める。多様な推論およびツール利用ベンチマークにおいて大規模な実験を実施した結果、ICRL は最先端(state-of-the-art)の性能を達成し、従来の SFT ベースのパイプラインに対する、スケーラブルかつデータ効率的な代替手段としてその有効性を示した。
One-sentence Summary
Researchers from Yale, Stanford, and other institutions propose In-Context Reinforcement Learning, a novel framework that enables large language models to autonomously refine tool-use strategies through dynamic context updates, significantly improving adaptability and performance in complex multi-step reasoning tasks without requiring extensive fine-tuning.
Key Contributions
- Large language models often struggle with complex tasks due to limited internal knowledge, and existing tool-use training methods rely on expensive supervised fine-tuning to provide initial guidance.
- This work introduces In-Context Reinforcement Learning, an RL-only framework that uses few-shot prompting during rollouts to teach tool invocation without any supervised fine-tuning.
- Experiments on benchmarks like TriviaQA and AIME2024 show that this approach achieves state-of-the-art performance with significant accuracy gains over strong baselines while eliminating the need for costly labeled data.
Introduction
Large language models often struggle with complex tasks due to their reliance on static pretraining knowledge, making the integration of external tools like code interpreters and search engines essential for real-world applications. Current methods typically depend on a cold-start pipeline that combines supervised fine-tuning with reinforcement learning, a process that demands expensive and labor-intensive labeled data to teach models how to invoke tools effectively. The authors introduce In-Context Reinforcement Learning, an RL-only framework that eliminates the need for supervised fine-tuning by embedding few-shot demonstrations directly into the rollout prompts. This approach uses a curriculum that gradually reduces these examples to guide the model from imitation to autonomous tool use, achieving state-of-the-art performance while significantly improving data efficiency.
Method
The authors formalize tool use in Large Language Models (LLMs) as a Markov Decision Process (MDP). Given a query q and an external tool T, the model generates a response y where each token is conditioned on the query, previous tokens, and a history of interactions Ht. This interaction history includes the model's actions, such as internal reasoning, issuing search queries, or providing a final answer, as well as the observations returned by the tool. The conditional distribution is defined as:
πθ(y∣q,T)=t=1∏∣y∣πθ(yt∣y<t,q,Ht)To optimize this policy, the authors employ a reinforcement learning objective that maximizes the expected reward while constraining the divergence from a reference model πref. They specifically adopt Group Relative Policy Optimization (GRPO) to train the policy πθ. A critical component of this training is a loss masking strategy. Since the rollout sequence includes retrieved content from external tools which the model did not generate, these tokens are excluded from the loss computation. This ensures that the policy gradient updates focus solely on the model's own decisions, such as tool invocation and reasoning steps, rather than the fixed content retrieved by the tool.
The core innovation of the proposed method, In-Context Reinforcement Learning (ICRL), lies in its training curriculum. Rather than training from scratch or relying solely on static few-shot prompting, ICRL integrates the inductive bias of few-shot learning with the exploration capabilities of RL. The process begins by incorporating a small number of tool-use demonstrations into the rollout template to guide the model. As training progresses and the model acquires tool-use capabilities, the number of demonstration examples in the prompt is iteratively reduced. This transition allows the model to move from imitation to autonomous tool use.
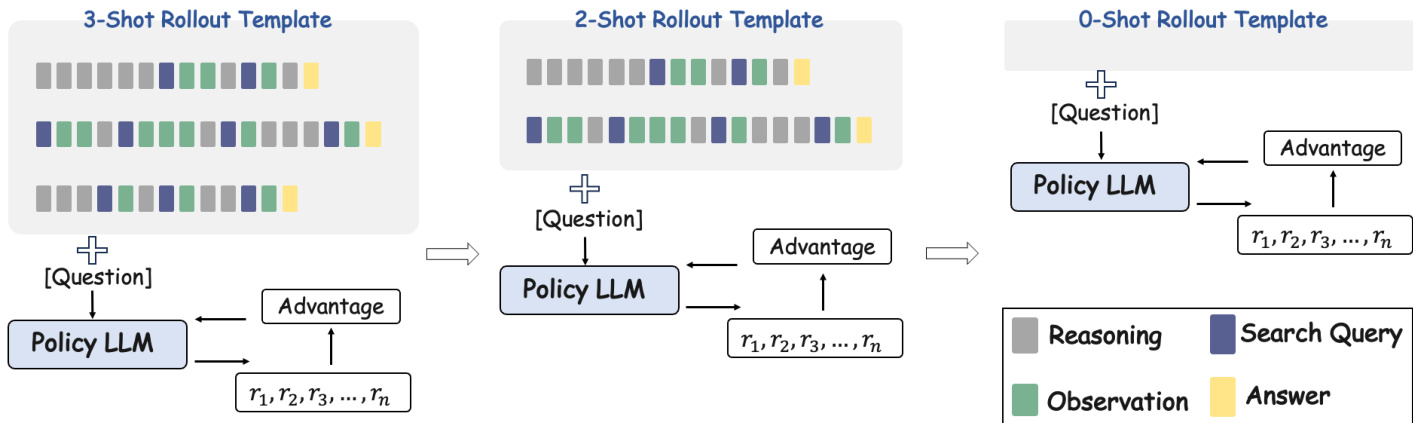
To provide a robust learning signal during this process, the authors design a composite reward function that combines answer accuracy and format correctness. The accuracy reward is based on exact match with the ground truth, while the format reward penalizes violations of the expected structured output, such as incorrect XML tags. The total reward is a weighted sum of these two components, guiding the model to produce both correct answers and valid tool-use sequences.
Experiment
- Main experiments compare ICRL against direct prompting, retrieval-based, and fine-tuning baselines across diverse QA benchmarks, validating that ICRL achieves state-of-the-art performance in complex reasoning and multi-hop tasks without requiring supervised fine-tuning or labeled tool traces.
- Ablation studies on curriculum design demonstrate that a simpler three-stage rollout schedule yields superior accuracy compared to aggressive reduction strategies, which cause premature stopping and weaken multi-turn reasoning capabilities.
- Scaling experiments confirm that ICRL effectively leverages larger model capacities, with the 14B variant significantly outperforming prompting and chain-of-thought methods while maintaining data efficiency.
- Generalization tests on code-writing and math problem-solving tasks show that ICRL successfully transfers to new tool domains, offering a more data-efficient alternative to methods relying on costly cold-start supervised fine-tuning.
- Training process analysis reveals that the model learns to internalize structured tool-use behaviors and increase valid tool calls over time, even when trained solely on sparse rewards for format validity and final answer accuracy.