HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

人間とLLMの研究アイデアのギャップの測定

ハーネス効果:オーケストレーション設計がエンタープライズエージェントAIのトークン経済を決定する仕組み

























人間とLLMの研究アイデアのギャップの測定
ハーネス効果:オーケストレーション設計がエンタープライズエージェントAIのトークン経済を決定する仕組み
多様なインタラクションを備えた無限の世界
身体性知能のためのMixture-of-Expertsビデオ事前学習のスケーリング
LAME M-VLA: ロボット操作のための視覚-言語-行動モデルにおける二重潜在記憶
深層ネイティブ構造推論による高精度・学際的・透明性の高い構造-物性理解
全モーダル密なビデオキャプションのための並列自己回帰デコーディング
Light-Omni: 長期記憶を用いたエージェント型映像理解における推論より反射
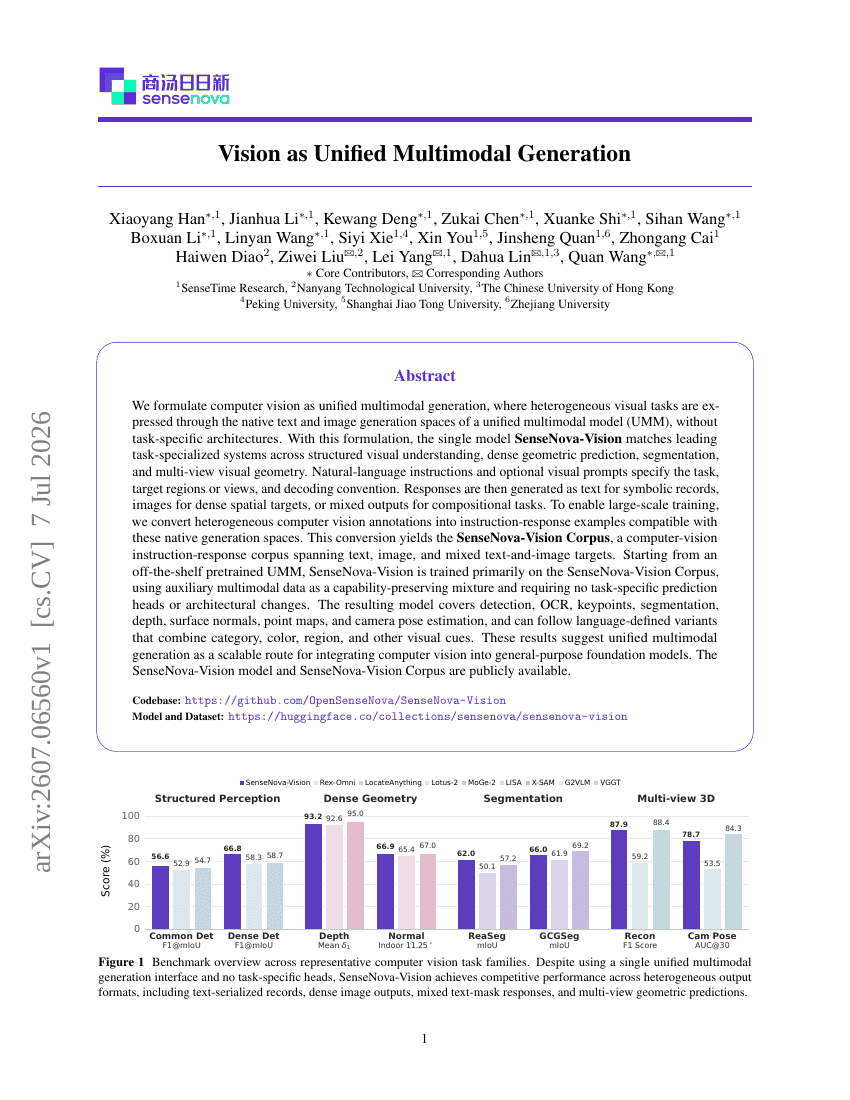
統一マルチモーダル生成としての視覚
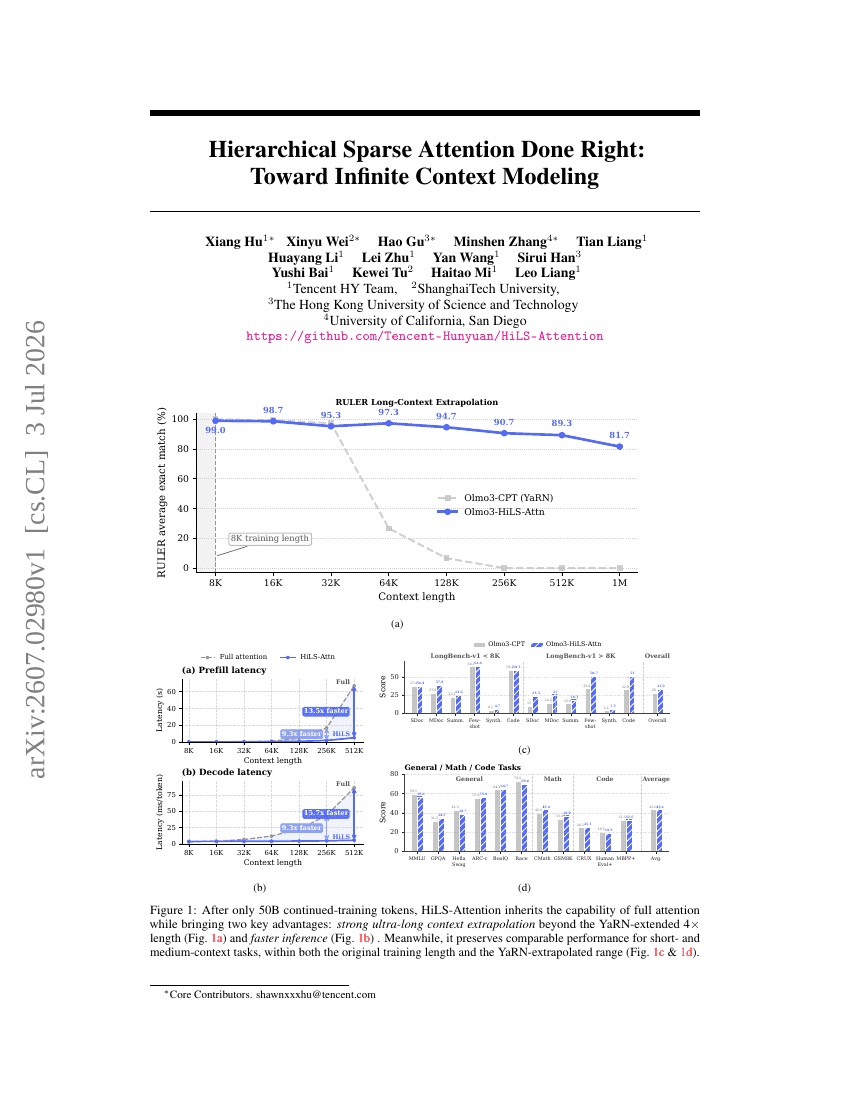
階層的スパースアテンションの正しい実現:無限コンテキストモデリングに向けて
AlayaWorld: 長期的かつプレイ可能なビデオワールド生成
RynnWorld-4D: ロボット操作のための4D具現化世界モデル
Nemotron-Labs-3-Puzzle-75B-A9B: ハイブリッドMoE LLMの圧縮
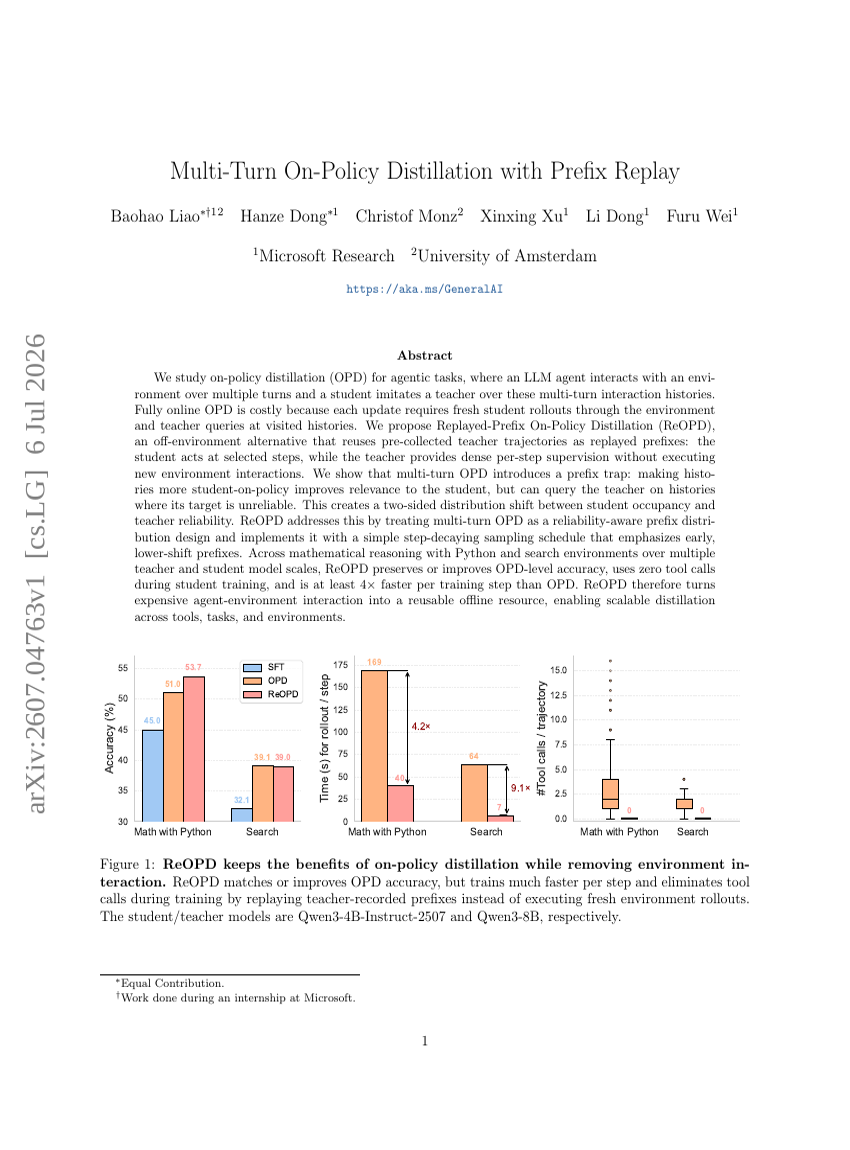
プレフィックスリプレイを用いたマルチターンオンポリシー蒸留
Gemma 4 技術報告書
UI-MOPD: GUIエージェントの継続学習のためのマルチプラットフォーム・オンポリシー蒸留
Wan-Streamer v0.2: 高解像度化と同一レイテンシの両立
EVA-Client: 実ロボットにおける展開、評価、データ収集のための統一フレームワーク
GigaWorld-1: ロボットポリシー評価のためのワールドモデル構築へのロードマップ
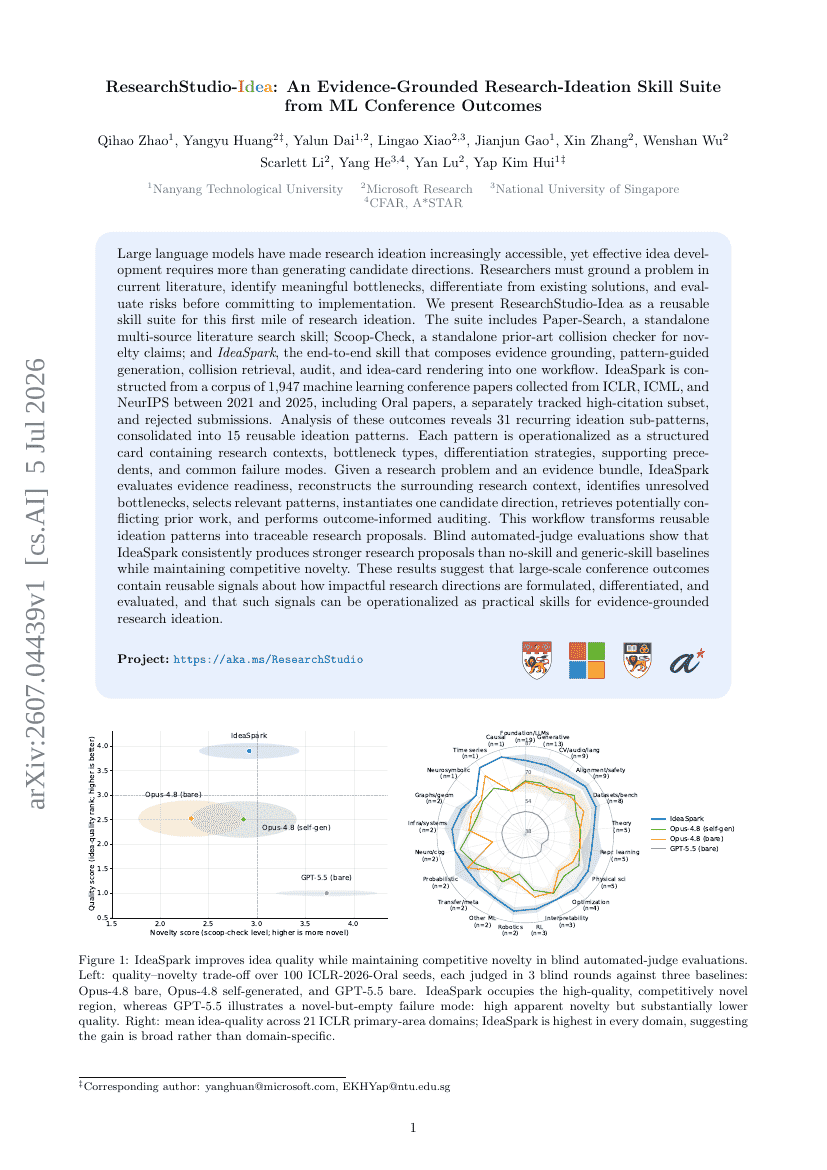
ResearchStudio-Idea: 機械学習会議の採択結果に基づくエビデンス重視の研究発想スキル群
ResearchStudio-Reel: 論文からポスター、動画、ブログへの研究発信のラストワンマイルを自動化する
FINAL Bench: 大規模言語モデルにおける機能的メタ認知推論の測定
SceneFun3D: 3Dシーンにおける詳細な機能性とアフォーダンス理解
TheoremGraph: 形式数学と非形式数学の橋渡し
常時稼働エージェント:LLMエージェントにおける永続的記憶、状態、ガバナンスに関するサーベイ
AIエージェントのセキュリティ確保:多層エージェントレッドチーミングのための統一フレームワーク
DataComp-VLM: 視覚言語モデルのための改善されたオープンデータセット
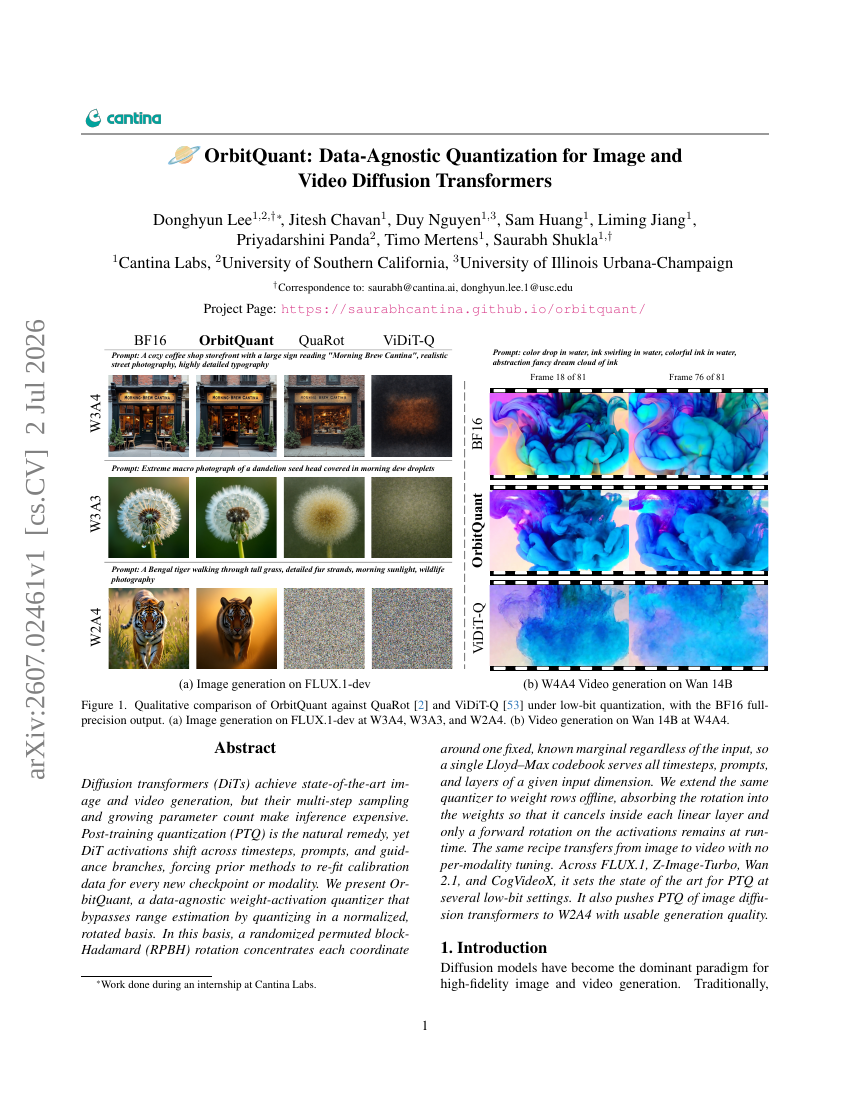
OrbitQuant: 画像・動画拡散変換器のためのデータ非依存型量子化
VLA-Corrector: 適応的行動ホライズンのための軽量な検出・修正推論
Embodied.cpp: 異種ロボットにおけるEmbodied AIモデルの可搬型推論ランタイム
訓練方針最適化の幻影:大規模言語モデル強化学習における真の目的としての単調推論方針
GeneBench-Pro:ゲノミクス、定量生物学、トランスレーショナルバイオメディシンにおける多段階統計推論の評価
多様なインタラクションを備えた無限の世界
身体性知能のためのMixture-of-Expertsビデオ事前学習のスケーリング
LAME M-VLA: ロボット操作のための視覚-言語-行動モデルにおける二重潜在記憶
深層ネイティブ構造推論による高精度・学際的・透明性の高い構造-物性理解
全モーダル密なビデオキャプションのための並列自己回帰デコーディング
Light-Omni: 長期記憶を用いたエージェント型映像理解における推論より反射
統一マルチモーダル生成としての視覚
階層的スパースアテンションの正しい実現:無限コンテキストモデリングに向けて
AlayaWorld: 長期的かつプレイ可能なビデオワールド生成
RynnWorld-4D: ロボット操作のための4D具現化世界モデル
Nemotron-Labs-3-Puzzle-75B-A9B: ハイブリッドMoE LLMの圧縮
プレフィックスリプレイを用いたマルチターンオンポリシー蒸留
Gemma 4 技術報告書
UI-MOPD: GUIエージェントの継続学習のためのマルチプラットフォーム・オンポリシー蒸留
Wan-Streamer v0.2: 高解像度化と同一レイテンシの両立
EVA-Client: 実ロボットにおける展開、評価、データ収集のための統一フレームワーク
GigaWorld-1: ロボットポリシー評価のためのワールドモデル構築へのロードマップ
ResearchStudio-Idea: 機械学習会議の採択結果に基づくエビデンス重視の研究発想スキル群
ResearchStudio-Reel: 論文からポスター、動画、ブログへの研究発信のラストワンマイルを自動化する
FINAL Bench: 大規模言語モデルにおける機能的メタ認知推論の測定
SceneFun3D: 3Dシーンにおける詳細な機能性とアフォーダンス理解
TheoremGraph: 形式数学と非形式数学の橋渡し
常時稼働エージェント:LLMエージェントにおける永続的記憶、状態、ガバナンスに関するサーベイ
AIエージェントのセキュリティ確保:多層エージェントレッドチーミングのための統一フレームワーク
DataComp-VLM: 視覚言語モデルのための改善されたオープンデータセット
OrbitQuant: 画像・動画拡散変換器のためのデータ非依存型量子化
VLA-Corrector: 適応的行動ホライズンのための軽量な検出・修正推論
Embodied.cpp: 異種ロボットにおけるEmbodied AIモデルの可搬型推論ランタイム
訓練方針最適化の幻影:大規模言語モデル強化学習における真の目的としての単調推論方針
GeneBench-Pro:ゲノミクス、定量生物学、トランスレーショナルバイオメディシンにおける多段階統計推論の評価