Command Palette
Search for a command to run...
Make It Up:一般化された少数ショット意味セグメンテーションにおける偽造画像による実質的な性能向上
Make It Up:一般化された少数ショット意味セグメンテーションにおける偽造画像による実質的な性能向上
Guohuan Xie Xin He Dingying Fan Le Zhang Ming-Ming Cheng Yun Liu
概要
一般化少 shots セマンティックセグメンテーション(GFSS)は、注釈が乏しい状況下における新規クラスの出現範囲の不足によって本質的に制約を受けている。拡散モデルを用いれば新規クラスの画像を大規模に合成できるが、マスクが利用できない、あるいは信頼性が低い場合には、不十分なカバレッジとノイズの多い教師信号により、実用的な性能向上が阻害されることが多い。本研究では、新規クラスのカバレッジを拡大しつつ疑似ラベルの品質を向上させる、生成強化型の GFSS フレームワーク「Syn4Seg」を提案する。Syn4Seg はまず、各新規クラスに対して埋め込み空間における重複を除去したプロンプトバンクを構築することでプロンプト空間のカバレッジを最大化し、多様でありながらクラス一貫性を保つ合成画像を生成する。次に、サポート guided な疑似ラベル推定を二段階の精緻化により実行する。第一段階では低一貫性領域をフィルタリングして高精度なシードを取得し、第二段階では、グローバル(サポート)統計量とローカル(画像)統計量を統合した画像適応型プロトタイプを用いて不確実なピクセルを再ラベルする。最後に、高信頼性の内部領域を書き換えることなく輪郭忠実度を向上させるため、境界帯および未ラベルピクセルのみを制約付き SAM ベースの更新により精緻化する。PASCAL-5i および COCO-20i における広範な実験により、1-shot および 5-shot の設定の両方で一貫した性能向上が確認され、信頼性の高いマスクと精密な境界を備えた合成データが、GFSS にとってスケーラブルな解決策となり得ることが示された。
One-sentence Summary
Researchers from Nankai University and Tianjin University of Technology propose Syn4Seg, a framework that leverages Stable Diffusion to generate diverse novel-class images and employs support-guided pseudo-label refinement with SAM-based boundary correction, significantly enhancing Generalized Few-shot Semantic Segmentation performance on PASCAL-5i and COCO-20i benchmarks.
Key Contributions
- The paper introduces Syn4Seg, a generation-enhanced framework that constructs an embedding-deduplicated prompt bank to synthesize diverse, class-consistent novel-class images, thereby expanding coverage and improving generalization in Generalized Few-shot Semantic Segmentation.
- An Adaptive Pseudo-label Enhancement mechanism is presented to refine synthetic masks through a two-stage process that filters low-consistency regions and relabels uncertain pixels using image-adaptive prototypes, resulting in higher-quality supervision.
- A SAM-based Boundary Refinement module is developed to update only boundary-band and unlabeled pixels, which produces sharp, spatially coherent contours and boosts segmentation performance as demonstrated by consistent improvements on PASCAL-5i and COCO-20i benchmarks.
Introduction
Generalized few-shot semantic segmentation (GFSS) aims to segment both base and novel classes in a single inference pass, a capability critical for scalable deployment where pixel-level annotations are scarce. However, prior approaches struggle because novel classes rely on limited manual support examples, leading to poor intra-class diversity and weak generalization, while existing attempts to use Diffusion models for data augmentation often suffer from redundant image generation and noisy or misaligned segmentation masks. To overcome these hurdles, the authors propose Syn4Seg, a framework that constructs an embedding-deduplicated prompt bank to ensure diverse and class-consistent synthetic images, followed by a two-stage pseudo-label refinement process and a SAM-based boundary update to deliver high-quality supervision for robust segmentation.
Method
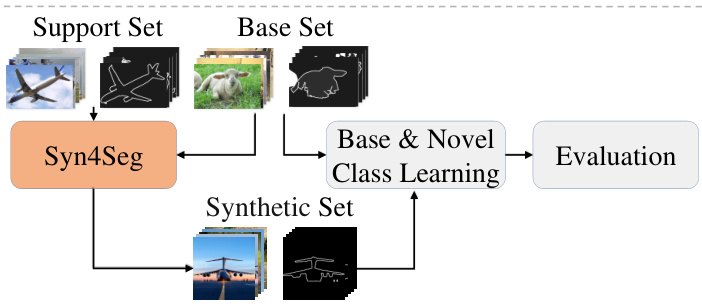
The authors propose the Syn4Seg framework to alleviate the shortage of novel class images in Generalized Few-Shot Segmentation (GFSS). The overall pipeline is illustrated in the framework diagram. The process begins with a Support Set and a Base Set. The Syn4Seg module synthesizes a Synthetic Set of novel class images. These synthetic images, along with the Base Set, are fed into a Base & Novel Class Learning module to train the final segmentation model, which is then evaluated.
To generate the synthetic images, the authors leverage High-quality Diverse Image Generation (HDIG). Direct use of class names often leads to limited diversity. HDIG addresses this by constructing a prompt set that is centered on the target class but semantically diverse. An iterative prompt generation strategy is employed where an agent generates candidate prompts. These prompts are encoded using the text encoder of Stable Diffusion 3.5-Large to ensure semantic alignment. A diversity threshold is applied to filter prompts based on cosine similarity. The maximum cosine similarity between the current candidate and existing entries is computed as: st,i=maxu∈Dt(i−1)φ~(pt,i)⊤u where φ~(p) is the normalized text embedding. A candidate prompt is accepted only if its similarity score is below a threshold λ, ensuring sufficient diversity. The accepted prompts are used to synthesize images. A qualitative comparison highlights the effectiveness of this approach, showing that HDIG produces images with substantially richer visual diversity while preserving class consistency compared to standard class-name prompts.
Once synthetic images are generated, the authors employ Adaptive Pseudo-label Enhancement (APE) to produce high-quality masks, as the initial masks from the GFSS network are often noisy. Refer to the detailed module diagram for the internal structure of APE. APE comprises two stages: Adaptive Pseudo-label Filtering (APF) and Adaptive Pseudo-label Relabeling (APR). In the APF stage, the method discards unreliable pseudo-labels by assessing the alignment between predicted regions and support prototypes. The prototype for novel class k is computed by averaging features over pixels labeled as k: μk=∑j∑p1[Mj(p)=k]1∑j∑p1[Mj(p)=k]fj(p) For a region r, the cosine similarity with the class prototype is calculated as s(r)=v^(r)⊤μ^k. If s(r)≥λ, the region is kept; otherwise, it is marked as free. In the APR stage, these free regions are adaptively relabeled using a blend of global support prototypes and image-local prototypes. The adaptive prototype for image x is given by: μ~k(x)=βμ^k+(1−β)μ^k(x) where β controls the influence of the global prototype. This ensures that the mask retains trustworthy labels while filling in uncertain areas with high-confidence predictions.
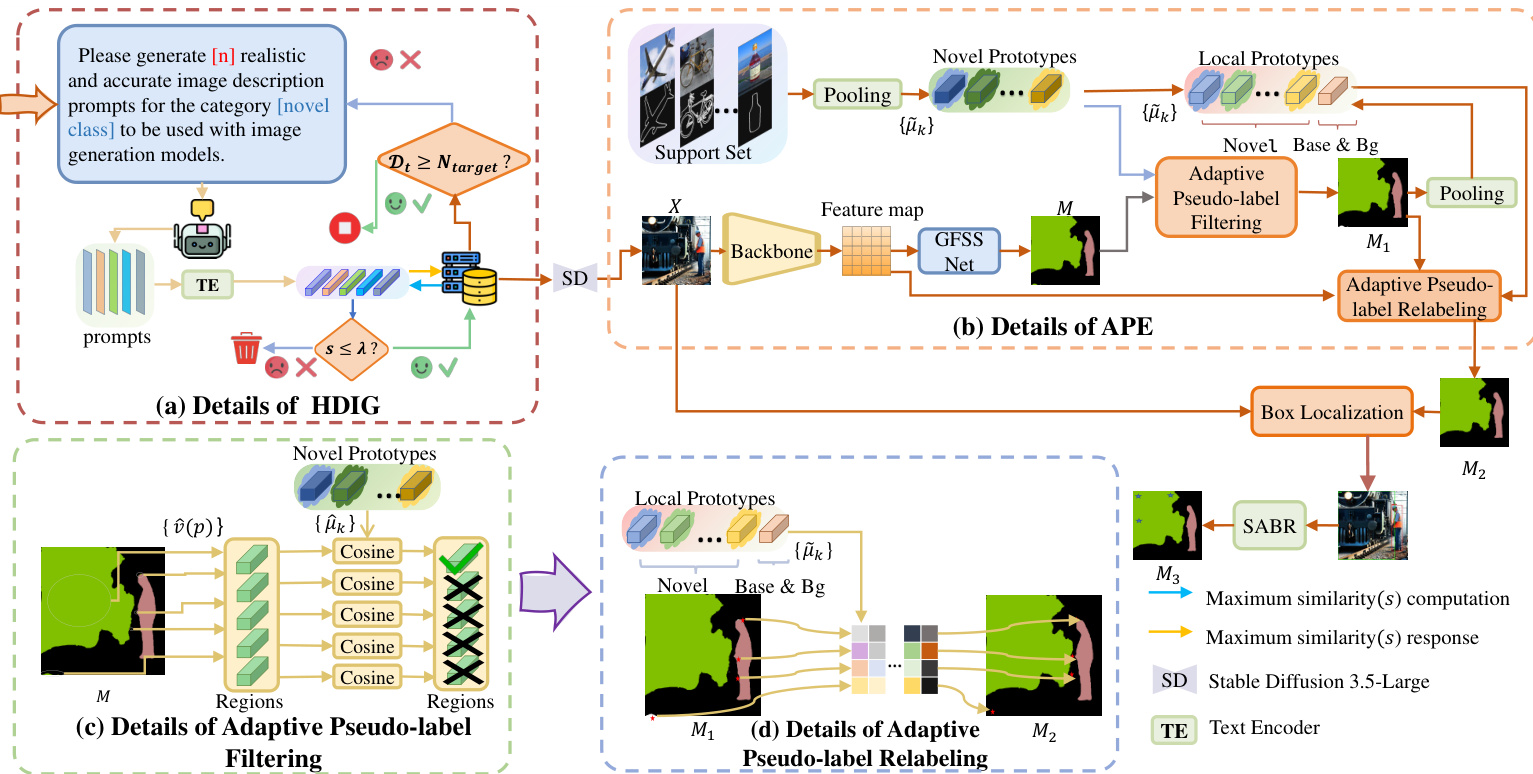
Finally, to address imprecise object boundaries, the authors apply SAM-based Boundary Refinement (SABR). This module utilizes the Segment Anything Model (SAM) to refine the mask boundaries. By identifying boundary pixels and computing tight bounding boxes, SAM is guided to produce binary foreground predictions. Updates are restricted to uncertain regions to prevent overwriting high-confidence interiors. This process yields the final training mask with substantially improved boundary fidelity, ready for downstream segmentation training.
Experiment
- Experiments on PASCAL-5i and COCO-20i benchmarks validate that the proposed Syn4Seg method significantly outperforms state-of-the-art approaches in both 1-shot and 5-shot settings, achieving superior mean and harmonic mIoU scores.
- Qualitative analysis demonstrates that the method generates more coherent and complete segmentation masks for novel classes while reducing fragmented predictions and spurious regions compared to existing techniques.
- Ablation studies confirm that enhancing image diversity through HDIG provides broader appearance cues, while the APE module improves mask precision by filtering misaligned regions and relabeling ambiguous areas.
- The inclusion of SABR effectively refines object boundaries and resolves local ambiguities, leading to the best overall segmentation consistency across base and novel classes.
- Hyperparameter analysis reveals that moderate values for prototype blending and thresholding optimize the balance between synthesized information and generalization, while the method remains robust to variations in boundary refinement parameters.
- Testing with a deeper ResNet-101 backbone shows consistent performance gains, indicating that stronger feature extraction benefits fine-grained detail capture without the method being overly dependent on backbone depth.