Command Palette
Search for a command to run...
LightMover: 色と強度の制御を備えた生成光移動
LightMover: 色と強度の制御を備えた生成光移動
Gengze Zhou Tianyu Wang Soo Ye Kim Zhixin Shu Xin Yu Yannick Hold-Geoffroy Sumit Chaturvedi Qi Wu Zhe Lin Scott Cohen
概要
本稿では、単一画像における制御可能な光操作を可能にするフレームワーク「LightMover」を提案する。本手法はビデオ拡散モデルの事前知識を活用し、シーンの再描画を伴わずに物理的に妥当な照明変化を生成する。光編集を視覚トークン空間における系列から系列への予測問題として定式化し、入力画像と光制御トークンを条件として、単一の視点から光の位置・色・強度ならびにそれに伴う反射、影、減衰を同時に調整する。空間的制御(移動)と外観的制御(色・強度)を統一的に扱う本アプローチは、操作精度と照明理解の両方を向上させる。さらに、空間的に情報豊富なトークンを保持しつつ非空間的属性をコンパクトに符号化する適応的トークンプルーニング機構を導入し、制御系列長を41%削減しながら編集忠実度を維持する。本フレームワークの訓練には、シーン内容を原画像と一貫させつつ、多様な光の位置・色・強度にわたる大規模な画像ペアを生成可能なスケーラブルなレンダリングパイプラインを構築した。LightMover は、光の位置・色・強度に対する精密かつ独立した制御を実現し、異なるタスクにおいて高い PSNR と強力なセマンティック整合性(DINO、CLIP)を達成する。
One-sentence Summary
Researchers from Adelaide University, Adobe Research, and other institutions present LightMover, a framework leveraging video diffusion priors to enable physically plausible light manipulation in single images. By formulating editing as sequence-to-sequence prediction with adaptive token pruning, it achieves precise control over position, color, and intensity without scene re-rendering.
Key Contributions
- The paper introduces LightMover, a unified diffusion-based framework that formulates light editing as a sequence-to-sequence prediction problem to enable precise, independent control over light position, color, and intensity while generating physically plausible reflections and shadows.
- An adaptive token-pruning mechanism is proposed to compactly encode non-spatial attributes like color and intensity while preserving fine-grained spatial tokens, which reduces the control sequence length by 41% without compromising editing fidelity.
- A scalable physically-based rendering pipeline is developed to generate large-scale training data with varied illumination conditions, supporting a multi-task training strategy that achieves state-of-the-art performance in PSNR and semantic consistency across light manipulation tasks.
Introduction
Designing realistic lighting in a single image is critical for applications like virtual staging, yet existing methods struggle to provide precise control. Inverse-rendering pipelines are computationally expensive and ill-posed from a single view, while current Diffusion-based editors lack explicit spatial light movement or fail to propagate correct shadows and reflections. The authors introduce LightMover, a video-Diffusion framework that treats light manipulation as a sequence-to-sequence task to enable parametric control over position, color, and intensity. They leverage a novel adaptive token-pruning strategy to efficiently encode non-spatial attributes without inflating sequence length and utilize a scalable physically-based rendering pipeline to train the model on causal illumination effects.
Dataset
-
Dataset Composition and Sources: The authors combine a synthetic dataset generated via a Blender-based pipeline with a real-world dataset captured using mobile devices. The synthetic portion relies on 25 artist-designed indoor environments and 100 light source assets from Objectverse-XL, while the real portion consists of 106 indoor scenes photographed with synchronized triggering equipment.
-
Key Details for Each Subset:
- Synthetic Data: Generates approximately 32,000 data pairs by varying fixture placements, HDRI maps, and ambient-to-direct light ratios. Each scene features a light source animated along a smooth trajectory captured by ten virtual cameras to form multi-view motion pairs.
- Real Data: Contains 360 high-resolution photographs across 106 scenes, with each scene offering 3 to 4 lighting variations. This subset also includes background reference images where the light source is physically removed to support light insertion and removal tasks.
-
Model Usage and Training Strategy: The synthetic data provides scalable supervision for learning visual realism and physical consistency across light movement, color, and intensity. During training, the model applies additional post-processing perturbations to light intensity, hue, and ambient tone to create effectively unbounded variations. The real data complements this by offering ground truth for light movement and enabling specific objectives for light manipulation tasks.
-
Processing and Metadata Construction: The rendering pipeline decomposes each frame into two physically disentangled components: an ambient base image and a direct light contribution. These are rendered independently using Monte Carlo path-tracing and composited in linear RGB space. For the real dataset, the authors ensure physical consistency by capturing pairs where the only variable is the light source location, while the background images serve as metadata for removal and insertion objectives.
Method
The authors propose LightMover, a framework that repurposes a pre-trained video diffusion Transformer to handle light manipulation as a sequence-to-sequence prediction problem. The model treats various input conditions as pseudo video frames arranged sequentially, which are encoded by a VAE into latent tokens and jointly processed by the diffusion Transformer. As illustrated in the framework diagram, the input sequence consists of six distinct components: the Reference Image (Iref), an Object Frame (Iobj) containing the cropped target object, a Movement Map (Imove) encoding source and target bounding boxes, optional Color Control (Icolor), optional Intensity Control (Iintensity), and the noisy Output Frame (Xt). The Movement Map specifically utilizes RGB channels to denote the source region in Red and the target region in Green and Blue channels. Intensity control is quantified in photographic stops, where the illumination gain Gillum is calculated as Gillum=2SEV, with SEV representing the exposure adjustment.
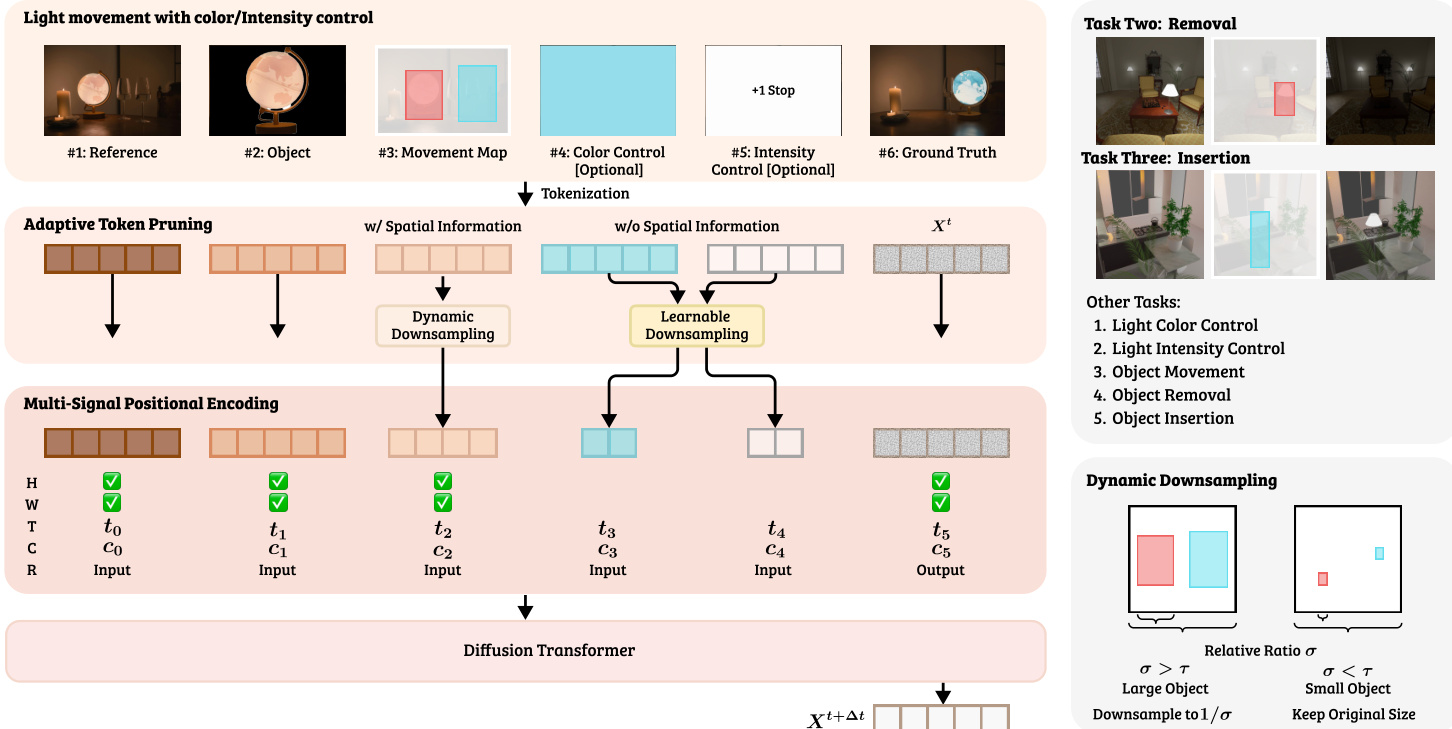
To ensure the Transformer correctly interprets these diverse inputs, the authors introduce a Multi-Signal Positional Encoding (MSPE) mechanism. This extends standard rotary positional embeddings by integrating four orthogonal subspaces: Spatial Encoding (W,H) for patch coordinates, Temporal Encoding (T) for sequence order, Condition-Type Encoding (C) to distinguish modalities, and Frame-Role Encoding (R) to separate inputs from the output. These components are projected and combined to enable joint reasoning over spatial alignment and condition interdependence.
To improve computational efficiency while maintaining generation fidelity, the authors employ an Adaptive Token Pruning mechanism. This module dynamically adjusts the number of latent tokens for each condition based on its spatial properties. For control signals with explicit spatial information, such as the Movement Map, a Spatially-Aware Pruning strategy downsamples tokens proportionally to the bounding box area ratio if the object is large. For non-spatial control frames like color and intensity, Learnable Downsampling is used, where the number of retained tokens is optimized jointly with the diffusion model. This approach reduces the average control sequence length by 41% without compromising generation quality.
For training, the authors construct a scalable rendering pipeline to generate large-scale synthetic data that combines real captured data with systematic variations of lighting parameters. As shown in the figure below, this pipeline generates image pairs across varied light positions, colors, and intensities while keeping the scene content consistent. The relighting process is modeled parametrically, combining ambient and light components according to the formula Irelit=αIamb+GillumIlight⊙ct. The model is trained using a flow-matching objective, where noisy inputs are generated by linear interpolation and the model predicts the instantaneous velocity to minimize the loss L=Et,X0,X1[∥v(St,t;θ)[6]−Vt∥2].

Experiment
- LightMover is evaluated on real-world and synthetic benchmarks to validate its ability to perform precise light movement, insertion, and removal while maintaining physical plausibility.
- Comparisons against LLM-powered text-to-image models and object movement baselines demonstrate that LightMover achieves superior localization accuracy and better handles complex global illumination effects like shadows, reflections, and material-specific shading.
- The model shows strong generalization to joint control tasks involving simultaneous movement, color, and intensity changes, outperforming baselines in both single-attribute and multi-attribute scenarios.
- Ablation studies confirm that co-training with diverse synthetic tasks and using physically disentangled rendering augmentation are critical for disentangling light sources and learning global light composition.
- Experiments on token pruning strategies reveal that frame-based conditioning combined with adaptive downsampling is essential for balancing efficiency with the precision required for complex multi-attribute illumination control.
- Qualitative analysis verifies that the model accurately reproduces ground-truth shadow geometry, specular highlights, and reflection consistency without introducing visual artifacts.