Command Palette
Search for a command to run...
二次勾配:ヘッシアンと勾配の統合による勾配降下法とニュートン型手法の架け橋となる統一フレームワーク
二次勾配:ヘッシアンと勾配の統合による勾配降下法とニュートン型手法の架け橋となる統一フレームワーク
John Chiang
概要
第二階最適化、特にニュートン型手法の収束加速は、アルゴリズム研究における重要な課題のままである。本論文では、以前の研究で提案されたQuadratic Gradient (QG)を拡張し、その一般凸数値最適化問題への適用性を厳密に検証する。我々は、従来の固定ヘッシアンニュートン枠組みから逸脱する、Quadratic Gradient の新たな変種を導入する。具体的には、新しいバージョンの Quadratic Gradient を構築する新たな手法を提示する。この新しい Quadratic Gradient は、固定ヘッシアンニュートン法の収束条件を満たさない。しかし、実験結果によれば、収束速度の観点において、元の手法よりも優れた性能を示す場合がある。この変種はいくつかの古典的な収束制約を緩和する一方で、正定値なヘッシアンの代理を維持しており、収束速度において同等、あるいは場合によっては優れた実証的性能を発揮することを示す。さらに、元の QG および提案する変種の両方が、非凸最適化ランドスケープへも効果的に適用可能であることを実証する。本研究の主要な動機は、従来のスカラー学習率の限界にある。我々は、対角行列を用いることで、異質なレートで勾配要素をより効果的に加速できると主張する。我々の知見は、Quadratic Gradient を現代の最適化のための多用途かつ強力な枠組みとして確立するものである。加えて、Hessian-ベクトル積を通じてヘッシアン対角成分を効率的に推定するため、Hutchinson's Estimator を統合した。特筆すべきは、提案する Quadratic Gradient 変種が Deep Learning アーキテクチャに対して極めて効果的であり、標準的な適応オプティマイザーに対する堅牢な第二階の代替手段を提供することを示した点である。
One-sentence Summary
John Chiang proposes a novel Quadratic Gradient variant that replaces fixed Hessian Newton frameworks with a diagonal matrix approach to accelerate convergence in Deep Learning. By integrating Hutchinson's Estimator for efficient Hessian diagonal approximation, this method outperforms traditional scalar learning rates in non-convex optimization landscapes.
Key Contributions
- The paper introduces a novel variant of the Quadratic Gradient that departs from the fixed Hessian Newton framework by maintaining a positive-definite Hessian proxy, which allows for effective application to non-convex optimization landscapes where traditional methods often fail.
- This work integrates Hutchinson's Estimator to efficiently approximate the Hessian diagonal via Hessian-vector products, reducing the computational complexity of second-order information from O(n2) to O(n) and enabling scalability for Deep Learning architectures.
- Experimental results demonstrate that the proposed Quadratic Gradient variants achieve comparable or superior convergence rates compared to original methods and standard adaptive optimizers, validating their utility as a robust second-order alternative for general convex and non-convex problems.
Introduction
Modern numerical optimization struggles to balance the scalability of first-order methods like SGD with the rapid convergence of second-order approaches like Newton's method, as the former fails on ill-conditioned curvatures while the latter incurs prohibitive computational costs and sensitivity to Hessian indefiniteness. Prior work on the Quadratic Gradient (QG) has shown promise in specific tasks like logistic regression but often relies on fixed Hessian approximations that limit general applicability and theoretical convergence guarantees. The authors leverage a novel QG variant that synthesizes curvature information into a diagonal matrix to replace scalar learning rates, enabling dimension-wise acceleration without satisfying the strict constraints of traditional fixed Hessian Newton methods. By integrating Hutchinson's Estimator for efficient Hessian diagonal approximation, they establish a unified framework that extends to general convex and non-convex landscapes, offering a robust second-order alternative to standard adaptive optimizers in Deep Learning.
Dataset
The provided text only lists the titles "mnist" and "credi" under the section "Large-Scale Datasets" without offering any descriptive content. Consequently, it is not possible to draft a dataset description covering composition, sources, filtering rules, training splits, or processing strategies based on this input. No further details regarding dataset size, metadata construction, or model usage are available in the source material.
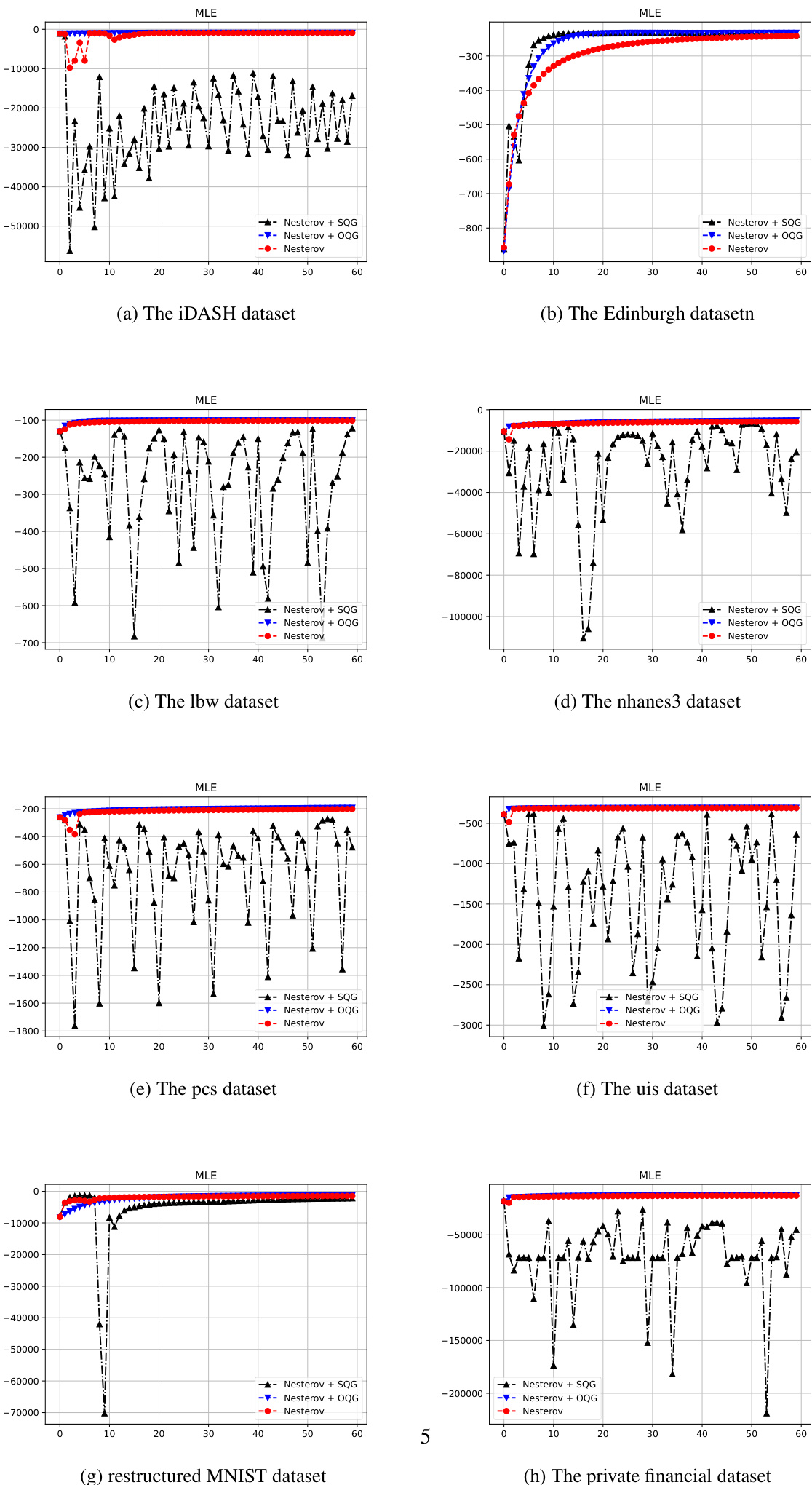
Experiment
- Logistic regression experiments on multiple datasets validate that the Simplified Quadratic Gradient (SQG) framework maintains high computational efficiency and convergence speed comparable to the original method while offering a more streamlined architecture, though it requires conservative learning rate decay for NAG to ensure stability.
- Deep learning tests on ResNet-18 demonstrate that the new QG variant achieves faster convergence than Adam and exhibits superior stability in non-convex regions compared to AdaHessian, with computational overhead comparable to second-order methods.
- Benchmark evaluations on convex and non-convex functions confirm the algorithm's ability to handle dimensional scaling and navigate ill-conditioned valleys effectively.
- Saddle point analysis reveals that the QG variant overcomes the stagnation typical of first-order methods by utilizing spectral information to assign large adaptive steps along directions of minimal curvature, allowing the optimizer to escape saddle points efficiently.
- Overall, the framework successfully bridges first and second-order optimization by integrating Hessian approximations to accelerate convergence and robustly manage complex topological features in high-dimensional spaces.