Command Palette
Search for a command to run...
LLM ベースのマルチトークヤースピーチ認識に向けた、ゲート付きクロスアテンションアダプタを用いた 2 段階音響適応手法
LLM ベースのマルチトークヤースピーチ認識に向けた、ゲート付きクロスアテンションアダプタを用いた 2 段階音響適応手法
Hao Shi Yuan Gao Xugang Lu Tatsuya Kawahara
概要
大規模言語モデル(LLM)は、2 話者自動音声認識(ASR)における直列化出力トレーニング(SOT)の強力なデコーダーとして機能するが、3 話者混合のような困難な条件下では性能が著しく低下する。その主な限界は、現在のシステムが投影されたプレフィックスを通じてのみ音響証拠を注入しており、これは損失を伴い、LLM の入力空間と完全に整合しないため、デコーディング過程で微細なグラウンディングが不十分となる点にある。この限界に対処することは、特に 3 話者混合に対する堅牢なマルチ話者 ASR の実現にとって不可欠である。本論文では、話者Awareな音響証拠をデコーダーに明示的に注入することで、LLM に基づくマルチ話者 ASR の性能向上を図る。まず、Connectionist Temporal Classification(CTC)に由来するプレフィックスプロンプティングを再検討し、音響コンテンツの量が増加する 3 つの変種を比較する。ここで用いる CTC 情報は、我々の先行研究で提案されたシリアライズド CTC により取得される。音響情報を豊富に含んだプロンプトは SOT のみのベースラインを上回る性能を示すが、プレフィックス条件付けのみのアプローチでは 3 話者混合に対して依然として不十分である。そこで我々は、軽量なゲート付き残差クロスアテンションアダプターを提案し、低ランク適応(LoRA)に基づく 2 段階の音響適応フレームワークを設計する。第 1 段階では、自己アテンションサブレイヤーの後にゲート付きクロスアテンションアダプターを挿入し、外部メモリとして音響埋め込みを安定して注入する。第 2 段階では、クロスアテンションアダプターと事前学習済み LLM の自己アテンション射影の両方を、パラメータ効率の高い LoRA を用いて微調整し、限られたデータ下でも大規模なバックボーンに対する堅牢性を向上させる。学習された更新は推論時にベース重みにマージされる。Libri2Mix および Libri3Mix におけるクリーンおよびノイズ条件下での実験により、一貫した性能向上が確認された。特に 3 話者設定において顕著な改善が得られた。
One-sentence Summary
Authors from IEEE-affiliated institutions propose a two-stage acoustic adaptation framework for LLM-based multi-talker ASR that injects talker-aware evidence via gated cross-attention adapters and LoRA refinement, significantly improving robustness in challenging three-talker mixtures where standard prefix prompting fails.
Key Contributions
- The paper introduces a systematic comparison of three Connectionist Temporal Classification (CTC)-derived prefix variants with increasing acoustic content to evaluate their effectiveness in providing explicit guidance for Large Language Model (LLM) decoders in multi-talker settings.
- A lightweight gated residual cross-attention adapter is proposed to inject talker-aware acoustic embeddings as external memory after the self-attention sub-layer, enabling dynamic access to fine-grained acoustic evidence at every decoding step.
- A two-stage acoustic adaptation framework utilizing low-rank updates (LoRA) is presented to refine both the cross-attention adapters and pretrained LLM self-attention projections, with experiments on Libri2Mix and Libri3Mix demonstrating consistent performance gains, particularly in challenging three-talker mixtures.
Introduction
Large Language Models (LLMs) serve as powerful decoders for Serialized Output Training in multi-talker Automatic Speech Recognition, yet their performance drops significantly when handling complex three-talker mixtures. Prior approaches rely on projecting acoustic evidence into a static prefix, which often results in lossy representations that fail to provide the fine-grained grounding needed to disentangle densely interleaved speech streams. To address this, the authors propose a two-stage acoustic adaptation framework that injects talker-aware acoustic evidence directly into the LLM decoder using a lightweight gated residual cross-attention adapter. They further refine both the adapter and the LLM's self-attention projections with parameter-efficient LoRA updates, ensuring stable training and robust performance even under limited data conditions.
Dataset
-
Dataset Composition and Sources: The authors evaluate their models on LibriMix, a benchmark for overlapped-speech recognition built upon the LibriSpeech corpus. Additive noise for noisy conditions is sampled from the WHAM! corpus.
-
Subset Details:
- Libri2Mix: Synthesized from the train-clean-100, train-clean-360, dev-clean, and test-clean subsets of LibriSpeech using official scripts and standard ESPnet offset settings for two-talker configurations. The training set contains approximately 270 hours of speech, while the development and test sets each contain about 11 hours.
- Libri3Mix: Generated using custom offset files to ensure diverse onset-time configurations for three-talker mixtures. The training set comprises approximately 186 hours of speech, with development and test sets holding about 11 hours each.
-
Usage in Model Training: The authors follow the official LibriMix protocol to generate both Libri2Mix and Libri3Mix mixtures. These datasets serve as the primary evaluation benchmark, with the training splits used for model optimization and the development and test splits for performance assessment.
-
Processing and Metadata: The team utilized official LibriMix scripts to synthesize clean mixtures and applied specific offset files to control talker onset times. While standard settings were used for two-talker scenarios, custom offset files were constructed for three-talker mixtures to increase configuration diversity, with these files scheduled for release after the review period.
Method
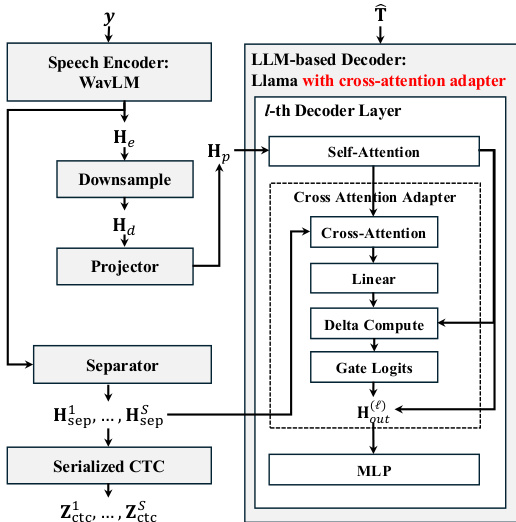
The authors propose a framework for LLM-based multi-talker ASR that integrates acoustic evidence directly into the decoder. The system consists of a speech encoder, a separator for talker-specific streams, and an LLM decoder enhanced with a cross-attention adapter.
Refer to the framework diagram for the overall architecture. The input waveform y is processed by a Speech Encoder (WavLM) to produce frame-level representations He. These features undergo temporal reduction via downsampling to Hd and are projected to the LLM hidden dimension Hp. Simultaneously, a Separator module processes the encoder output to generate S talker-specific streams Hsep1,…,HsepS, which are also used for Serialized CTC supervision.
The LLM-based Decoder, based on Llama, incorporates a specialized Cross Attention Adapter within each decoder layer. As shown in the figure below, the adapter is inserted after the Self-Attention sub-layer. It takes the hidden states from self-attention as queries and the projected acoustic memory as keys and values. The adapter computes a context vector which is then processed through a Linear layer and a Delta Compute block. A Gate Logits mechanism controls the residual update, ensuring that the acoustic information is injected without disrupting the pre-trained language representations.
The training process follows a two-stage adaptation strategy designed to balance semantic initialization with robust acoustic conditioning. The pipeline and motivations for each stage are illustrated in the figure below.
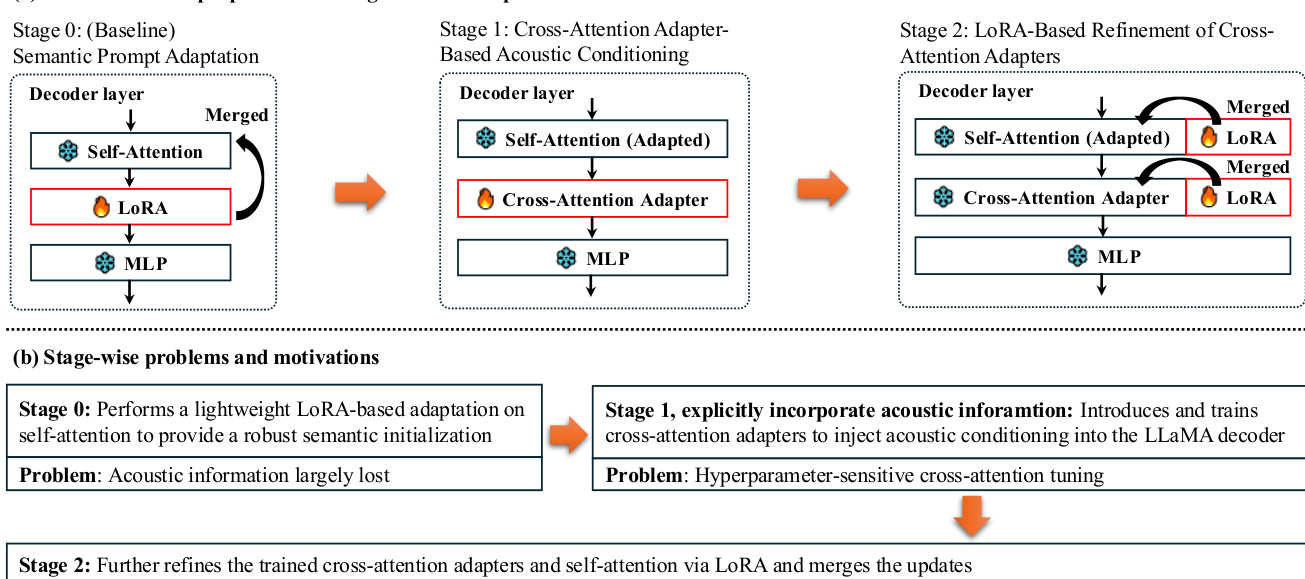
Stage 0 serves as a baseline where the LLM decoder is adapted using LoRA on the self-attention projections. This provides a robust semantic initialization without explicit acoustic injection. Stage 1 introduces the gated cross-attention adapter to explicitly incorporate acoustic information. This stage trains the adapter to inject talker-aware acoustic evidence into the decoder via a gated residual update. However, training these adapters can be hyperparameter-sensitive. To address this, Stage 2 applies LoRA-based refinement to both the cross-attention adapters and the self-attention projections. This refinement strengthens the adaptation capacity and improves robustness under limited data. Finally, the learned low-rank updates are merged into the base weights, resulting in a model with no additional parameters at inference time.
Experiment
- LLM-based systems significantly improve performance on two-talker mixtures by leveraging semantic priors but struggle with three-talker scenarios due to insufficient context resolution in static prefix conditioning.
- Acoustic-rich prefixes outperform text-only prompts by providing better constraints for LLM decoding, yet one-shot prefixing alone remains inadequate for fine-grained talker assignment in heavily overlapped speech.
- Decoder-side acoustic injection via cross-attention yields substantial gains in three-talker conditions by enabling step-wise access to acoustic memory, whereas naive stacked cross-attention can degrade performance in easier two-talker settings due to over-conditioning.
- Gated cross-attention adaptation offers more stable and effective acoustic conditioning than naive stacking by regulating injection levels and preserving pretrained language representations, though it still lags behind serialized CTC alignment in the most challenging regimes.
- Stage-2 LoRA refinement enhances robustness and reduces hyperparameter sensitivity, with joint refinement of cross-attention adapters and self-attention projections consistently delivering the best overall results, particularly for 3B-scale backbones.
- The proposed method achieves a clear advantage over existing pipelines in three-talker settings, and larger LLM decoders consistently outperform models trained from scratch even when using serialized CTC references.