Command Palette
Search for a command to run...
エンタープライズ自動化にはターミナル Agent で十分である
エンタープライズ自動化にはターミナル Agent で十分である
Patrice Bechard Orlando Marquez Ayala Emily Chen Jordan Skelton Sagar Davasam Srinivas Sunkara Vikas Yadav Sai Rajeswar
概要
デジタルプラットフォームと対話し、自律的に意味のある企業タスクを実行するエージェントの構築への関心が高まっている。これまでに探求されたアプローチには、Model Context Protocol(MCP)などの抽象化に基づいて構築されたツール拡張型エージェントや、グラフィカルインターフェースを介して動作するウェブエージェントが含まれる。しかし、コストや運用オーバーヘッドを考慮すると、そのような複雑なエージェントシステムが本当に必要かどうかは依然として不明確である。我々は、ターミナルとファイルシステムのみを備えたコーディングエージェントが、プラットフォームの API と直接対話することで、多くの企業タスクをより効果的に解決できると主張する。この仮説を多様な実世界システムにおいて評価した結果、これらの低レベルのターミナルエージェントは、より複雑なエージェントアーキテクチャと同等か、あるいはそれ以上の性能を発揮することが示された。本研究の知見は、強力なファウンデーションモデルと組み合わせれば、単純なプログラミングインターフェースが実用的な企業自動化に十分であることを示唆している。
One-sentence Summary
Researchers from ServiceNow and Mila propose StarShell, a minimal terminal agent that outperforms complex GUI and tool-augmented systems by directly interacting with enterprise APIs, demonstrating that simple programmatic interfaces combined with strong LLMs suffice for efficient, cost-effective automation across platforms like ServiceNow and GitLab.
Key Contributions
- The paper demonstrates that simple terminal agents interacting directly with APIs are effective and efficient for enterprise automation, outperforming MCP-based tool-augmented agents and matching or exceeding web-agent performance at substantially lower cost through a systematic evaluation of frontier LLMs.
- A unified benchmark is introduced that spans multiple production platforms, featuring verified evaluation environments and datasets designed to capture realistic enterprise tasks.
- Practical extensions to terminal agents are explored, including the integration of filesystem-based documentation access and the capability for agents to create their own reusable skills.
Introduction
Enterprise automation increasingly relies on LLM-powered agents to execute complex, multi-step tasks within production systems, where reliability and cost efficiency are critical. Prior approaches often depend on GUI-driven navigation or tool-augmented frameworks like Model Context Protocol (MCP), which introduce brittle action chains, restrict expressivity to predefined operations, and incur high operational overhead. The authors leverage a minimal terminal-based coding agent that interacts directly with platform APIs to demonstrate that simple programmatic interfaces combined with strong foundation models can match or outperform these complex architectures. Their work introduces a unified benchmark across multiple production platforms and shows that direct API interaction offers superior flexibility, resilience, and cost-effectiveness for a broad class of real-world enterprise tasks.
Dataset
-
Dataset Composition and Sources: The authors evaluate agents across three enterprise platforms: ServiceNow, GitLab, and ERPNext. These environments cover IT service management, software development lifecycle management, and enterprise resource planning. The dataset combines adapted tasks from prior benchmarks for ServiceNow and GitLab with a newly constructed benchmark for ERPNext.
-
Key Details for Each Subset:
- ServiceNow: Contains 330 tasks derived from 33 templates, adapted from previous work but redesigned for programmatic verification.
- GitLab: Includes 192 tasks adapted from existing benchmarks with updated evaluation pipelines.
- ERPNext: Features 207 new tasks designed from scratch by professional linguists, covering diverse record types and workflow complexities.
- Task Types: All subsets include record creation, retrieval, update, deletion, filtering, sorting, navigation, and multi-step composite workflows.
-
Usage in the Model: The authors utilize these environments as evaluation benchmarks rather than training data. Each task requires agents to inspect system states, retrieve information, and perform actions to modify platform records. The evaluation relies on programmatic verification against live platform instances instead of hardcoded values or browser scripts.
-
Processing and Design Strategies:
- Navigation Requirement: Every task omits start URLs or direct links, forcing agents to identify relevant API endpoints or pages based solely on natural-language goals.
- Ambiguity Removal: Goal descriptions are systematically rewritten to eliminate ambiguity, such as specifying exact table names instead of generic terms.
- Documentation Integration: A local documentation corpus is provided for each platform, obtained by scraping official docs or repositories and converting them to Markdown with YAML frontmatter.
- Environment Setup: All platforms run in containerized instances with isolated data, API access, optional MCP tool registries, and standardized documentation organized by topic hierarchy.
Method
The authors evaluate three distinct agent interaction paradigms to determine the most effective approach for enterprise automation: Tool-augmented agents (MCP), Web agents, and Terminal agents. Tool-augmented agents rely on a curated set of API tools exposed via MCP servers, which simplifies execution but constrains the agent to predefined functionality. Web agents operate through graphical interfaces, observing rendered UIs and issuing low-level actions like clicking or typing. In contrast, the proposed method focuses on a simple coding agent that operates through a terminal and filesystem. This agent writes and executes code to interact directly with platform APIs, enabling flexible interaction and exploration without relying on GUIs or pre-defined tool registries.
A comparative analysis of these paradigms on a specific task demonstrates the efficiency of the terminal approach.
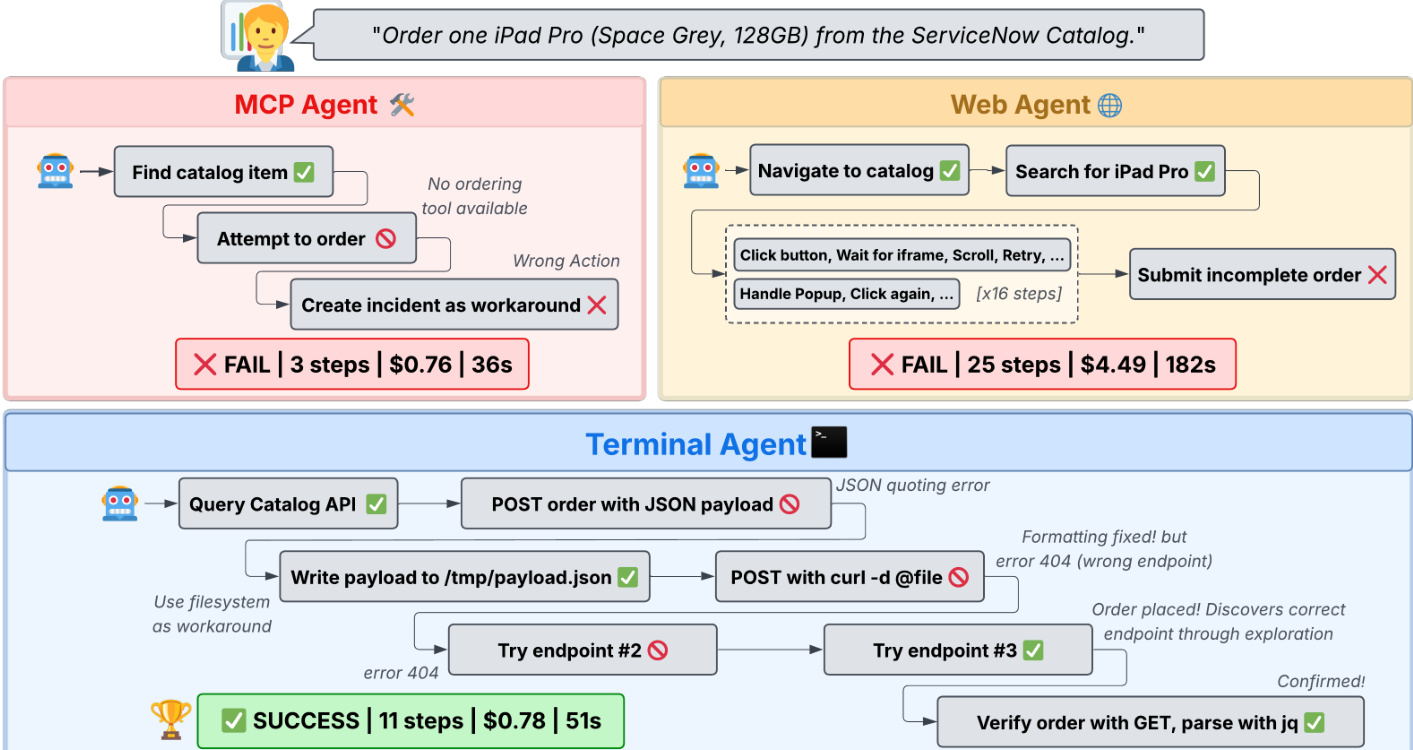
As illustrated in the framework diagram, the MCP agent fails to complete the order due to a lack of available ordering tools, while the Web agent fails after 25 steps due to UI complexity and incorrect submissions. The Terminal agent successfully completes the task in 11 steps by querying the Catalog API and handling JSON payloads directly, achieving a lower cost and faster execution time.
The core implementation of this terminal agent is StarShell, a minimal coding-agent environment designed for enterprise automation. The system operates through a REPL-style loop consisting of planning, execution, inspection, and iteration.
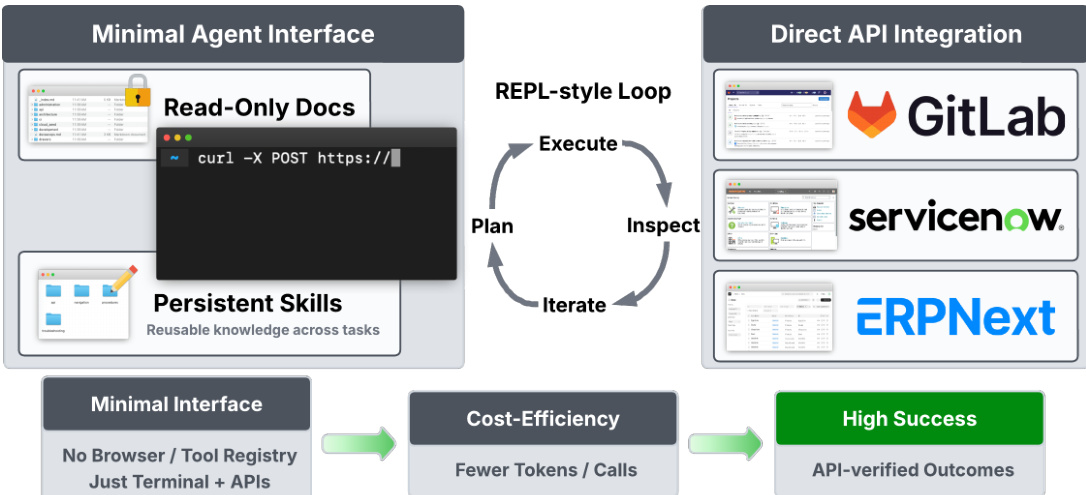
The architecture, as shown in the figure below, relies on a minimal interface comprising a terminal for command execution and a filesystem for storing artifacts. The agent receives a task description and iteratively generates commands or code snippets to run. Typical actions include querying platform APIs, filtering results, and updating records. API responses and execution outputs are returned to the model as observations, enabling iterative reasoning and correction.
A key component of the design is the persistent skills directory. The filesystem provides persistent task state, allowing the agent to read documentation, cache intermediate results, and persist reusable skills such as scripts or notes capturing previously discovered solutions. Unlike tool-based agents, StarShell does not rely on predefined action schemas. Instead, it discovers platform capabilities dynamically by reading documentation or inspecting API responses. This design allows the agent to compose operations that may not be represented in curated tool registries, facilitating direct API integration with platforms like GitLab, ServiceNow, and ERPNext.
The evaluation environment is fully reset before each task to ensure independence. Validators check the platform state before and after the agent finishes rather than inspecting the agent's actions. For platforms like ServiceNow and GitLab, validators issue API calls against the live instance to verify that expected records were created or updated. For ERPNext, validators execute SQL queries directly against the database. For read-oriented tasks, the validator parses the agent's final message to extract the returned answer or URL and checks it against the ground truth. This ensures that tasks are evaluated against the actual platform state rather than relying on string matching alone.
Experiment
- Comparison of interaction paradigms validates that terminal agents offer the best cost-performance tradeoff, matching or exceeding the success rates of web agents while avoiding the high inference costs of browser rendering and the rigid tool constraints of MCP agents.
- Evaluation of documentation access reveals that its utility is platform-dependent; task-oriented documentation improves performance on some platforms, while reference-style documentation can mislead agents and increase costs by encouraging suboptimal API strategies.
- Experiments on persistent memory demonstrate that allowing agents to store and reuse self-generated skills significantly boosts success rates and reduces costs, particularly on platforms with unfamiliar APIs or complex field mappings.
- Analysis of failure modes confirms that task failures stem from the agent's inability to make logical progress rather than tool unreliability, as error rates in tool calls are similar for both successful and failed tasks.
- Comparison of single versus multi-agent systems shows that planner-executor architectures provide modest gains on complex, multi-step workflows for weaker models but offer little advantage over single agents when using stronger LLM backbones.
- Hybrid agent experiments indicate that combining terminal and browser access can solve tasks infeasible via API alone, but efficiency depends heavily on the model's ability to correctly route subtasks to the appropriate tool.