HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

「損切り」の技術!効率的な並列推理に向けた早期Path Pruningの学習 (※注:ご要望に基づき、タイトルとしての学術的な響きを重視して翻訳いたしました。文脈に応じて「Cut Your Losses」を「損失を最小限に抑える」などの意訳にすることも可能ですが、論文タイトルとしてのインパクトを考慮しています。)

Qwen3.5-Omni 技術報告書



























「損切り」の技術!効率的な並列推理に向けた早期Path Pruningの学習 (※注:ご要望に基づき、タイトルとしての学術的な響きを重視して翻訳いたしました。文脈に応じて「Cut Your Losses」を「損失を最小限に抑える」などの意訳にすることも可能ですが、論文タイトルとしてのインパクトを考慮しています。)
Qwen3.5-Omni 技術報告書
効率的かつコスト効率の高い Retrieval-Augmented Generation システムに向けた Web Retrieval-Aware Chunking (W-RAC)
PersonaVLM:長期的なパーソナライズを実現するマルチモーダル LLMs
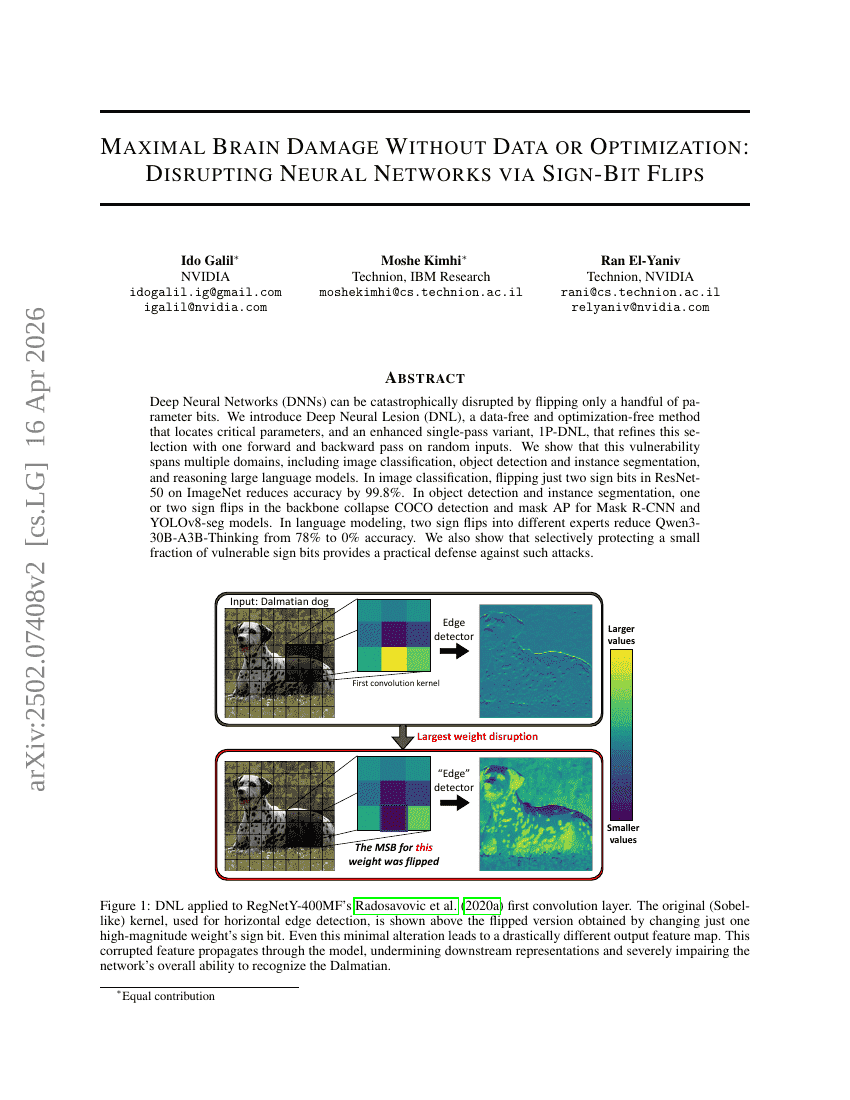
データや最適化を介さない最大脳損傷:Sign-Bit FlipによるNeural Networkの破壊
Diffusion Probabilistic ModelsにおけるSNR-t Biasの解明
マルチモーダルOCR:ドキュメントからのあらゆる情報の解析
Granite-speech:強力な英語ASR能力を備えたオープンソースのSpeech-aware LLMs
Fish-Speech: Large Language Modelsを活用した高度な多言語Text-to-Speech合成
ビデオオブジェクトおよびインタラクションの削除
VoxCPM: 文脈適応型音声生成および忠実なボイスクローニングのためのTokenizer-Free TTS
OmniVoice: Diffusion Language Modelsを用いた多言語ゼロショットText-to-Speechに向けた研究
VisionがTextへと変わる時:Vision-Language ModelsにおけるOCRルーティングのボトルネックの特定
OCRか、それともNotか?実世界の広範なデータセットを用いた、MLLMs時代におけるドキュメント情報抽出の再考
dnaHNet:ゲノム配列学習のためのスケーラブルかつ階層的なFoundation Model
ニューラルコンピュータ
ASGuard: 標的型Jailbreaking Attackを軽減するためのActivation-Scaling Guard
GlobalSplat: Global Scene Tokensを用いた効率的なFeed-Forward 3D Gaussian Splatting
推論モデルをどのようにFine-Tuneすべきか?Studentの特性に整合したSFTデータを合成するためのTeacher-Student協調フレームワーク
RAD-2: Generator-Discriminator フレームワークにおける Reinforcement Learning のスケーリング
DR3-Eval:面向真实且可复现的深度研究评估 (Deep Research Evaluation)
HY-World 2.0:一种用于 3D 世界重建、生成与仿真的 Multi-Modal World Model
pi0.7: 発現的な能力を備えたステアラブルな汎用ロボット基盤モデル(Steerable Generalist Robotic Foundation Model)
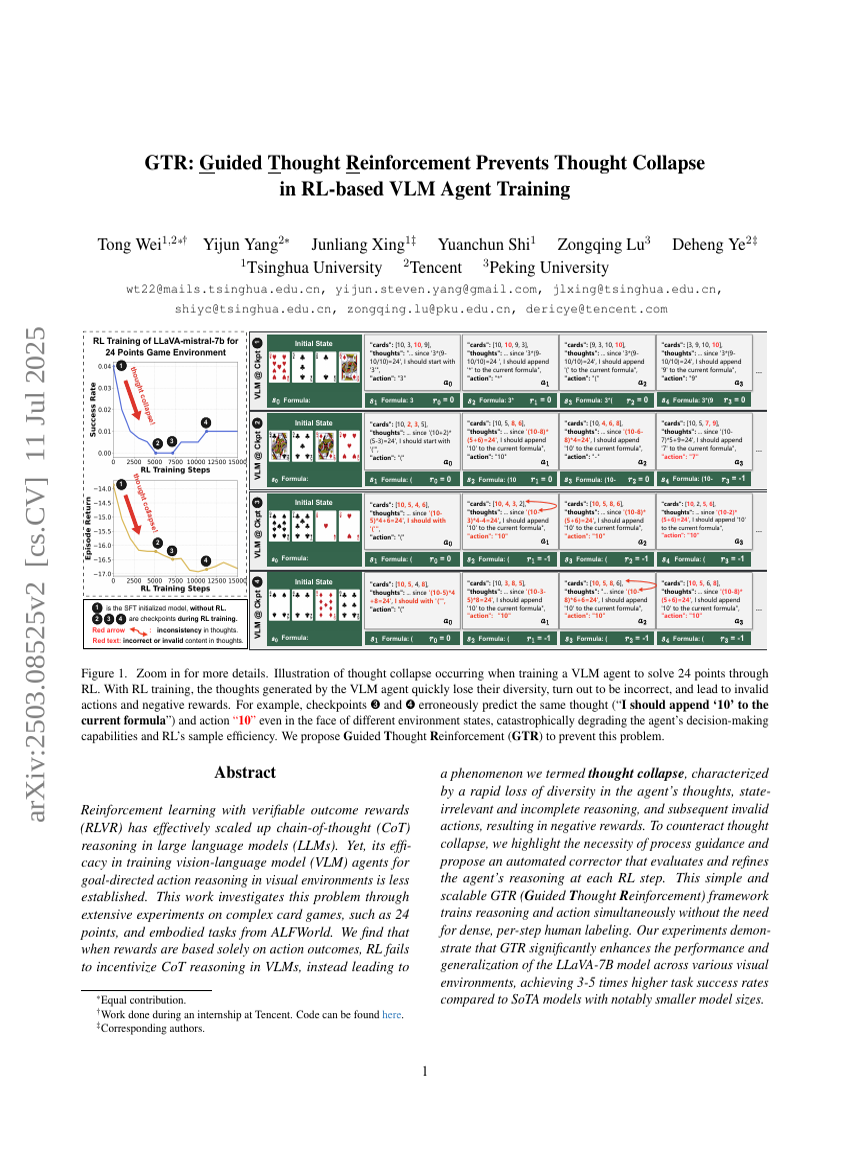
GTR: Guided Thought Reinforcement Prevents Thought Collapse in RL-based VLM Agent Training
Large Language ModelsのためのAgent Skills:アーキテクチャ、獲得、セキュリティ、および今後の展望
空間理論:Foundation Modelsは能動的な探索を通じて空間的信念を構築できるか?
メモリ転移学習:Coding Agentにおけるドメインを跨いだメモリの転移メカニズム
OccuBench: 言語 World Models を介した実世界の専門的タスクにおける AI Agents の評価
SpatialEvo: 決定論的な幾何学的環境を通じた自己進化型空間インテリジェンス
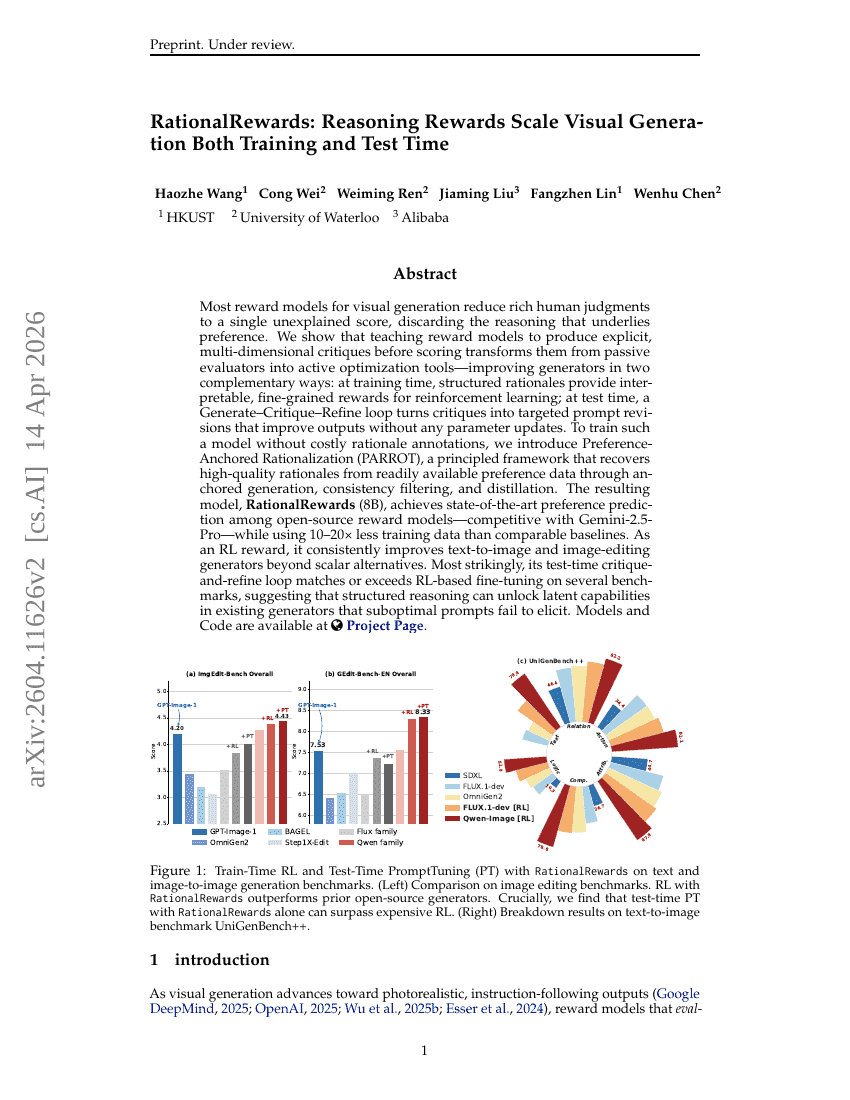
RationalRewards: Reasoning Rewards が Training と Test Time の両方において Visual Generation を Scale する
Seedance 2.0: 世界の複雑性に対応するビデオ生成技術の進化
GameWorld:面向多模态 Game Agents 标准化与可验证评估的研究
効率的かつコスト効率の高い Retrieval-Augmented Generation システムに向けた Web Retrieval-Aware Chunking (W-RAC)
PersonaVLM:長期的なパーソナライズを実現するマルチモーダル LLMs
データや最適化を介さない最大脳損傷:Sign-Bit FlipによるNeural Networkの破壊
Diffusion Probabilistic ModelsにおけるSNR-t Biasの解明
マルチモーダルOCR:ドキュメントからのあらゆる情報の解析
Granite-speech:強力な英語ASR能力を備えたオープンソースのSpeech-aware LLMs
Fish-Speech: Large Language Modelsを活用した高度な多言語Text-to-Speech合成
ビデオオブジェクトおよびインタラクションの削除
VoxCPM: 文脈適応型音声生成および忠実なボイスクローニングのためのTokenizer-Free TTS
OmniVoice: Diffusion Language Modelsを用いた多言語ゼロショットText-to-Speechに向けた研究
VisionがTextへと変わる時:Vision-Language ModelsにおけるOCRルーティングのボトルネックの特定
OCRか、それともNotか?実世界の広範なデータセットを用いた、MLLMs時代におけるドキュメント情報抽出の再考
dnaHNet:ゲノム配列学習のためのスケーラブルかつ階層的なFoundation Model
ニューラルコンピュータ
ASGuard: 標的型Jailbreaking Attackを軽減するためのActivation-Scaling Guard
GlobalSplat: Global Scene Tokensを用いた効率的なFeed-Forward 3D Gaussian Splatting
推論モデルをどのようにFine-Tuneすべきか?Studentの特性に整合したSFTデータを合成するためのTeacher-Student協調フレームワーク
RAD-2: Generator-Discriminator フレームワークにおける Reinforcement Learning のスケーリング
DR3-Eval:面向真实且可复现的深度研究评估 (Deep Research Evaluation)
HY-World 2.0:一种用于 3D 世界重建、生成与仿真的 Multi-Modal World Model
pi0.7: 発現的な能力を備えたステアラブルな汎用ロボット基盤モデル(Steerable Generalist Robotic Foundation Model)
GTR: Guided Thought Reinforcement Prevents Thought Collapse in RL-based VLM Agent Training
Large Language ModelsのためのAgent Skills:アーキテクチャ、獲得、セキュリティ、および今後の展望
空間理論:Foundation Modelsは能動的な探索を通じて空間的信念を構築できるか?
メモリ転移学習:Coding Agentにおけるドメインを跨いだメモリの転移メカニズム
OccuBench: 言語 World Models を介した実世界の専門的タスクにおける AI Agents の評価
SpatialEvo: 決定論的な幾何学的環境を通じた自己進化型空間インテリジェンス
RationalRewards: Reasoning Rewards が Training と Test Time の両方において Visual Generation を Scale する
Seedance 2.0: 世界の複雑性に対応するビデオ生成技術の進化
GameWorld:面向多模态 Game Agents 标准化与可验证评估的研究