HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

SkillClaw: Agentic Evolverによってスキルを集合的に進化させる

MDPBench: 実世界シナリオにおける多言語ドキュメントパースのためのベンチマーク


























SkillClaw: Agentic Evolverによってスキルを集合的に進化させる
MDPBench: 実世界シナリオにおける多言語ドキュメントパースのためのベンチマーク
TC-AE: Deep Compression AutoencoderにおけるToken Capacityの解放
INSPATIO-WORLD: 時空間自己回帰モデリングによるリアルタイム4D World Simulator
FlowInOne: Image-in, Image-out の Flow Matching としてマルチモーダル Generation を統一する
MARS:実現する Autoregressive Models による Multi-Token Generation
ピクセルではなくストロークで考える:交互的なReasoningによるプロセス駆動型画像生成
RAGEN-2:Agentic RLにおけるReasoning Collapse(推論の崩壊)
Vanast: 合成されたTriplet Supervisionを用いたHuman Image AnimationによるVirtual Try-On
ThinkTwice: 推論とSelf-RefinementのためにLarge Language Modelsを共同で最適化する手法
ACES: Who Tests the Tests? Leave-One-Out AUC Consistency for Code Generation
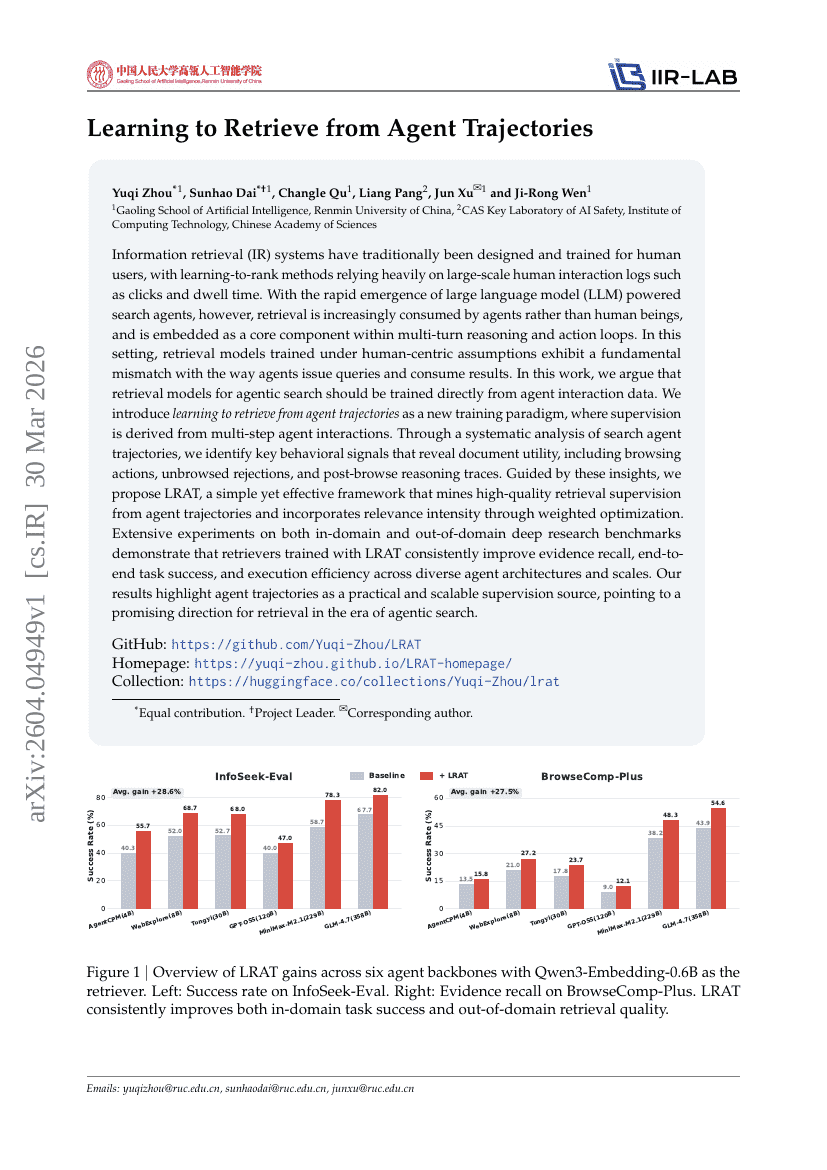
Agent Trajectories からの Retrieval を学習する
Claw-Eval:迈向自主 Agent 的可信评估
Video-MME-v2:向着全面视频理解 Benchmark 的下一阶段迈进
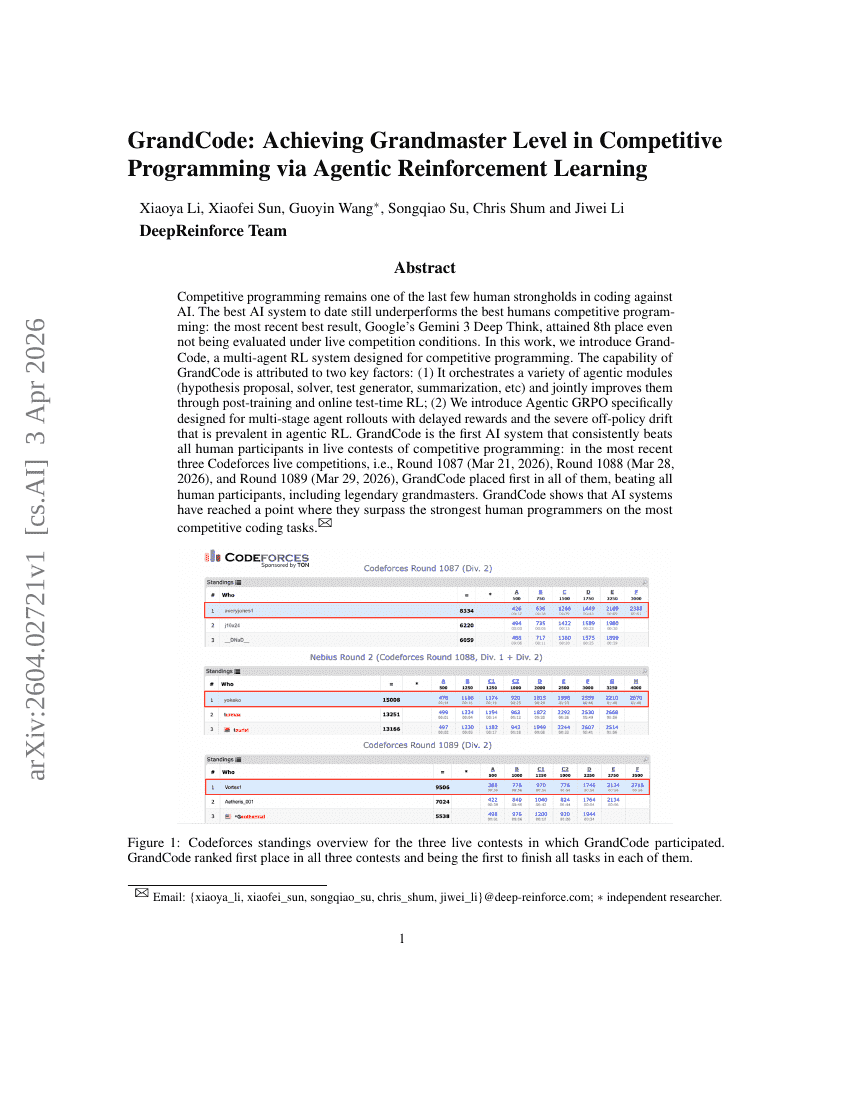
GrandCode: Agentic Reinforcement Learningを通じて競技プログラミングにおけるGrandmasterレベルを実現する
LIBERO-Para: VLAモデルにおける言い換えに対する堅牢性を評価するための診断用benchmarkおよび評価指標
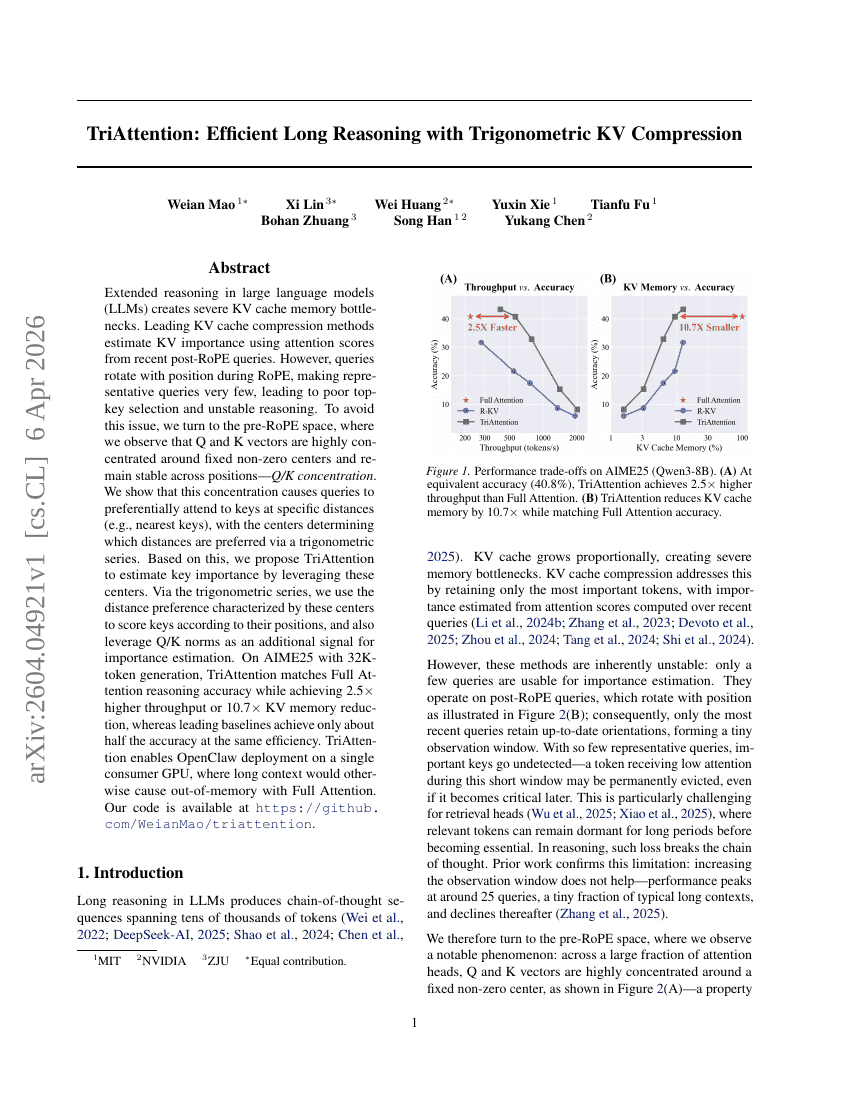
TriAttention: 三角関数を用いたKV Compressionによる効率的なLong Reasoning
MinerU2.5-Pro:大規模なData-Centricな文書解析における限界への挑戦
Adam's Law:Large Language Modelsにおけるテキスト出現頻度の法則
OpenWorldLib:高度な World Models に関する統一された Codebase および定義
WAXAL:大規模多言語アフリカ言語音声コーパス
DRACO:深層研究の正確性、完全性及び客観性に関するクロスドメインベンチマーク
HuatuoGPT-o1:LLMs による医療領域の複雑推論 toward
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
InCoder-32B-Thinking:思考のための産業用コード世界モデル
Agentic-MME: Agentic Capability がマルチモーダル知性に真にもたらすものとは?
Token Warping により、MLLMs は近接視点からの観察が可能となる
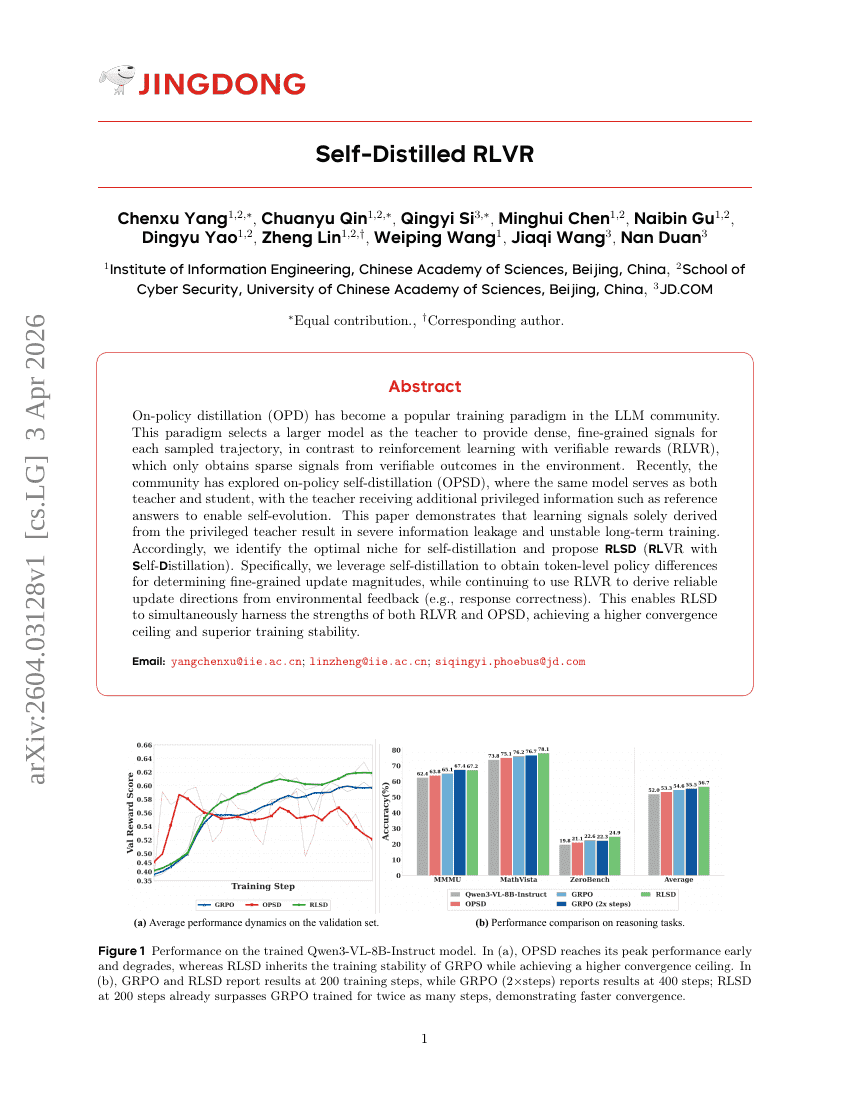
Self-Distilled RLVR
ストリーミング動画理解のためのシンプルなベースライン
CORAL:オープンエンドな発見に向けた自律型マルチエージェント進化への道
操作可能な視覚表現
SKILL0: 文脈内エージェント強化学習によるスキルの内面化
TC-AE: Deep Compression AutoencoderにおけるToken Capacityの解放
INSPATIO-WORLD: 時空間自己回帰モデリングによるリアルタイム4D World Simulator
FlowInOne: Image-in, Image-out の Flow Matching としてマルチモーダル Generation を統一する
MARS:実現する Autoregressive Models による Multi-Token Generation
ピクセルではなくストロークで考える:交互的なReasoningによるプロセス駆動型画像生成
RAGEN-2:Agentic RLにおけるReasoning Collapse(推論の崩壊)
Vanast: 合成されたTriplet Supervisionを用いたHuman Image AnimationによるVirtual Try-On
ThinkTwice: 推論とSelf-RefinementのためにLarge Language Modelsを共同で最適化する手法
ACES: Who Tests the Tests? Leave-One-Out AUC Consistency for Code Generation
Agent Trajectories からの Retrieval を学習する
Claw-Eval:迈向自主 Agent 的可信评估
Video-MME-v2:向着全面视频理解 Benchmark 的下一阶段迈进
GrandCode: Agentic Reinforcement Learningを通じて競技プログラミングにおけるGrandmasterレベルを実現する
LIBERO-Para: VLAモデルにおける言い換えに対する堅牢性を評価するための診断用benchmarkおよび評価指標
TriAttention: 三角関数を用いたKV Compressionによる効率的なLong Reasoning
MinerU2.5-Pro:大規模なData-Centricな文書解析における限界への挑戦
Adam's Law:Large Language Modelsにおけるテキスト出現頻度の法則
OpenWorldLib:高度な World Models に関する統一された Codebase および定義
WAXAL:大規模多言語アフリカ言語音声コーパス
DRACO:深層研究の正確性、完全性及び客観性に関するクロスドメインベンチマーク
HuatuoGPT-o1:LLMs による医療領域の複雑推論 toward
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
InCoder-32B-Thinking:思考のための産業用コード世界モデル
Agentic-MME: Agentic Capability がマルチモーダル知性に真にもたらすものとは?
Token Warping により、MLLMs は近接視点からの観察が可能となる
Self-Distilled RLVR
ストリーミング動画理解のためのシンプルなベースライン
CORAL:オープンエンドな発見に向けた自律型マルチエージェント進化への道
操作可能な視覚表現
SKILL0: 文脈内エージェント強化学習によるスキルの内面化