Command Palette
Search for a command to run...
Vision2Web:エージェント検証を備えた視覚的ウェブサイト開発のための階層的ベンチマーク
Vision2Web:エージェント検証を備えた視覚的ウェブサイト開発のための階層的ベンチマーク
Zehai He Wenyi Hong Zhen Yang Ziyang Pan Mingdao Liu Xiaotao Gu Jie Tang
概要
大規模言語モデル(LLM)の近年の進展により、コーディングエージェントの能力は向上したが、複雑なエンドツーエンドのウェブサイト開発に関する体系的な評価は依然として限られている。このギャップを埋めるため、視覚的ウェブサイト開発のための階層型ベンチマーク「Vision2Web」を提案する。本ベンチマークは、静的な UI からコード生成、インタラクティブなマルチページフロントエンドの再現、長期視野にわたるフルスタックウェブサイト開発に至るまでを網羅する。ベンチマークは実世界のウェブサイトを基に構築され、16 のカテゴリにわたる合計 193 のタスク、918 枚のプロトタイプ画像、1,255 のテストケースで構成される。柔軟かつ包括的、かつ信頼性の高い評価を実現するため、GUI エージェント検証器と VLM ベースのジャッジという 2 つの相補的コンポーネントに基づく、ワークフローベースのエージェント検証パラダイムを提案する。異なるコーディングエージェントフレームワークで実装された複数の視覚言語モデル(VLM)を評価した結果、すべてのタスクレベルで顕著な性能差が明らかとなり、最先端モデルであってもフルスタック開発においては依然として困難に直面していることが示された。
One-sentence Summary
Researchers from Tsinghua University and another institute introduce Vision2Web, a hierarchical benchmark for visual website development that evaluates LLMs across static UI-to-code and full-stack tasks. Using a novel workflow-based agent verification paradigm, the study reveals significant performance gaps in current models for complex, end-to-end web creation.
Key Contributions
- The paper introduces Vision2Web, a hierarchical benchmark for visual website development that spans static UI-to-code generation, interactive multi-page frontend reproduction, and long-horizon full-stack development using 193 real-world tasks and 918 prototype images.
- A workflow-based agent verification paradigm is presented to ensure reproducible evaluation by structuring tests as directed dependency graphs with explicitly defined nodes that constrain agent execution while maintaining flexibility.
- The work implements two complementary verification components, a GUI agent verifier for functional correctness and a VLM-based judge for visual fidelity, which experiments show reveal substantial performance gaps in state-of-the-art models on full-stack development tasks.
Introduction
Developing and evaluating autonomous agents for visual website creation is critical as these systems move from simple code generation to full end-to-end software development. Prior evaluation methods struggle because traditional unit tests cannot handle diverse implementations, while existing agent-based evaluators often behave unpredictably due to loosely specified objectives. Furthermore, visual testing relies on brittle rule-based scripts or pixel-level comparisons that fail to capture human perceptual judgments. To address these gaps, the authors introduce Vision2Web, a hierarchical benchmark that employs a workflow-based agent verification paradigm. This approach constrains agent execution through structured test workflows and explicit verification nodes, enabling reproducible and implementation-agnostic assessment of both functional correctness and visual fidelity within a unified framework.
Dataset
-
Dataset Composition and Sources
- The authors construct Vision2Web from real-world websites sourced exclusively from the C4 validation set to prevent data leakage.
- The benchmark spans four major categories (Content, Transaction, SaaS Platforms, Public Services) and 16 subcategories to ensure diversity.
- It includes a multimedia resource library containing images, icons, videos, and fonts to simulate realistic development environments.
-
Key Details for Each Subset
- The dataset comprises 193 tasks divided into three hierarchical levels of increasing complexity:
- Static Webpage (100 tasks): Focuses on visual fidelity across desktop, tablet, and mobile resolutions using prototype images.
- Interactive Frontend (66 tasks): Requires generating multi-page frontends with coherent navigation flows based on multiple prototypes and text descriptions.
- Full-Stack Website (27 tasks): Simulates realistic engineering scenarios with requirement documents, complex state management, and backend integration.
- The collection includes 918 prototype images and 1,255 test cases, totaling 21,516 input files.
- The dataset comprises 193 tasks divided into three hierarchical levels of increasing complexity:
-
Data Processing and Filtering Pipeline
- A three-stage filtering pipeline refines the initial web corpus:
- Structural Assessment: Analyzes DOM properties like tag distribution and tree depth to exclude simple or malformed pages, reducing candidates to 63,515.
- Content Screening: Uses VLM-based scoring to retain only 7,391 pages with functional richness and visual coherence.
- Manual Review: Human annotators verify page consistency, implementation difficulty, and category balance to finalize the task set.
- Test case annotation employs an expert-in-the-loop strategy where PhD researchers draft high-level workflows and Claude Code refines them into executable sequences.
- A three-stage filtering pipeline refines the initial web corpus:
-
Usage in Model Evaluation
- The authors utilize the dataset to evaluate multimodal coding agents via a workflow-based agent verification paradigm.
- Evaluation relies on a GUI agent verifier to execute test workflows and a VLM-based judge to quantitatively assess visual fidelity against prototypes.
- The benchmark measures both functional correctness and visual fidelity without relying on external orchestration layers, ensuring agents depend solely on their own reasoning and coding capabilities.
Method
The proposed framework for automated website evaluation is structured into three sequential phases: Hierarchical Task Formulation, Coding Agent generation, and Workflow-based Agent Verification. This pipeline ensures a systematic approach to generating and validating full-stack web applications.
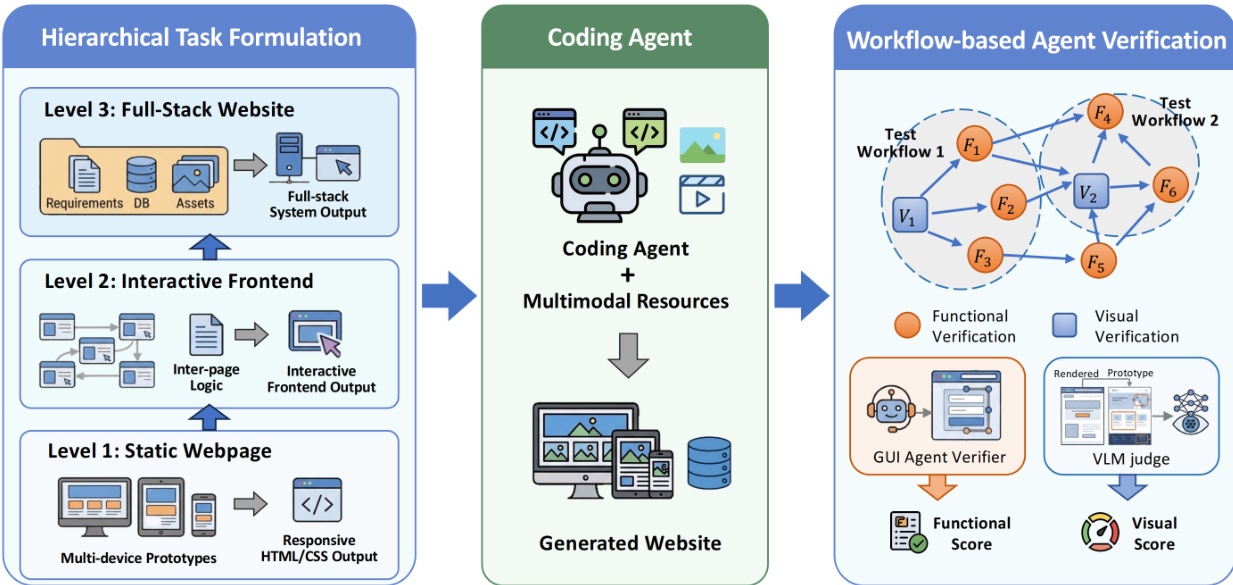
The process begins with Hierarchical Task Formulation, which decomposes the development objective into three distinct levels of complexity. Level 1 targets the creation of a Static Webpage, focusing on responsive HTML/CSS output across multiple devices. Level 2 advances to an Interactive Frontend, incorporating inter-page logic to produce an interactive frontend output. Finally, Level 3 addresses the Full-Stack Website, integrating requirements, databases, and assets to generate a complete system output.
Following the task definition, the Coding Agent module utilizes multimodal resources to synthesize the website. This central component processes the specifications from the formulation phase to generate the actual code and assets required for the target system.
The final stage employs Workflow-based Agent Verification to assess the generated output. This stage formalizes end-to-end testing as a directed dependency graph where nodes represent self-contained verification sub-procedures and edges encode sequential dependencies. To balance evaluation stability and coverage efficiency, the system constructs test workflows by decoupling dependent test nodes to prevent error propagation and integrating related test nodes within the same application context.
Verification nodes are categorized into two complementary types. Functional Verification Nodes assess interaction fidelity and are formalized as a 3-tuple ni=⟨Oi,Ai,Vi⟩, where Oi specifies the testing objective, Ai defines guided actions, and Vi encodes validation criteria. A GUI Agent Verifier executes these nodes, maintaining a context Ci={H<i,Oi,Ai,Vi} that includes historical objectives and actions to ensure reproducible state transitions. The Functional Score (FS) is computed as the proportion of passed functional verification nodes.
Visual Verification Nodes assess visual fidelity by comparing rendered pages against reference prototypes. Each node is formalized as ni=⟨Pi⟩, where Pi denotes the target prototype. A dedicated VLM Judge is invoked to perform component-level comparisons, assigning fidelity scores based on predefined visual rubrics. The Visual Score (VS) is calculated as the average of all block-level scores across the prototypes. This dual-verifier approach allows for a granular and systematic assessment of both the functional logic and the visual consistency of the generated website.
Experiment
- Vision2Web evaluates eight state-of-the-art multimodal models across two coding agent frameworks to assess their capabilities in visual website development, revealing that performance consistently degrades as task complexity increases from static pages to full-stack applications.
- Agents struggle significantly with smaller device form factors and visually dense prototypes, indicating limited capacity for complex visual reasoning and responsive layout adaptation.
- Claude-Opus-4.5 demonstrates superior performance across frameworks and task levels compared to other models, while several agents fail entirely on complex full-stack tasks involving multi-page integration.
- Systematic weaknesses are observed in state-dependent operations such as state management and CRUD operations, whereas navigation and authentication tasks are handled more reliably.
- Failure analysis identifies distinct gaps in fine-grained visual alignment, cross-module consistency, and long-horizon system planning, which compound as development scope expands.
- The study validates the reliability of its evaluation pipeline, showing high agreement between the automated GUI agent verifier and human annotations, as well as strong rank consistency between the VLM-based judge and human preferences.