Command Palette
Search for a command to run...
PackForcing:短時間の動画トレーニングが、長時間の動画サンプリングおよび長文脈推論に十分である
PackForcing:短時間の動画トレーニングが、長時間の動画サンプリングおよび長文脈推論に十分である
Xiaofeng Mao Shaohao Rui Kaining Ying Bo Zheng Chuanhao Li Mingmin Chi Kaipeng Zhang
概要
自己回帰型ビデオ拡散モデルは顕著な進展を遂げてきたが、長尺ビデオ生成においては、解決困難な線形 KV キャッシュの増大、時間的繰り返し、および誤差の累積によってボトルネックに直面している。これらの課題に対処するため、我々は PackForcing を提案する。これは、革新的な三分割 KV キャッシュ戦略を通じて生成履歴を効率的に管理する統一フレームワークである。具体的には、歴史的コンテキストを以下の 3 種類に分類する:(1) Sink tokens:初期のアンカーフレームを全解像度で保持し、グローバルな意味情報を維持する;(2) Mid tokens:段階的な 3D 畳み込みと低解像度 VAE の再エンコーディングを融合させた双枝ネットワークにより、時空間的な大幅な圧縮(トークン数を 32 倍削減)を実現する;(3) Recent tokens:局所的な時間的整合性を確保するため、全解像度で保持する。品質を損なうことなくメモリフットプリントを厳密に制限するため、Mid tokens に対して動的な top-k コンテキスト選択機構を導入し、さらに連続的な Temporal RoPE Adjustment を組み合わせることで、除外されたトークンに起因する位置のギャップをわずかなオーバーヘッドでシームレスに再調整する。この原理的な階層的コンテキスト圧縮によって、PackForcing は単一の H200 GPU 上で、16 FPS のレートで 2 分間、832x480 の解像度を持つ一貫したビデオを生成可能である。その KV キャッシュは 4 GB に制限され、5 秒から 120 秒への驚異的な 24 倍の時間的外挿を実現する。ゼロショットで動作する場合も、わずか 5 秒のクリップのみで訓練された場合も、効果的に機能する。VBench における広範な実験結果は、時的整合性(26.07)および動的度(56.25)において最先端の性能を示し、短尺ビデオの教師信号が、高品質な長尺ビデオ合成に十分であることを証明している。https://github.com/ShandaAI/PackForcing
One-sentence Summary
Researchers from Alaya Studio, Fudan University, and Shanghai Innovation Institute present PackForcing, a framework that enables long-video generation by compressing historical KV caches into three partitions. This approach achieves 24x temporal extrapolation from short clips while maintaining state-of-the-art coherence on a single GPU.
Key Contributions
- The paper introduces PackForcing, a unified framework that partitions generation history into sink, compressed, and recent tokens to bound per-layer attention to approximately 27,872 tokens regardless of video length.
- A hybrid compression layer fusing progressive 3D convolutions with low-resolution VAE re-encoding achieves a 128× spatiotemporal compression for intermediate history, increasing effective memory capacity by over 27×.
- The method employs a dynamic top-k context selection mechanism coupled with an incremental Temporal RoPE adjustment to seamlessly correct position gaps caused by dropped tokens without requiring full cache recomputation.
Introduction
Autoregressive video diffusion models enable long-form generation but face critical bottlenecks where linear Key-Value cache growth causes out-of-memory errors and iterative prediction leads to severe semantic drift. Prior solutions either truncate history to save memory, which destroys long-range coherence, or retain full context, which exceeds the capacity of single GPUs for minute-scale videos. The authors introduce PackForcing, a unified framework that partitions generation history into sink, compressed, and recent tokens to bound memory usage while preserving global semantics. By employing a dual-branch network for massive spatiotemporal compression and a dynamic top-k selection mechanism with incremental RoPE adjustment, the method achieves stable 2-minute video synthesis on a single H200 GPU using only 5-second training clips.
Method
The authors propose PackForcing, a framework designed to resolve the memory bottleneck in autoregressive video generation by decoupling the generation history into three distinct functional partitions. Refer to the framework diagram for the overall architecture. The system organizes the denoising context into Sink Tokens, Mid Tokens, and Recent and Current Tokens. Sink Tokens correspond to the initial frames and are kept at full resolution to serve as semantic anchors. Recent and Current Tokens maintain high-fidelity local dynamics at full resolution. The vast majority of the history falls into the Mid Tokens partition, which undergoes aggressive compression to reduce the token count by approximately 32 times.
To achieve this compression, the authors employ a dual-branch compression module. As shown in the figure below, this module processes the Mid Tokens through two parallel pathways. The High-Resolution (HR) branch utilizes a 4-stage 3D CNN to preserve fine-grained structural details. The Low-Resolution (LR) branch decodes the latent frames to pixel space, applies pooling, and re-encodes them via a VAE to capture coarse semantics. These features are fused via element-wise addition to produce the final compressed tokens.
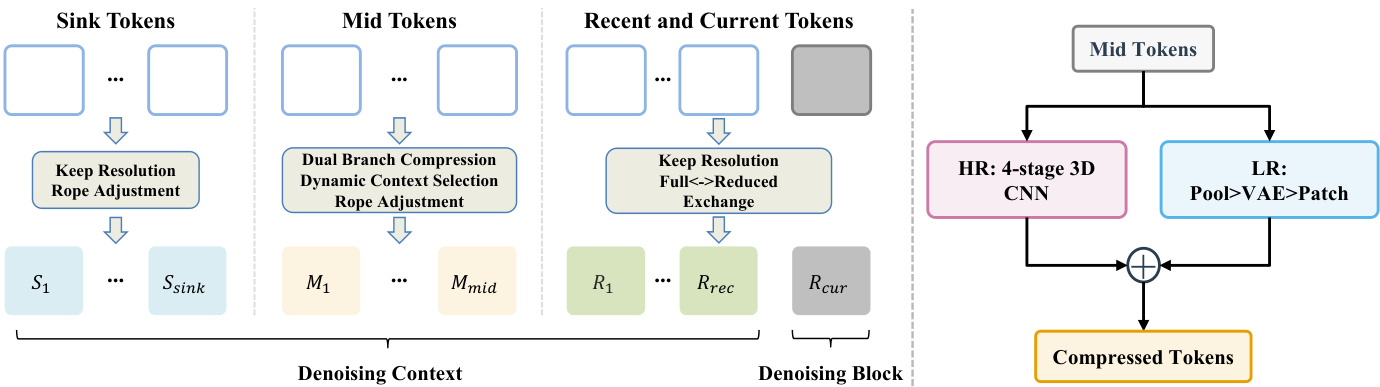
The specific architecture of the HR branch is detailed in the subsequent figure. It consists of a cascade of strided 3D convolutions with SiLU activations. The process begins with a temporal compression followed by three stages of spatial compression, culminating in a projection to the model's hidden dimension. This design ensures a significant volume reduction while retaining essential layout information.

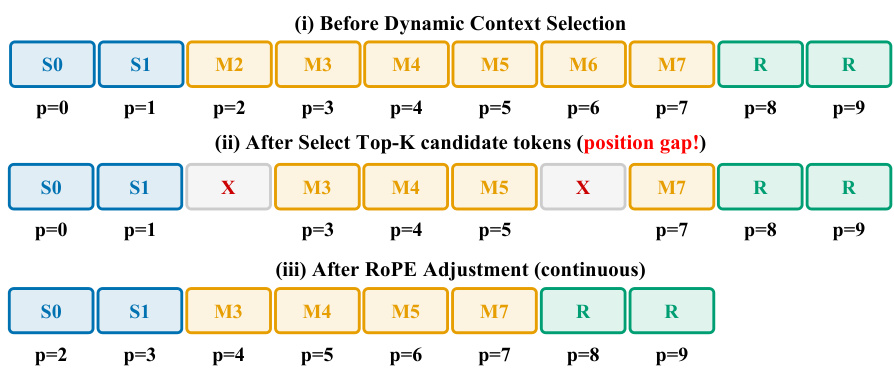
To further optimize memory usage, the system implements Dynamic Context Selection. Instead of attending to all compressed mid tokens, the model evaluates query-key affinities to route only the top-K most informative blocks. This selection process inevitably creates position gaps in the token sequence. To resolve this, the authors apply an incremental RoPE adjustment. Refer to the diagram illustrating the selection process to see how the position indices are re-aligned. Initially, the selection creates gaps where tokens are removed. The RoPE adjustment then shifts the positional embeddings of the remaining tokens to ensure continuous indices, allowing the transformer to maintain temporal coherence without full recomputation.
Finally, the training strategy involves end-to-end optimization of the HR compression layer. During the rollout phase, the compression module is integrated directly into the computational graph. This ensures that the compressed mid tokens are explicitly tailored to preserve semantic and structural cues necessary for downstream causal attention, rather than minimizing a generic reconstruction loss. This approach allows the model to generalize from short training sequences to long video generation with constant attention complexity.
Experiment
- Main experiments on 60s and 120s video generation validate that PackForcing achieves superior motion synthesis and temporal stability compared to baselines, maintaining high subject and background consistency without the severe degradation seen in other methods.
- Long-range consistency tests confirm that the sink token mechanism effectively anchors global semantics, preventing the compounding errors and semantic drift that typically occur in extended autoregressive generation.
- Ablation studies demonstrate that sink tokens are critical for balancing dynamic motion with semantic coherence, while dynamic context selection outperforms standard FIFO eviction by retaining highly attended historical blocks.
- Analysis of attention patterns reveals that information demand is distributed across the entire video history rather than being limited to recent frames, justifying the need for a compressed mid-buffer and global summary tokens.
- Qualitative evaluations show that the proposed architecture preserves fine visual details and complex continuous motion over two minutes, whereas competing methods suffer from color shifts, object duplication, or motion freezing.
- Efficiency analysis proves that the compression strategy bounds memory usage to a constant level regardless of video length, enabling long-horizon generation on single GPUs where uncompressed methods would fail.