HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
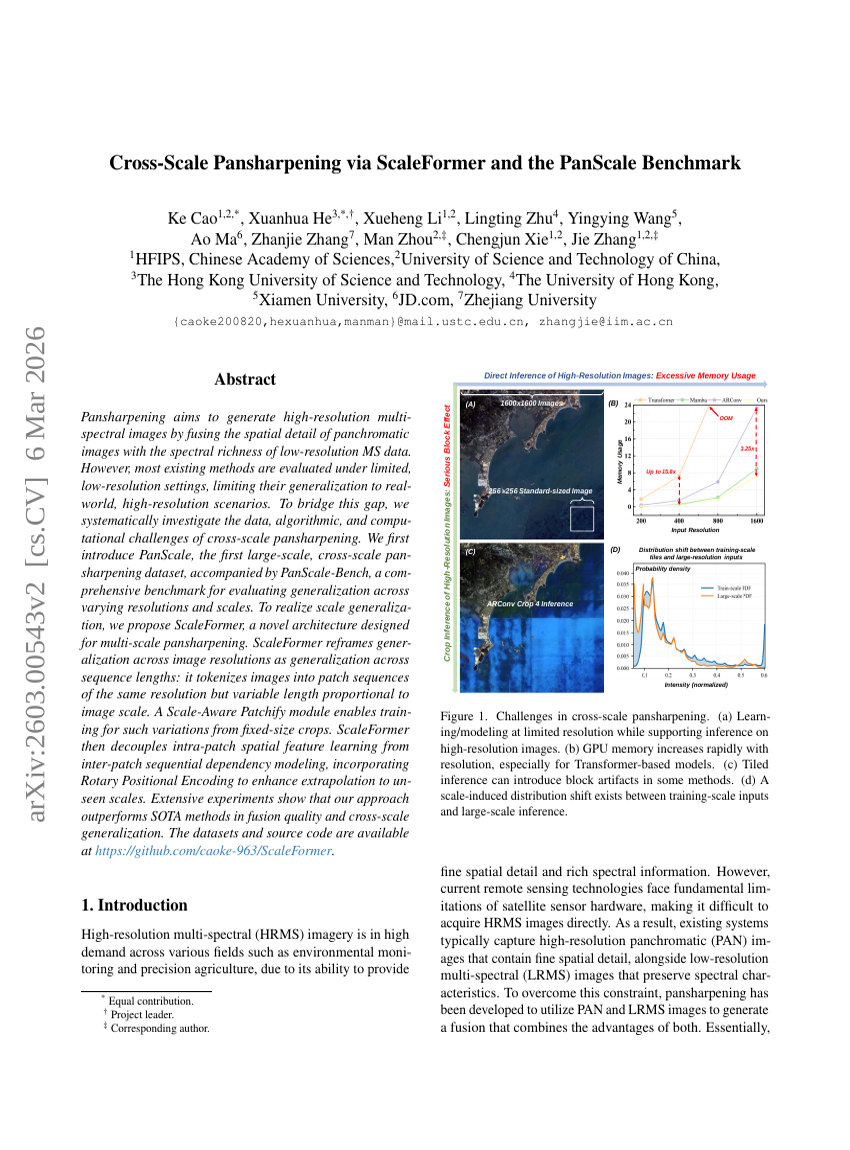
ScaleFormerとPanScaleベンチマークによるクロススケール・パンシャープニング

ParseBench: AI Agentのためのドキュメント解析ベンチマーク







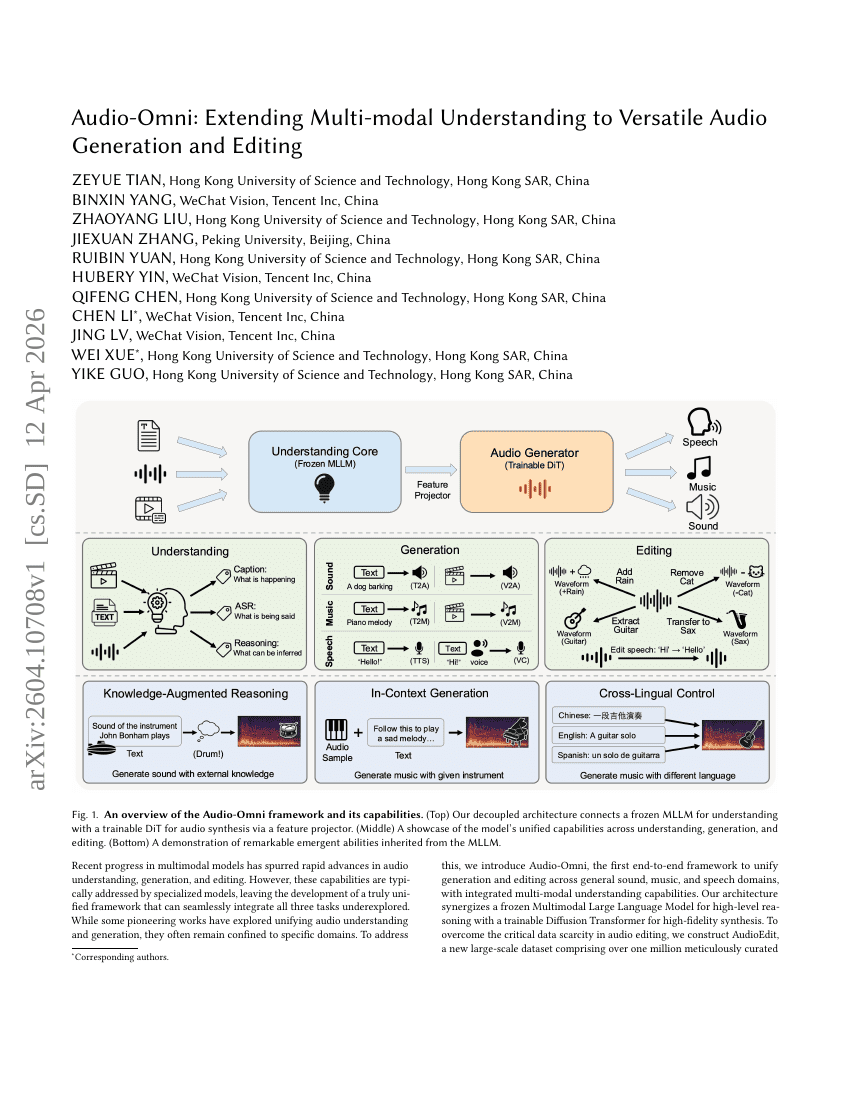



















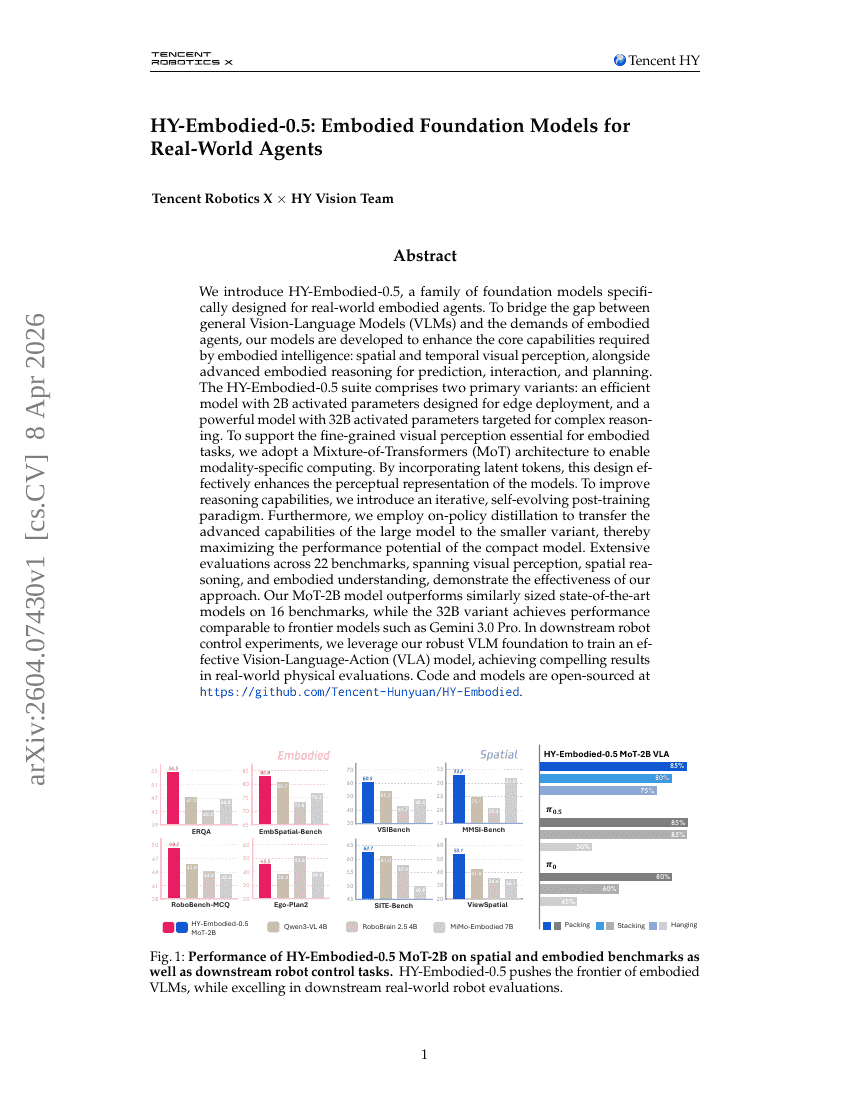
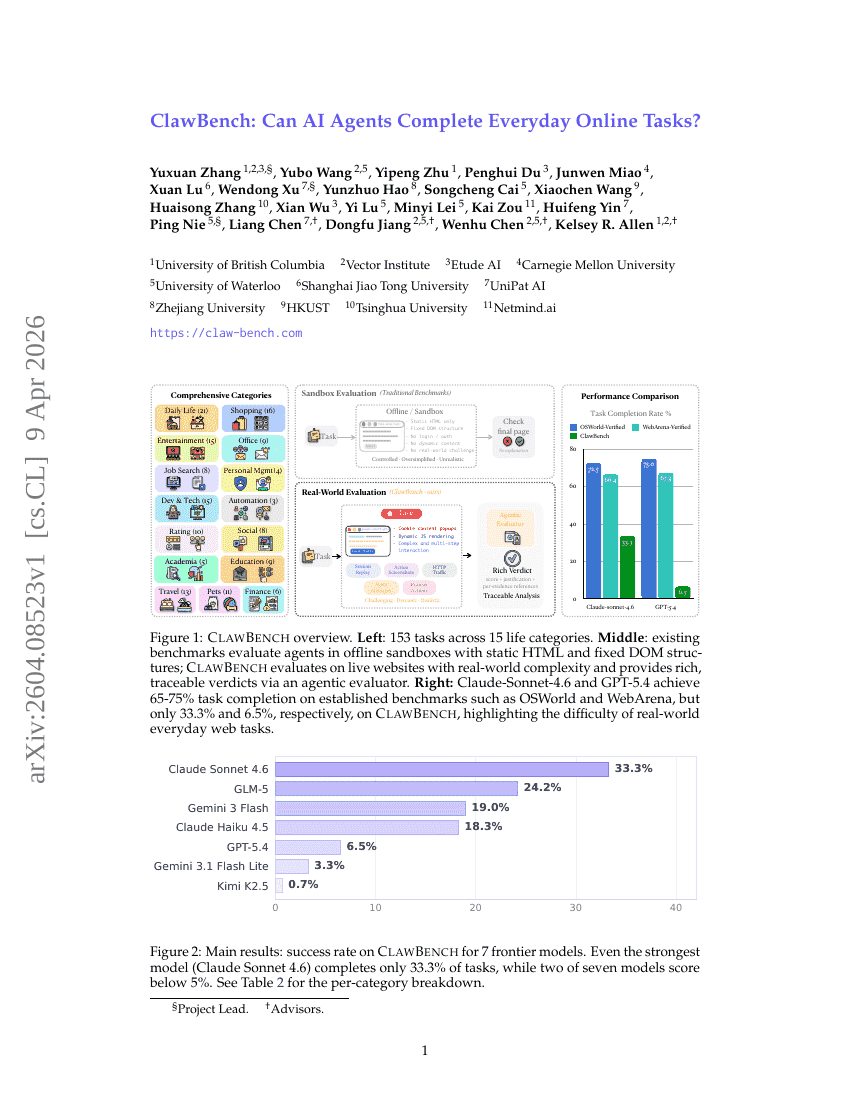

ScaleFormerとPanScaleベンチマークによるクロススケール・パンシャープニング
ParseBench: AI Agentのためのドキュメント解析ベンチマーク
メモリ・インテリジェンス Agent
PROPELLA-1:大規模なLLMデータキュレーションに向けたマルチプロパティ文書アノテーション
長文コンテキストにおける視覚的ドキュメント理解のための内面化されたReasoning
TurboQuant: Near-optimalな歪み率を実現するオンライン・ベクトル量子化(Online Vector Quantization)
BERT-as-a-Judge: 効率的なReference-Based LLM評価における、Lexical Methodに代わるロバストな代替手法
SPPO:長期間の推論タスクに向けたSequence-Level PPO
画面上のチューリングテスト:Mobile GUI Agentの人間らしさを評価するためのBenchmark
Audio-Omni:将多模态理解扩展至多功能 Audio Generation 与 Editing
大規模言語モデルにおける On-Policy Distillation の再考:現象論、メカニズム、およびレシピ
KnowRL: Minimal-Sufficient Knowledge Guidance を用いた Reinforcement Learning による LLM Reasoning の向上
Uni-ViGU: A Diffusion-Based Video Generator による、Video Generation と Understanding の統一に向けて
ClawGUI:一个用于 Training、Evaluating 以及 Deploying GUI Agents 的统一 Framework
TransformerにおけるAttention Sink:その活用、解釈、および緩和策に関するサーベイ
OmniShow:面向人机交互(Human-Object Interaction)视频生成的统一多模态 Condition 框架
「過去は過去ではない:Memory-Enhanced Dynamic Reward Shaping」
QuanBench+: LLMベースの量子コード生成に向けた、マルチフレームワーク統合Benchmark
ELT:ビジュアル生成のための弾性ループ型トランスフォーマー
ECHO: One-step Block Diffusionを用いた効率的な胸部X線レポート生成
Matrix-Game 3.0: Long-Horizon Memoryを備えた、リアルタイムかつストリーミング可能なインタラクティブWorld Model
EXAONE 4.5 技術報告書
RefineAnything:追求完美局部细节的多模态区域特定 Refinement 方法
FORGE:製造シナリオにおけるきめ細かなMultimodal Evaluation
WildDet3D:在野外场景中扩展 Promptable 3D Detection
Autoreason: 停止時期を判断可能な自己洗練(Self-Refinement)
ActiveGlasses: Ego-centricな人間のデモンストレーションからActive Visionを用いた操作学習を実現する手法
MegaStyle: 一貫したText-to-Image Style Mappingを通じて、多様かつスケーラブルなStyle Datasetを構築する手法
ご提示いただいたタイトルは、学術論文のタイトルとして非常に重要ですので、その文脈(AI・コンピュータビジョン分野のトップ会議やジャーナル)にふさわしい、格調高く正確な表現をご提案します。 翻訳結果は以下の通りです: 数字が語る時:Text-to-Video Diffusion Modelsにおけるテキスト内の数字表記と視覚的インスタンスの整合
【翻訳の解説(学術的観点から)】
When Numbers Speak: 文学的な表現ですが、論文のタイトルとしては「数字が語る時」あるいは「数字の意味するもの」といったニュアンスを含ませるのが一般的です。 Aligning: 機械学習の文脈では「整合(整合性を取る)」「アラインメント」と訳されます。ここでは、テキストと画像(動画)の内容を一致させることを指すため、「整合」という言葉を用いて学術的な響きを持たせています。 Textual Numerals and Visual Instances: 「Textual Numerals」はテキストに含まれる数字の表記(例:「3」や「three」)を指し、「Visual Instances」は動画内に現れる実際の物体(インスタンス)を指します。これらを「テキスト内の数字表記と視覚的インスタンス」と訳すことで、研究の対象を明確にしています。 Text-to-Video Diffusion Models: 指示通り、専門用語であるためそのまま英語で保持しています。
HY-Embodied-0.5:実世界における Agent のための Embodied Foundation Models
ClawBench:AI Agent 能否完成日常在线任务?
Reasoning SFTにおける汎化性能の再考:Optimization、Data、およびModel Capabilityに関する条件付き解析
メモリ・インテリジェンス Agent
PROPELLA-1:大規模なLLMデータキュレーションに向けたマルチプロパティ文書アノテーション
長文コンテキストにおける視覚的ドキュメント理解のための内面化されたReasoning
TurboQuant: Near-optimalな歪み率を実現するオンライン・ベクトル量子化(Online Vector Quantization)
BERT-as-a-Judge: 効率的なReference-Based LLM評価における、Lexical Methodに代わるロバストな代替手法
SPPO:長期間の推論タスクに向けたSequence-Level PPO
画面上のチューリングテスト:Mobile GUI Agentの人間らしさを評価するためのBenchmark
Audio-Omni:将多模态理解扩展至多功能 Audio Generation 与 Editing
大規模言語モデルにおける On-Policy Distillation の再考:現象論、メカニズム、およびレシピ
KnowRL: Minimal-Sufficient Knowledge Guidance を用いた Reinforcement Learning による LLM Reasoning の向上
Uni-ViGU: A Diffusion-Based Video Generator による、Video Generation と Understanding の統一に向けて
ClawGUI:一个用于 Training、Evaluating 以及 Deploying GUI Agents 的统一 Framework
TransformerにおけるAttention Sink:その活用、解釈、および緩和策に関するサーベイ
OmniShow:面向人机交互(Human-Object Interaction)视频生成的统一多模态 Condition 框架
「過去は過去ではない:Memory-Enhanced Dynamic Reward Shaping」
QuanBench+: LLMベースの量子コード生成に向けた、マルチフレームワーク統合Benchmark
ELT:ビジュアル生成のための弾性ループ型トランスフォーマー
ECHO: One-step Block Diffusionを用いた効率的な胸部X線レポート生成
Matrix-Game 3.0: Long-Horizon Memoryを備えた、リアルタイムかつストリーミング可能なインタラクティブWorld Model
EXAONE 4.5 技術報告書
RefineAnything:追求完美局部细节的多模态区域特定 Refinement 方法
FORGE:製造シナリオにおけるきめ細かなMultimodal Evaluation
WildDet3D:在野外场景中扩展 Promptable 3D Detection
Autoreason: 停止時期を判断可能な自己洗練(Self-Refinement)
ActiveGlasses: Ego-centricな人間のデモンストレーションからActive Visionを用いた操作学習を実現する手法
MegaStyle: 一貫したText-to-Image Style Mappingを通じて、多様かつスケーラブルなStyle Datasetを構築する手法
ご提示いただいたタイトルは、学術論文のタイトルとして非常に重要ですので、その文脈(AI・コンピュータビジョン分野のトップ会議やジャーナル)にふさわしい、格調高く正確な表現をご提案します。 翻訳結果は以下の通りです: 数字が語る時:Text-to-Video Diffusion Modelsにおけるテキスト内の数字表記と視覚的インスタンスの整合
【翻訳の解説(学術的観点から)】
When Numbers Speak: 文学的な表現ですが、論文のタイトルとしては「数字が語る時」あるいは「数字の意味するもの」といったニュアンスを含ませるのが一般的です。 Aligning: 機械学習の文脈では「整合(整合性を取る)」「アラインメント」と訳されます。ここでは、テキストと画像(動画)の内容を一致させることを指すため、「整合」という言葉を用いて学術的な響きを持たせています。 Textual Numerals and Visual Instances: 「Textual Numerals」はテキストに含まれる数字の表記(例:「3」や「three」)を指し、「Visual Instances」は動画内に現れる実際の物体(インスタンス)を指します。これらを「テキスト内の数字表記と視覚的インスタンス」と訳すことで、研究の対象を明確にしています。 Text-to-Video Diffusion Models: 指示通り、専門用語であるためそのまま英語で保持しています。
HY-Embodied-0.5:実世界における Agent のための Embodied Foundation Models
ClawBench:AI Agent 能否完成日常在线任务?
Reasoning SFTにおける汎化性能の再考:Optimization、Data、およびModel Capabilityに関する条件付き解析