HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

LiveTalk:改善されたオンポリシー蒸留を用いたリアルタイムマルチモーダル相互作用型ビデオディフュージョン

Mixture-of-Expertsにおける補助損失を用いたエキスパートとルーターの結合




























LiveTalk:改善されたオンポリシー蒸留を用いたリアルタイムマルチモーダル相互作用型ビデオディフュージョン
Mixture-of-Expertsにおける補助損失を用いたエキスパートとルーターの結合
LongFly:時空間的コンテキスト統合を用いた長期予測UAV視覚言語ナビゲーション
注目はあなたが必要なものではない
SlideTailor:科学論文向けのパーソナライズ型プレゼンテーションスライド生成
InSight-o3:汎用視覚検索によるマルチモーダル基盤モデルの強化
InsertAnywhere:4Dシーン幾何と拡散モデルを橋渡しするリアルな動画オブジェクト挿入
マインドスケープ認識型リtrieval-Augmented Generationによる長文脈理解の向上
大規模言語モデルにおける短文の事実性の測定
DeepSearchQA:深い研究エージェントにおける包括性のギャップを埋める
MEM1:長期間エージェントの効率化のための記憶と推論の連携学習
AI-Trader:リアルタイム金融市場における自律型エージェントのベンチマーク評価
潜在的陰在視覚的推論
LLMのペルソナが手法のベンチマーキングにおけるフィールド実験の代替としての役割を果たす可能性
DataFlow:データ中心型AI時代における統一されたデータ準備およびワークフロー自動化を実現するLLM駆動型フレームワーク
HiStream:冗長性除去ストリーミングを用いた効率的な高解像度ビデオ生成
TokSuite:トークナイザーの選択が言語モデルの行動に与える影響を測定する
Nemotron 3 Nano:エージェンティック推論向けに最適化されたオープンで効率的なMixture-of-ExpertsハイブリッドMamba-Transformerモデル
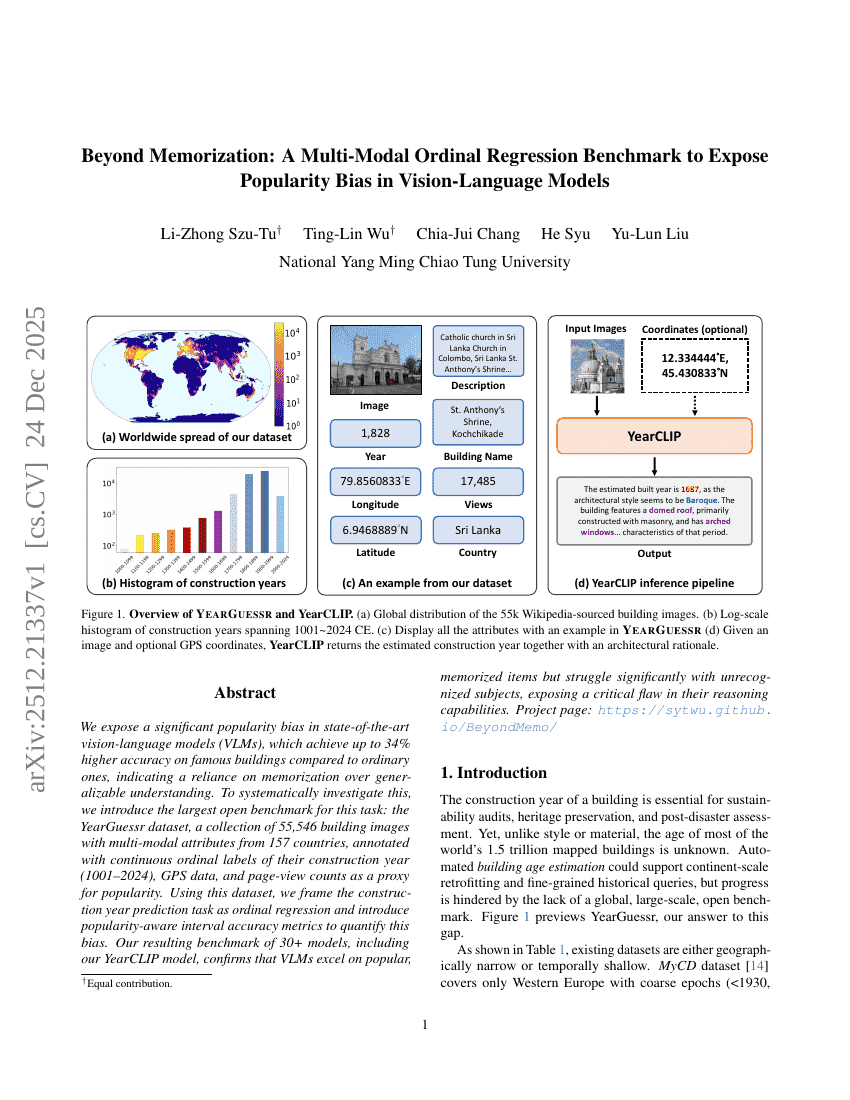
記憶を超えて:視覚言語モデルにおける人気バイアスを露呈するマルチモーダル順序回帰ベンチマーク
DreaMontage:任意フレームガイド付きワンショット動画生成
T2AV-Compass:テキストから音声・映像生成への統合的評価へ向けて
TongSIM:知能機械のシミュレーションを目的とした汎用プラットフォーム
Qwen-Image-Layered:レイヤー分解による本質的な編集可能性の実現へ
RoboSafe:実行可能安全論理を用いた身体化エージェントの保護
NHSにおけるプライマリケアにおけるLLM薬物療法安全レビューの実世界評価
複数LLMを用いた主題分析:二重信頼性指標を用いた定性的研究の検証—CohenのKappaと意味的類似度の統合
閉ループ・ワールドモデリングを用いたビデオアバターにおけるアクティブインテリジェンス
FaithLens:忠実性ホワリュネーションの検出と解釈
SAM Audio:音声におけるアノテーションのための「Anything」モデル
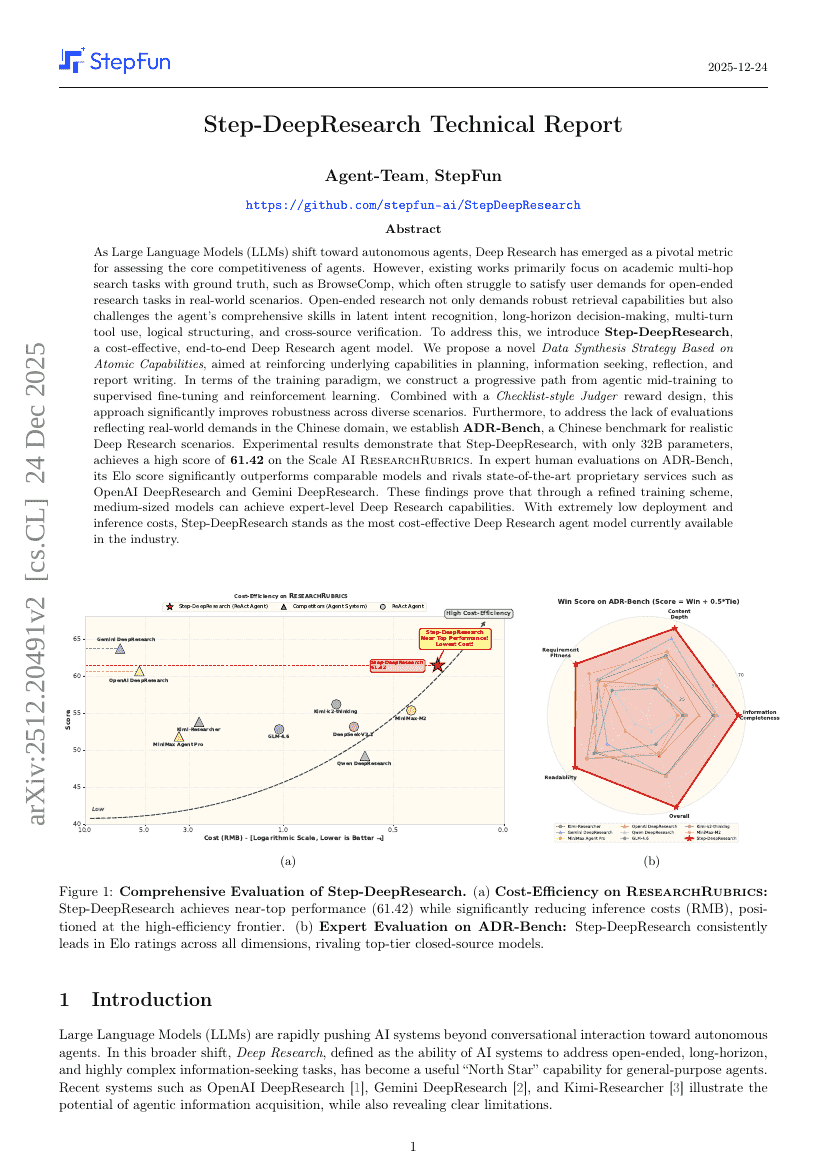
ステップ・ディープリサーチ 技術報告書
SpatialTree:MLLMにおける空間能力の分岐構造
セマンティックジェン:セマンティック空間における動画生成
LongFly:時空間的コンテキスト統合を用いた長期予測UAV視覚言語ナビゲーション
注目はあなたが必要なものではない
SlideTailor:科学論文向けのパーソナライズ型プレゼンテーションスライド生成
InSight-o3:汎用視覚検索によるマルチモーダル基盤モデルの強化
InsertAnywhere:4Dシーン幾何と拡散モデルを橋渡しするリアルな動画オブジェクト挿入
マインドスケープ認識型リtrieval-Augmented Generationによる長文脈理解の向上
大規模言語モデルにおける短文の事実性の測定
DeepSearchQA:深い研究エージェントにおける包括性のギャップを埋める
MEM1:長期間エージェントの効率化のための記憶と推論の連携学習
AI-Trader:リアルタイム金融市場における自律型エージェントのベンチマーク評価
潜在的陰在視覚的推論
LLMのペルソナが手法のベンチマーキングにおけるフィールド実験の代替としての役割を果たす可能性
DataFlow:データ中心型AI時代における統一されたデータ準備およびワークフロー自動化を実現するLLM駆動型フレームワーク
HiStream:冗長性除去ストリーミングを用いた効率的な高解像度ビデオ生成
TokSuite:トークナイザーの選択が言語モデルの行動に与える影響を測定する
Nemotron 3 Nano:エージェンティック推論向けに最適化されたオープンで効率的なMixture-of-ExpertsハイブリッドMamba-Transformerモデル
記憶を超えて:視覚言語モデルにおける人気バイアスを露呈するマルチモーダル順序回帰ベンチマーク
DreaMontage:任意フレームガイド付きワンショット動画生成
T2AV-Compass:テキストから音声・映像生成への統合的評価へ向けて
TongSIM:知能機械のシミュレーションを目的とした汎用プラットフォーム
Qwen-Image-Layered:レイヤー分解による本質的な編集可能性の実現へ
RoboSafe:実行可能安全論理を用いた身体化エージェントの保護
NHSにおけるプライマリケアにおけるLLM薬物療法安全レビューの実世界評価
複数LLMを用いた主題分析:二重信頼性指標を用いた定性的研究の検証—CohenのKappaと意味的類似度の統合
閉ループ・ワールドモデリングを用いたビデオアバターにおけるアクティブインテリジェンス
FaithLens:忠実性ホワリュネーションの検出と解釈
SAM Audio:音声におけるアノテーションのための「Anything」モデル
ステップ・ディープリサーチ 技術報告書
SpatialTree:MLLMにおける空間能力の分岐構造
セマンティックジェン:セマンティック空間における動画生成