Command Palette
Search for a command to run...
セマンティックジェン:セマンティック空間における動画生成
セマンティックジェン:セマンティック空間における動画生成
概要
最先端の動画生成モデルは、通常、VAE(変分自己符号化器)空間における動画潜在変数の分布を学習し、VAEデコーダーを用いてそれらをピクセルにマッピングする。このアプローチは高品質な動画生成を可能にするものの、特に長時間の動画生成においては収束が遅く、計算コストが非常に高くなるという課題がある。本論文では、これらの制約を克服するため、意味空間(semantic space)において動画を生成する新規手法であるSemanticGenを提案する。我々の核心的な洞察は、動画に内在する冗長性を考慮すると、低レベルの動画トークンを双向注意力(bi-directional attention)で直接モデル化するのではなく、まずコンパクトで高レベルな意味空間で全体的な構成計画(global planning)を行い、その後に高周波成分の詳細を追加する方が効率的であるということである。SemanticGenは二段階の生成プロセスを採用している。第一段階では、拡散モデル(diffusion model)がコンパクトな意味的動画特徴を生成し、これが動画の全体的なレイアウトを定義する。第二段階では、この意味特徴を条件として、別の拡散モデルがVAE潜在変数を生成し、最終的な出力画像を合成する。実験結果から、意味空間における生成はVAE潜在空間における生成に比べてより迅速な収束を示すことが明らかになった。さらに、長時間動画生成への拡張においても、本手法は効果的かつ計算的に効率的であることが確認された。広範な実験により、SemanticGenが高品質な動画を生成し、最先端の手法および強力なベースラインを上回ることを実証した。
One-sentence Summary
Researchers from Zhejiang University, Kuaishou Technology (Kling Team), and CUHK propose SemanticGen, a two-stage video generation framework operating in semantic space rather than VAE latents. It first creates compact semantic features for global video planning using diffusion, then generates VAE latents conditioned on these features, accelerating convergence and enabling efficient high-quality one-minute video synthesis while outperforming prior VAE-based methods.
Key Contributions
- Current video generative models suffer from slow convergence and high computational costs for long videos due to modeling low-level video tokens with bidirectional attention in the VAE latent space, which becomes impractical for extended sequences.
- SemanticGen introduces a two-stage diffusion framework that first generates compact semantic features for global video layout planning, then conditions VAE latent generation on these features to add high-frequency details, leveraging video redundancy for efficiency.
- Experiments show this approach achieves faster convergence than VAE latent space generation and outperforms state-of-the-art methods in video quality while scaling effectively to long video generation scenarios.
Introduction
Video generation models face a critical trade-off: diffusion-based methods produce high-fidelity short videos but struggle with long sequences due to the computational limits of processing all frames simultaneously via bidirectional attention, while autoregressive approaches scale better for long videos yet deliver inferior quality. Hybrid methods attempt to bridge this gap but still underperform pure diffusion models. Separately, research shows that integrating semantic representations—like those from pre-trained encoders—accelerates training and boosts image generation quality compared to raw latent spaces. The authors address both challenges by proposing a novel diffusion-based video generation framework. They fine-tune diffusion models to learn compressed semantic representations, which are then mapped to the VAE latent space. This approach achieves faster convergence than direct VAE latent generation and effectively scales to long video synthesis, overcoming prior scalability barriers without sacrificing fidelity.
Dataset
The authors use two distinct datasets for short and long video generation:
-
Dataset composition and sources:
The training data comprises an internal text-video pair dataset for short videos and a constructed long-video dataset sourced from movie and TV show clips. -
Key subset details:
- Short video subset: Uses internal text-video pairs (exact size unspecified).
- Long video subset: Created by splitting movie/TV clips into 60-second segments, with text prompts auto-generated via an internal captioner. No explicit filtering rules are detailed.
-
Data usage in training:
- Frames are sampled at 24 fps for VAE input and 1.6 fps for the semantic encoder during training.
- The semantic encoder leverages the vision tower from Qwen2.5-VL-72B-Instruct.
- Training focuses on text-to-video generation without specified mixture ratios or split proportions.
-
Processing specifics:
- No cropping strategy is mentioned.
- Metadata (text prompts) for long videos is synthetically constructed via the internal captioner.
- Frame-rate differentiation (24 fps vs. 1.6 fps) tailors inputs to the VAE and semantic encoder workflows.
Method
The authors leverage a two-stage diffusion-based framework called SemanticGen to generate videos by first modeling high-level semantic representations and then refining them into VAE latents. This design addresses the computational inefficiency and slow convergence of conventional methods that operate directly in the VAE latent space. The overall architecture is structured to decouple global scene planning from fine-grained detail synthesis, enabling scalable and efficient generation, particularly for long videos.
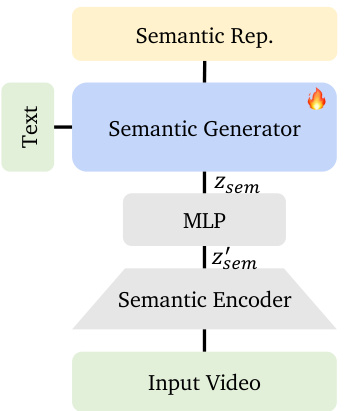
In the first stage, a semantic generator is trained to produce compact semantic representations conditioned on text prompts. These representations are derived from an off-the-shelf video semantic encoder — specifically, the vision tower of Qwen-2.5-VL — which processes input videos by downsampling frames and compressing spatial patches into a low-dimensional token sequence. To improve training stability and convergence, the authors introduce a lightweight MLP that compresses the high-dimensional semantic features zsem′ into a lower-dimensional latent space zsem, parameterized as a Gaussian distribution. The MLP outputs mean and variance vectors, and a KL divergence term is added to the loss to regularize the compressed space. This compressed representation is then used as conditioning for the second stage.
Refer to the framework diagram for the semantic generation pipeline. The semantic generator takes a text prompt as input and outputs zsem, which is further processed by the MLP to yield zsem′, the compressed semantic embedding used for conditioning. This design ensures that the semantic space is both compact and amenable to diffusion sampling.
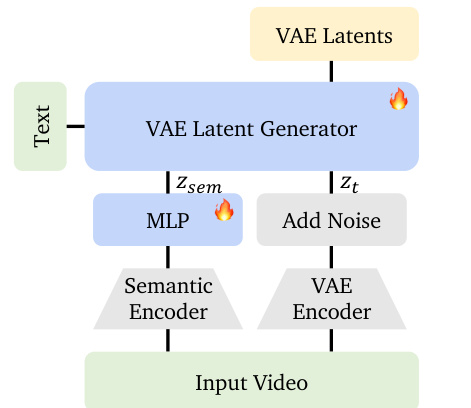
In the second stage, a video diffusion model generates VAE latents conditioned on the compressed semantic representation. During training, the model receives concatenated inputs: the noised VAE latent zt and the semantic embedding zsem. This in-context conditioning allows the diffusion model to leverage high-level semantic cues — such as object motion and scene layout — while generating low-level visual details. The authors observe that this conditioning preserves global structure and dynamics while allowing variation in texture and color, as demonstrated in reference-based generation experiments.
As shown in the figure below, the VAE latent generator integrates the semantic encoder and MLP to extract and compress semantic features from input videos, which are then injected into the diffusion model alongside the noised VAE latents. During inference, the semantic generator produces zsem from text, and noise is added to it to bridge the training-inference gap, following practices from RAE.
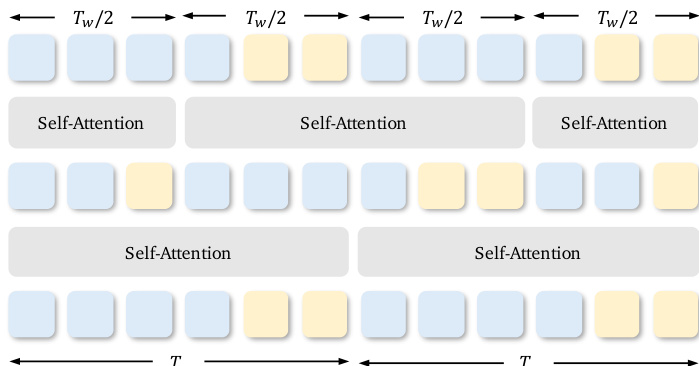
For long video generation, SemanticGen employs a hybrid attention strategy to manage computational complexity. In the semantic space, full self-attention is applied to maintain global consistency across scenes and characters. When mapping to the VAE latent space, shifted-window attention is used to limit quadratic growth in compute cost. The authors interleave VAE latent tokens and semantic tokens within attention windows of size Tw, shifting the window by Tw/2 at odd layers. This design ensures that the semantic space — which is 16x more compressed than the VAE space — remains tractable while enabling high-fidelity reconstruction.
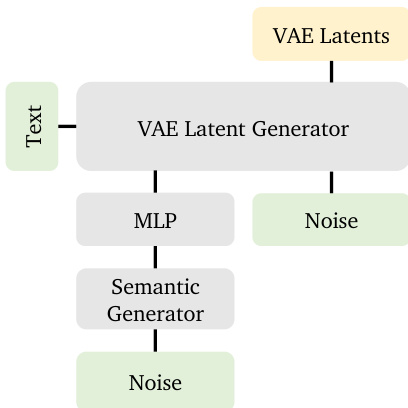
The inference pipeline integrates both stages: the semantic generator produces zsem from text, which is then fed into the VAE latent generator to produce the final video. The entire process is illustrated in the overall framework diagram, which highlights the sequential nature of semantic-to-latent generation.
The base diffusion model follows the Rectified Flow framework, with the forward process defined as zt=(1−t)z0+tϵ, where ϵ∼N(0,I). Training minimizes the Conditional Flow Matching loss LLCM=Et,p+(z,ϵ),p(ϵ)∥vΘ(zt,t)−ut(z0∣ϵ)∥22, and inference uses Euler discretization: zt=zt−1+vΘ(zt−1,t)⋅Δt. This foundation enables efficient sampling while preserving temporal coherence.
The authors emphasize that SemanticGen is not tied to a specific semantic encoder; alternatives such as V-JEPA 2, VideoMAE 2, or 4DS can be substituted. The framework’s modularity and reliance on pre-trained semantic encoders make it adaptable to evolving video understanding models while maintaining efficiency and quality in generation.
Experiment
- Validated semantic space compression: Using an 8-dimensional representation achieved the highest VBench scores, reducing artifacts and broken frames compared to higher-dimensional variants (64-dim and uncompressed).
- Confirmed faster convergence in semantic space: Training on pre-trained semantic representations converged significantly faster than modeling compressed VAE latents, producing coherent videos within the same training steps where VAE-based approaches yielded only coarse color patches.
- Outperformed state-of-the-art in long video generation: Surpassed all baselines (including MAGI-1, SkyReels-V2, and continued-training variants) in temporal consistency and reduced drifting issues, achieving lower ΔdriftM scores and maintaining stable backgrounds without color shifts.
- Matched SOTA in short video quality: Achieved comparable VBench metrics to leading methods while demonstrating superior text adherence (e.g., correctly generating specific motions like head turns or melting snowflakes missed by baselines).
The authors evaluate the impact of semantic space compression on video generation quality by comparing models trained with different output dimensions. Results show that compressing the semantic representation to lower dimensions (dim=8) improves consistency, smoothness, and aesthetic quality compared to no compression (dim=2048), with the dim=8 variant achieving the highest scores across most metrics. This indicates that dimensionality reduction enhances both convergence and output fidelity in the semantic generation pipeline.

The authors evaluate SemanticGen against baselines using quantitative metrics for long video generation, showing it achieves the highest subject consistency and motion smoothness while maintaining strong background consistency and minimal temporal flickering. SemanticGen outperforms Hunyuan-Video and Wan2.1-T2V-14B in subject consistency and matches or exceeds them in other stability metrics, though it scores slightly lower than Wan2.1-T2V-14B in imaging and aesthetic quality. Results confirm SemanticGen’s effectiveness in preserving long-term coherence without significant degradation in visual fidelity.

SemanticGen outperforms baseline methods across multiple video quality metrics, achieving the highest scores in subject consistency, background consistency, motion smoothness, and imaging quality. It also demonstrates the lowest drifting metric (Δ_drift^M), indicating superior long-term temporal stability compared to alternatives like SkyReels-V2, Self-Forcing, LongLive, and Base-CT-Swin.
