Command Palette
Search for a command to run...
FaithLens:忠実性ホワリュネーションの検出と解釈
FaithLens:忠実性ホワリュネーションの検出と解釈
概要
大規模言語モデル(LLM)の出力に忠実性の幻覚(faithfulness hallucination)が含まれているかどうかを識別することは、情報検索補強生成や要約などの実世界応用において極めて重要である。本論文では、忠実性の幻覚を効率的かつ効果的に検出できるFaithLensを提案する。このモデルは、二値予測とそれに伴う説明を同時に提供することで、信頼性を向上させることを目的としている。実現のため、まず高度なLLMを用いて説明付きの訓練データを合成し、ラベルの正確性、説明の質、データの多様性を確保するための明確なデータフィルタリング戦略を適用する。次に、こうして精査された訓練データ上でモデルをファインチューニングし、冷スタート(cold start)を実現した後、ルールベースの強化学習によりさらに最適化を行う。この際、予測の正しさと説明の質の両方に報酬を与えることで、モデルの性能を向上させる。12の多様なタスクにおける実験結果から、8Bパラメータ規模のFaithLensがGPT-4.1やo3といった最先端モデルを上回る性能を発揮することが示された。さらに、FaithLensは高品質な説明を生成でき、信頼性、効率性、有効性の優れたバランスを実現している。
One-sentence Summary
Tsinghua University et al. introduce FaithLens, an 8B-parameter cost-efficient hallucination detector that jointly predicts faithfulness and generates explanations for LLM outputs using synthetically curated training data and rule-based reinforcement learning, outperforming GPT-4.1 in retrieval-augmented generation and summarization tasks while balancing trustworthiness and effectiveness.
Key Contributions
- FaithLens addresses the critical challenge of detecting faithfulness hallucinations in LLM outputs for real-world applications like retrieval-augmented generation and summarization, where existing methods lack explainability and exhibit inconsistent cross-task performance despite the need for trustworthy detection.
- The model introduces a novel two-stage training approach: synthesizing high-quality explanation-rich data via advanced LLMs with strict filtering for label correctness and diversity, followed by fine-tuning and rule-based reinforcement learning that optimizes both prediction accuracy and explanation quality.
- Evaluated across 12 diverse tasks, the 8B-parameter FaithLens outperforms advanced models including GPT-4.1 and o3 while generating high-quality explanations, demonstrating superior effectiveness, efficiency, and trustworthiness without relying on costly API-based detectors.
Introduction
Large language models frequently generate faithfulness hallucinations—outputs inconsistent with provided input context like retrieved documents or source text—which undermine reliability in critical applications such as retrieval-augmented generation and summarization. Prior detection methods face significant limitations: approaches using advanced LLMs for evaluation incur high computational costs, while smaller NLI-based models lack robustness across diverse tasks and domains. Crucially, existing detectors provide only binary hallucination labels without explanations, hindering user trust and practical debugging. The authors leverage high-quality synthetic data refined through strict filtering and rule-based reinforcement learning to train FaithLens, a compact detection model that delivers explainable judgments while maintaining cross-task effectiveness and operational efficiency.
Dataset
The authors synthesize training data using large reasoning models (LRMs) like DeepSeek-V3.2-Think. They prompt the LRM with a document and claim from open-source datasets (Lei et al., 2025), generating chain-of-thought reasoning, explanations, and labels for cold-start supervised fine-tuning (SFT).
For evaluation, they use 12 cleaned datasets from LLM-AggreFact and HoVer, adopting Seo et al.’s refined versions to address label ambiguity (9.1% of examples) and mislabeling (6.6% of examples). Key subsets include:
- Agg-CNN & Agg-XSum: Focus on hallucination detection in SOTA summarization outputs (CNN/DM and XSum datasets), using summaries from advanced finetuned models.
- ClaimVerify: Assesses factual support for search engine responses against cited documents.
- ExpertQA: Verifies system responses (closed-book or RAG-based) against expert-curated queries and cited/retrieved documents.
- FC-GPT: Decomposes LLM responses into atomic facts, decontextualizing them for standalone verification.
- HoVer: Tests complex, multi-hop reasoning requiring evidence from up to four Wikipedia articles, with long-range dependency challenges.
The synthesized training data (with explanations) exclusively fuels the initial SFT stage. Evaluation strictly uses the cleaned benchmark subsets without further processing or cropping. Metadata like sentence-level annotations and hallucination intensity labels are inherited directly from the source datasets.
Method
The authors leverage a two-stage training pipeline to build FaithLens, a specialized 8B-parameter model designed for joint faithfulness hallucination detection and explanation generation. The overall framework, as depicted in the figure below, begins with a cold-start supervised fine-tuning (SFT) phase using synthetically generated data, followed by a rule-based reinforcement learning (RL) stage to refine both prediction accuracy and explanation quality.
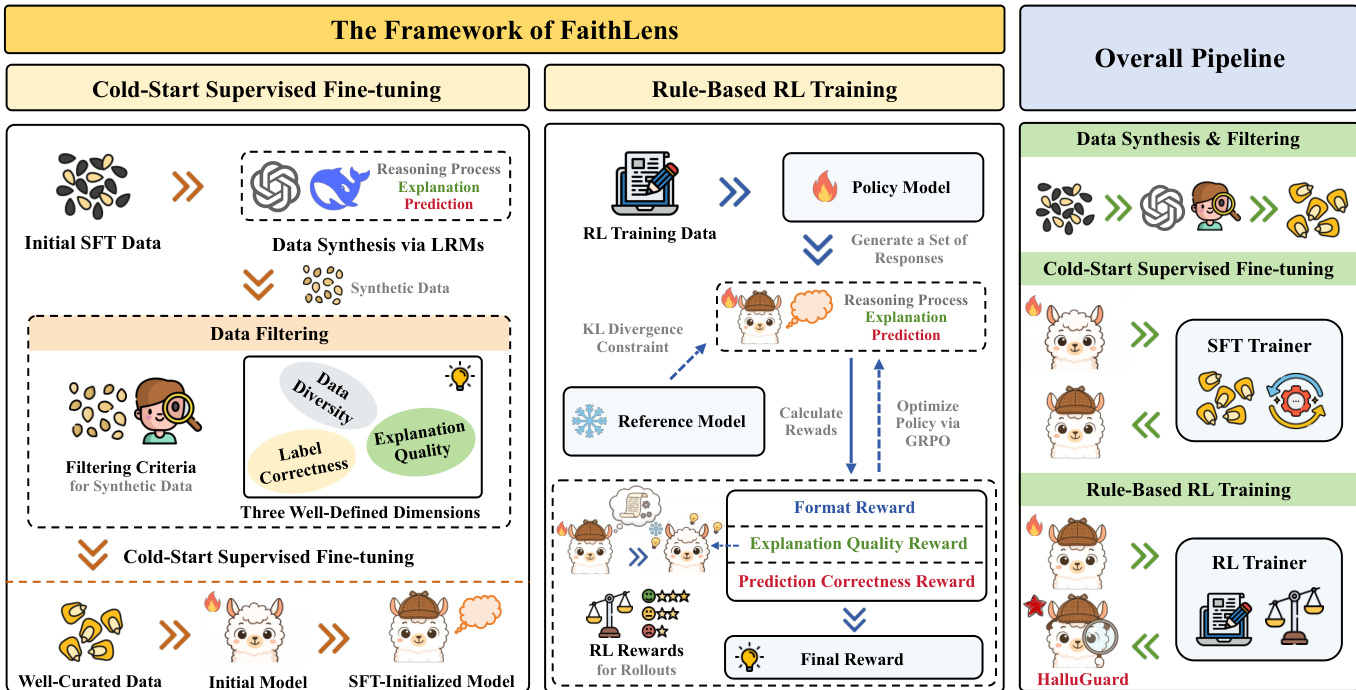
In the first stage, the authors synthesize training data by querying large language models (LLMs) with a structured prompt that enforces a specific output format: a chain-of-thought (CoT) reasoning trace, followed by a textual explanation, and finally a binary prediction. The prompt, shown in the figure below, instructs the LLM to first reason step-by-step within <tool_call> tags, then provide an explanation within <reason> tags, and conclude with a “Yes” or “No” answer wrapped in <answer> tags.

To ensure the quality of this synthetic data, the authors implement a three-pronged filtering strategy. First, they verify label correctness by comparing the LLM-generated prediction y^ against the ground-truth label ygt from the original dataset, discarding any sample where y^=ygt. Second, they assess explanation quality by measuring whether the generated explanation e^ reduces the perplexity of the target model (e.g., Llama-3.1-8B-Instruct) when predicting the correct label, compared to its perplexity without the explanation. This is formalized as Fexp(s^)=I{PPLw. exp<PPLw/o. exp}. Third, to preserve data diversity and prevent overfitting to simple cases, they cluster document-claim pairs using sentence embeddings and the K-Medoids algorithm, then retain only samples that improve the model’s performance on a diverse probe set of medoid samples. The filtered dataset D is then used to fine-tune the base model via the SFT objective LSFT=−Es^∼D[logM(cot,e^,ygt∣doc,c)].
In the second stage, the authors apply rule-based reinforcement learning using the GRPO algorithm to further optimize the SFT-initialized model. For each input, the model generates a group of G candidate responses, each containing a prediction and explanation. These candidates are evaluated using a composite reward function Rfinal=Rpred+Rexp+Rformat. The prediction correctness reward Rpred is 1 if the model’s prediction matches the ground truth, and 0 otherwise. The explanation quality reward Rexp is 1 if a novice-level model (e.g., an untuned Llama-3.1-8B-Instruct) can correctly predict the label when conditioned on the generated explanation, and 0 otherwise. The format reward Rformat ensures the output adheres to the required structure. The GRPO objective then uses these rewards to compute advantages and update the policy while constraining divergence from the reference model.
The training protocol, as shown in the figure below, uses the same prompt structure for data synthesis as for inference, ensuring consistency. The explanation quality filtering process, also illustrated, involves evaluating whether the explanation enables a downstream model to make the correct prediction, thereby serving as an implicit, rule-based quality signal.

This dual-stage approach allows FaithLens to produce not only accurate binary predictions but also high-quality, informative explanations that enhance user trust, all while maintaining cost efficiency.
Experiment
- Achieved state-of-the-art macro-F1 scores across 12 tasks on refined LLM-AggreFact and HoVer benchmarks, surpassing specialized models (FactCG, ClearCheck) and advanced LLMs (GPT-4.1, o3) while demonstrating superior stability and generalization.
- Generated highest-quality explanations validated by GPT-4.1 judging, scoring best in readability, helpfulness, and informativeness versus all baselines, with human evaluation confirming superiority over GPT-4o in helpfulness and informativeness.
- Delivered optimal inference efficiency at $0.8/GPU-hour, achieving SOTA performance with the lowest cost among comparable models.
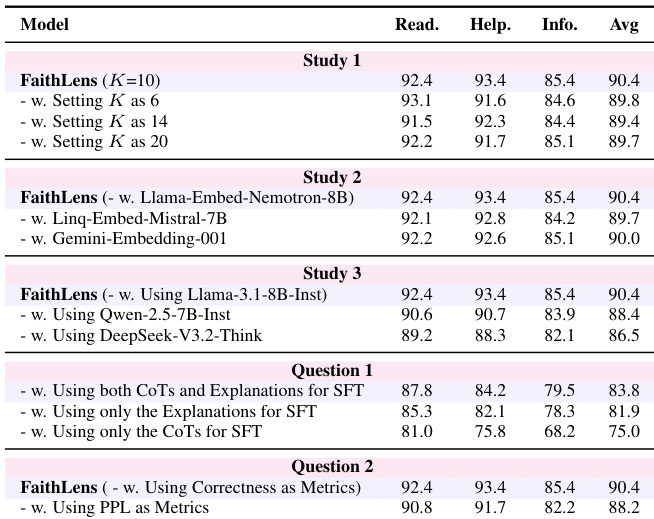
- Ablation studies confirmed critical contributions from label correctness filtering, explanation quality filtering, data diversity filtering (K=10), and rule-based RL with composite rewards to both performance and explainability.
- Demonstrated consistent performance gains across foundation models (Qwen-2.5-Inst, Llama-3.1-Inst) and validated claim decomposition as beneficial despite increased inference time.
The authors evaluate FaithLens under various parameter settings and design variants, showing that performance remains stable across different cluster counts and embedding models. Using both CoTs and explanations during SFT yields significantly better results than using either component alone, and correctness-based rewards outperform perplexity-based metrics in RL. FaithLens consistently achieves high explainability scores, with minor drops only when using heterologous or expert-level models for reward computation.
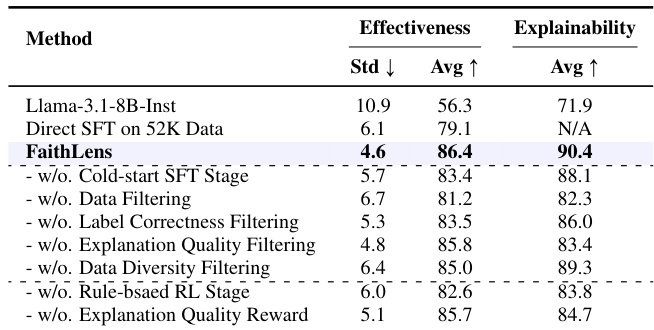
The authors use a multi-stage data filtering strategy to refine training data for FaithLens, progressively reducing the dataset from 52,268 initial samples to 28,643 final samples by applying label correctness, explanation quality, and data diversity filters. Results show that this filtering improves model performance while maintaining efficiency, as FaithLens achieves state-of-the-art results with lower inference cost and without relying on private data. The final training set includes 11,929 samples for SFT and 16,714 for RL, demonstrating the method’s ability to retain high-quality, diverse data for effective hallucination detection.

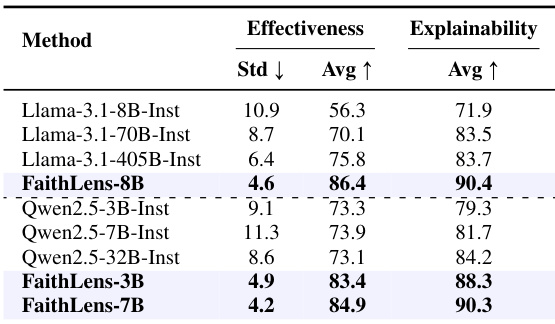
FaithLens achieves state-of-the-art effectiveness and explainability, outperforming baseline models with a macro-F1 of 86.4 and an explainability score of 90.4. Ablation results confirm that each component—cold-start SFT, data filtering, rule-based RL, and explanation quality reward—contributes meaningfully to performance, as removing any degrades either effectiveness or explainability. The model also demonstrates strong stability across tasks, with the lowest standard deviation (4.6) among compared methods.
Results show that FaithLens outperforms both advanced LLMs and specialized detection models in explanation quality across readability, helpfulness, and informativeness when evaluated using GPT-5-mini as a judge, with gains of +18.7, +23.5, and +18.0 points respectively over the base Llama-3.1-8B-Inst model. Ablation studies confirm that each component—cold-start SFT, data filtering, and explanation quality reward—contributes meaningfully to performance, while generalization tests demonstrate consistent improvements across different foundation models including Qwen-2.5 series.
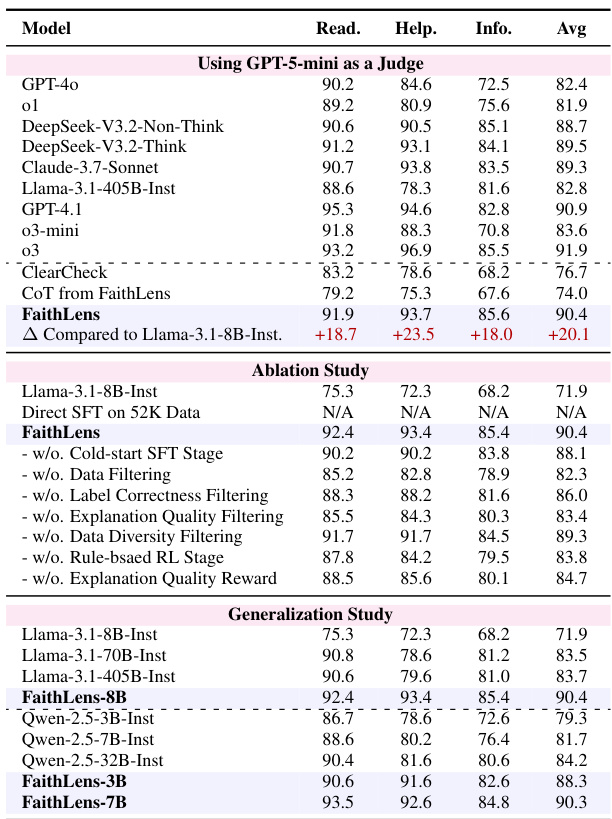
The authors use FaithLens to train detection models on Llama-3.1-8B-Inst, Qwen-2.5-3B-Inst, and Qwen-2.5-7B-Inst backbones, achieving state-of-the-art effectiveness and explainability scores across all variants. Results show FaithLens-8B attains the highest average effectiveness (86.4) and explainability (90.4) while reducing standard deviation to 4.6, indicating superior stability and performance. FaithLens-3B and FaithLens-7B also outperform their base models, confirming the method’s generalization across model sizes.