HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

人間がループ内に参加する推論型大規模言語モデルエージェントを用いた自動ステレオタクティック放射線外科学計画

LongVideoAgent:長時間動画を用いたマルチエージェント推論
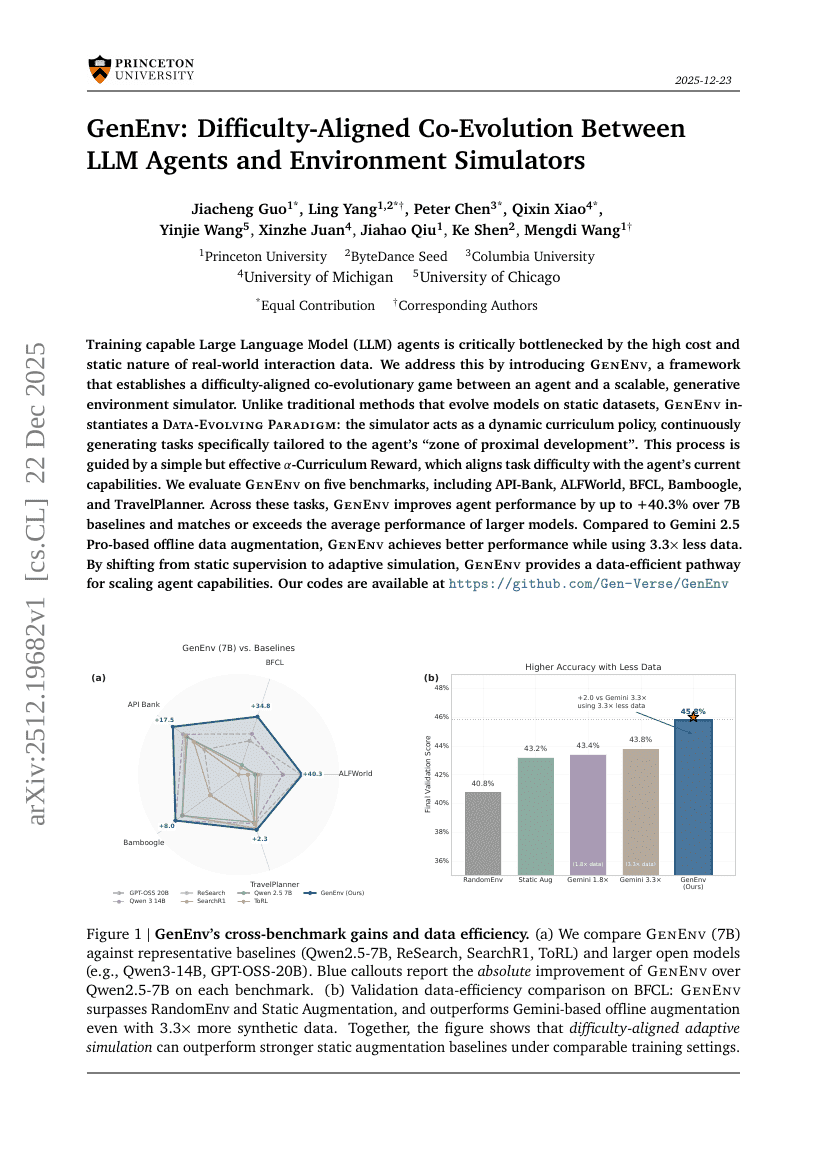







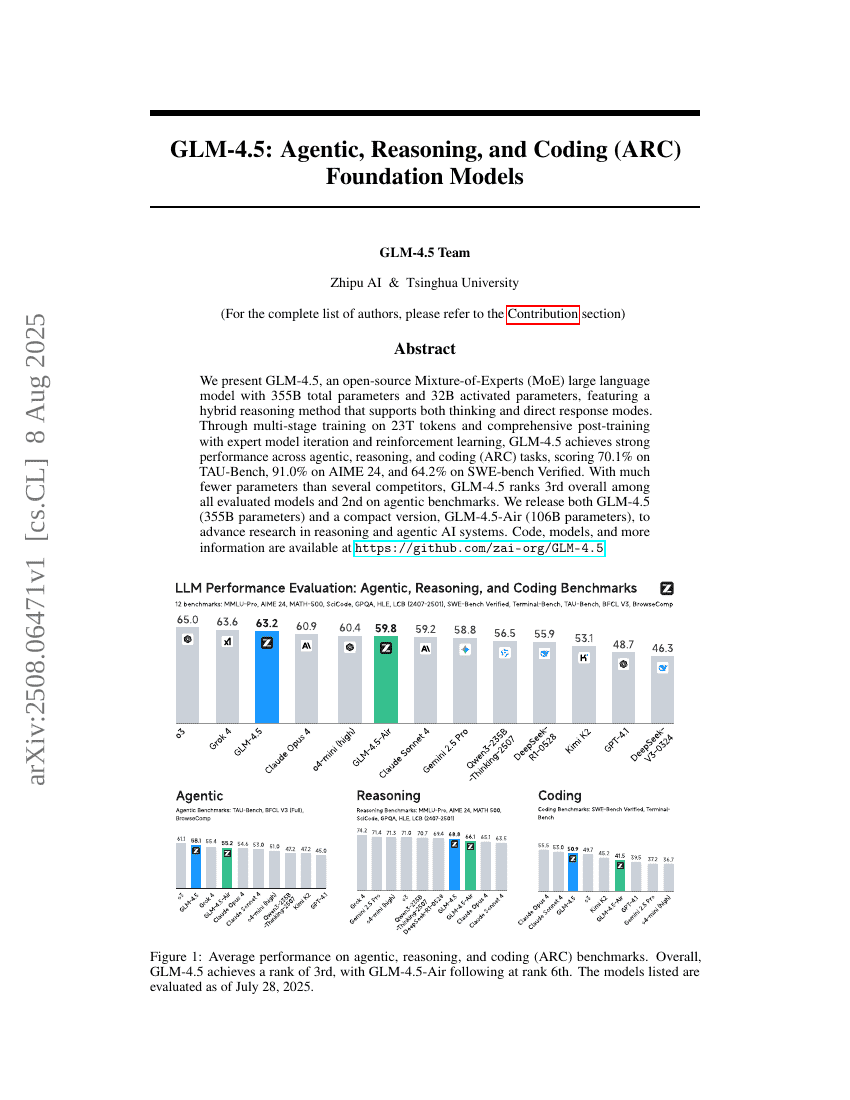



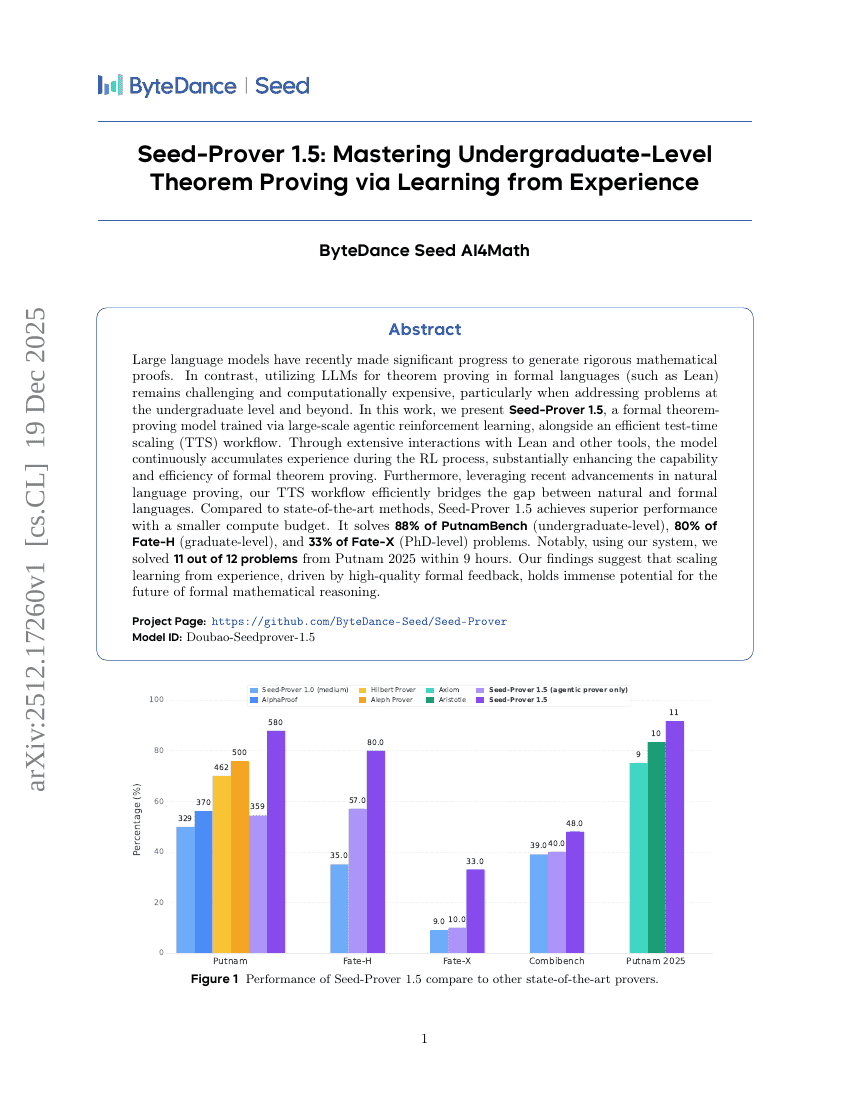


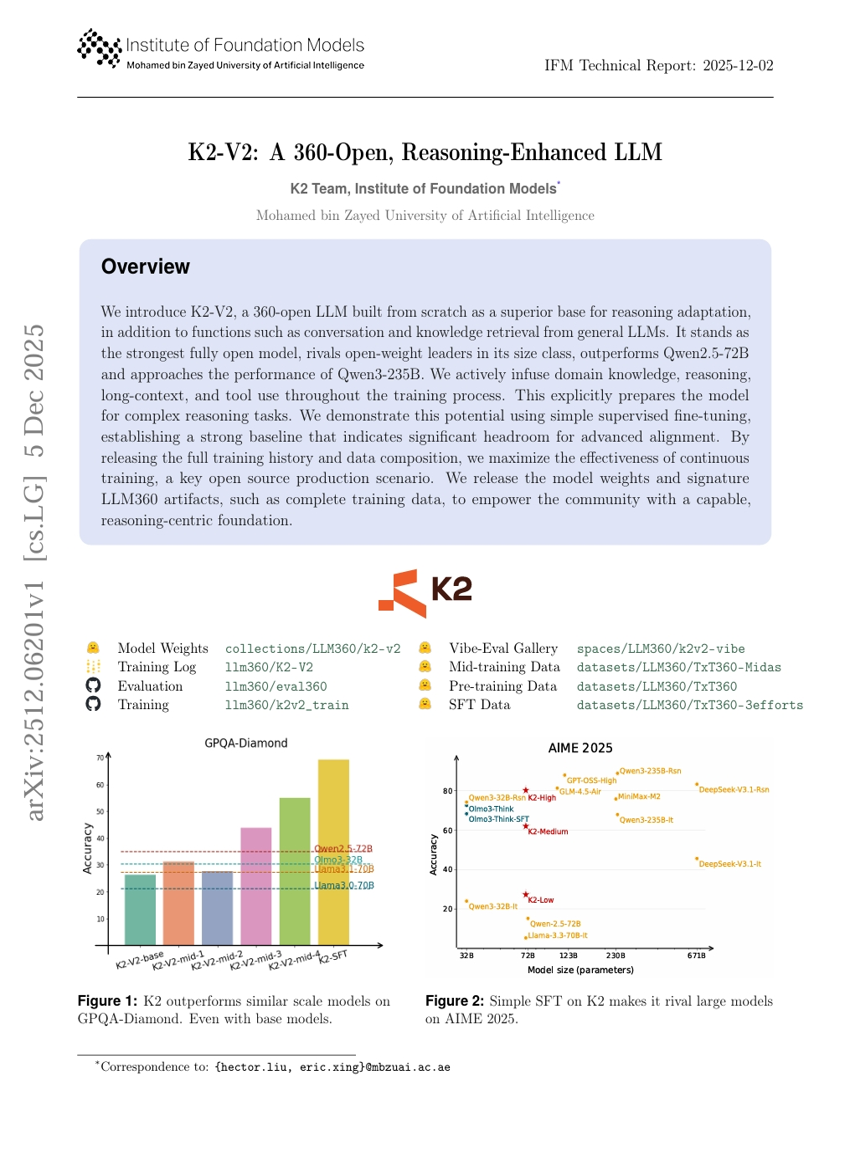











人間がループ内に参加する推論型大規模言語モデルエージェントを用いた自動ステレオタクティック放射線外科学計画
LongVideoAgent:長時間動画を用いたマルチエージェント推論
GenEnv:LLMエージェントと環境シミュレータ間の難易度整合型共進化
WorldWarp:非同期ビデオディフュージョンを用いた3Dジオメトリの伝播
LoGoPlanner:メトリック感知視覚幾何を備えた局所化基盤型ナビゲーション方策
LLMは学生の困難を推定できるか?プロフィシエンシー・シミュレーションを用いた人間-AI難易度整合による項目難易度予測
QuCo-RAG:事前学習コーパスからの不確実性の定量化による動的リトリーブ増強生成
プリズム仮説:統一オートエンコーディングを用いた意味表現とピクセル表現の調和
Med-Banana-50K:テキスト誘導型医療画像編集を目的としたマルチモダリティ大規模データセット
Kascade:長文脈LLM推論における実用的なスパースアテンション手法
GLM-4.5:エージェント機能、推論能力、コーディングを備えたARC基盤モデル
GroundingME:多次元評価によるMLLMにおける視覚的接地ギャップの暴露
意味と再構成の両方が重要である:テキストから画像生成および編集に適した表現エンコーダーの構築
4D-RGPT:知覚蒸留を活用した領域レベルにおける4D理解への道標
Seed-Prover 1.5:経験からの学習による学部レベル定理証明の習得
推論が法則に出会うとき
LLMの科学的汎用知能を科学者に整合したワークフローで探求する
K2-V2:360-オープン、推論強化型LLM
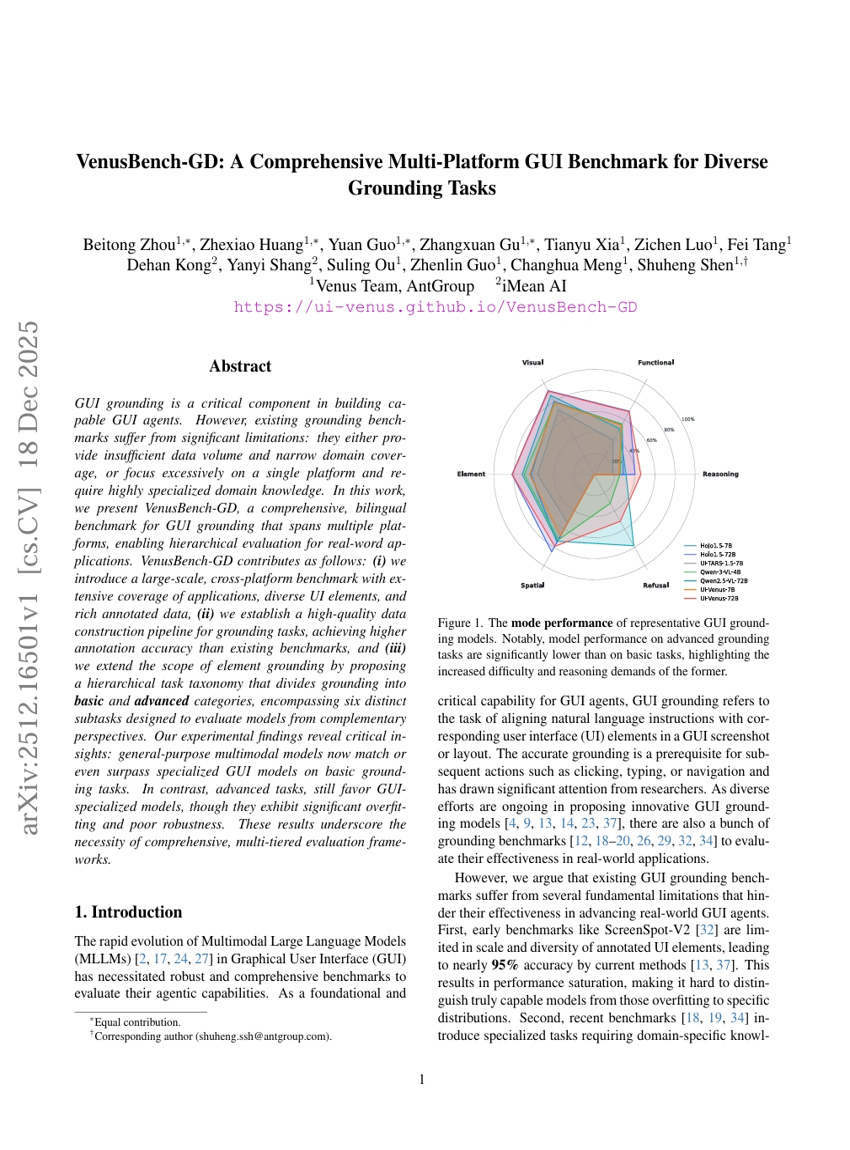
VenusBench-GD:多プラットフォームGUIを活用した多様なグランドリングタスク向け包括的ベンチマーク
MCIF:科学講演から得られたマルチモーダル・クロスリンガル指示追従ベンチマーク
NitroGen:汎用ゲームエージェント向けオープンフォンドレーションモデル
Hニューロン:大規模言語モデルにおける幻覚関連ニューロンの存在、影響および起源について
世界はあなたのキャンバスである:参照画像、軌道、テキストを用いたプロンプト可能なイベントの描写
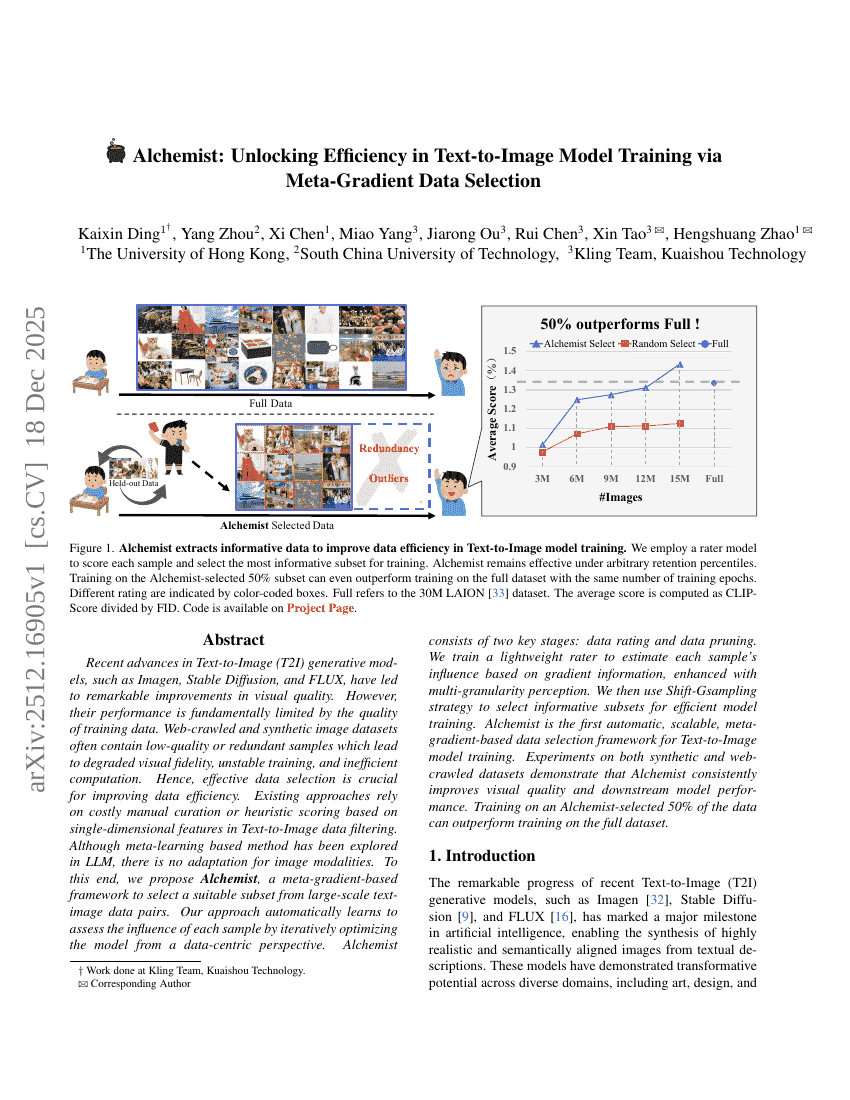
アルケミスト:メタ勾配データ選択によるテキストから画像へのモデル学習における効率性の解禁
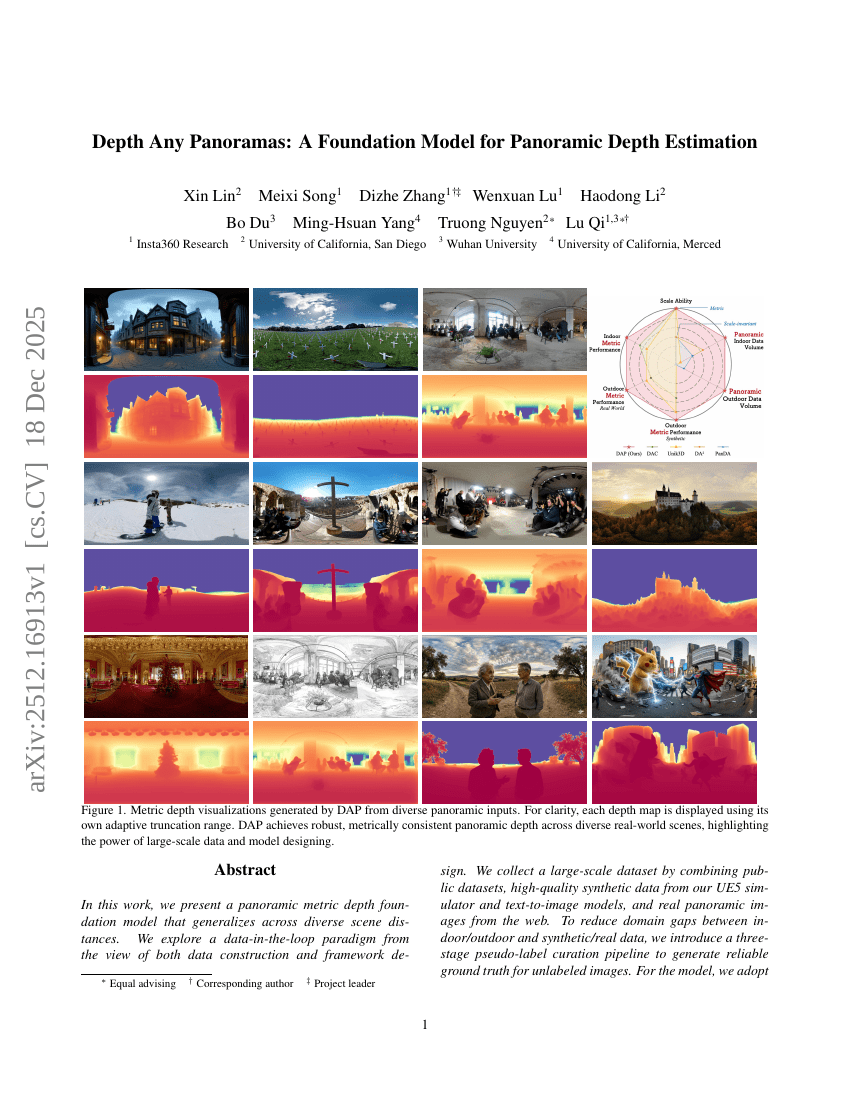
Depth Any Panoramas: パノラマ深度推定のためのファウンデーションモデル
生成的焦点再調整:単一画像からの柔軟なボケ量制御
StereoPilot:生成的事前知識を用いた統一的で効率的なステレオ変換の学習
次Embedding予測が強力な視覚学習者を実現する
エージェントAI:マルチモーダルインタラクションの地平を探索する
AI数学者を数学的発見の先導者として――均質化理論における事例研究
GenEval 2:テキストから画像評価におけるベンチマークのずれに対処する
PrivateXR:説明可能なAIガイド付き微分プライバシーを用いた拡張現実におけるプライバシー攻撃防御
GenEnv:LLMエージェントと環境シミュレータ間の難易度整合型共進化
WorldWarp:非同期ビデオディフュージョンを用いた3Dジオメトリの伝播
LoGoPlanner:メトリック感知視覚幾何を備えた局所化基盤型ナビゲーション方策
LLMは学生の困難を推定できるか?プロフィシエンシー・シミュレーションを用いた人間-AI難易度整合による項目難易度予測
QuCo-RAG:事前学習コーパスからの不確実性の定量化による動的リトリーブ増強生成
プリズム仮説:統一オートエンコーディングを用いた意味表現とピクセル表現の調和
Med-Banana-50K:テキスト誘導型医療画像編集を目的としたマルチモダリティ大規模データセット
Kascade:長文脈LLM推論における実用的なスパースアテンション手法
GLM-4.5:エージェント機能、推論能力、コーディングを備えたARC基盤モデル
GroundingME:多次元評価によるMLLMにおける視覚的接地ギャップの暴露
意味と再構成の両方が重要である:テキストから画像生成および編集に適した表現エンコーダーの構築
4D-RGPT:知覚蒸留を活用した領域レベルにおける4D理解への道標
Seed-Prover 1.5:経験からの学習による学部レベル定理証明の習得
推論が法則に出会うとき
LLMの科学的汎用知能を科学者に整合したワークフローで探求する
K2-V2:360-オープン、推論強化型LLM
VenusBench-GD:多プラットフォームGUIを活用した多様なグランドリングタスク向け包括的ベンチマーク
MCIF:科学講演から得られたマルチモーダル・クロスリンガル指示追従ベンチマーク
NitroGen:汎用ゲームエージェント向けオープンフォンドレーションモデル
Hニューロン:大規模言語モデルにおける幻覚関連ニューロンの存在、影響および起源について
世界はあなたのキャンバスである:参照画像、軌道、テキストを用いたプロンプト可能なイベントの描写
アルケミスト:メタ勾配データ選択によるテキストから画像へのモデル学習における効率性の解禁
Depth Any Panoramas: パノラマ深度推定のためのファウンデーションモデル
生成的焦点再調整:単一画像からの柔軟なボケ量制御
StereoPilot:生成的事前知識を用いた統一的で効率的なステレオ変換の学習
次Embedding予測が強力な視覚学習者を実現する
エージェントAI:マルチモーダルインタラクションの地平を探索する
AI数学者を数学的発見の先導者として――均質化理論における事例研究
GenEval 2:テキストから画像評価におけるベンチマークのずれに対処する
PrivateXR:説明可能なAIガイド付き微分プライバシーを用いた拡張現実におけるプライバシー攻撃防御