Command Palette
Search for a command to run...
TokSuite:トークナイザーの選択が言語モデルの行動に与える影響を測定する
TokSuite:トークナイザーの選択が言語モデルの行動に与える影響を測定する
Gül Sena Altıntaş Malikeh Ehghaghi Brian Lester Fengyuan Liu Wanru Zhao Marco Ciccone Colin Raffel
概要
トークナイザーは、言語モデル(LM)がテキストを表現・処理するための基盤を提供する。その重要性にもかかわらず、トークナイゼーションの影響を独立して測定する困難さから、そのLMの性能や挙動に対する役割は十分に理解されていない。この課題に対処するため、本研究では、トークナイゼーションが言語モデルに与える影響を研究するためのモデル群とベンチマークを提供する「TokSuite」を提案する。具体的には、同一のアーキテクチャ、データセット、学習予算、初期化条件を用いて、異なるトークナイザーを用いる14種類のモデルを学習した。さらに、実世界の摂動(実際のトークナイゼーションに影響を与える可能性のある変動)を想定した、新たなベンチマークを収集・公開した。これらの要素を統合することで、TokSuiteはモデルのトークナイザーの影響を堅牢に分離可能とし、幅広く用いられる各種トークナイザーの利点と課題を明らかにする一連の新たな知見を可能にした。
One-sentence Summary
Researchers from University of Toronto and Vector Institute, McGill University and Mila, et al. propose TokSuite, featuring 14 architecturally identical language models with diverse tokenizers trained under uniform conditions and a benchmark for real-world perturbations, enabling isolated analysis of tokenizer impact to systematically evaluate strengths and limitations of major tokenization approaches.
Key Contributions
- Tokenization's impact on language model performance remains poorly understood due to the difficulty of isolating its effects from other variables during model training and evaluation.
- The authors introduce TokSuite, comprising fourteen identical models trained with different tokenizers (same architecture, data, and initialization) alongside a new multilingual benchmark that evaluates performance under real-world text perturbations affecting tokenization.
- This framework enables controlled analysis across diverse tokenizers and input variations, providing evidence through systematic model evaluations that reveal specific strengths and weaknesses of popular tokenization methods.
Introduction
Tokenizers fundamentally determine how language models process text, yet their isolated impact on model behavior remains poorly understood despite significantly influencing performance, training efficiency, and multilingual capabilities—poor choices can increase training costs by up to 68% for non-English languages. Prior research suffers from critical limitations: studies often conflate tokenizer effects with other variables like architecture or data, lack controlled model comparisons, and offer insufficient robustness benchmarks for real-world input variations like typos or complex scripts. The authors address this by introducing TokSuite, which provides fourteen rigorously controlled models differing only in tokenizer type—trained identically across architecture, data, and initialization—and a new multilingual benchmark specifically designed to measure performance under realistic tokenization-sensitive perturbations, enabling the first robust isolation of tokenizer effects.
Dataset
The authors use TokSuite, a benchmark dataset designed to evaluate tokenizer robustness through real-world text perturbations. Key details:
-
Composition and sources:
TokSuite contains ~5,000 samples across five languages (English, Turkish, Italian, Farsi, Mandarin Chinese) and three domains: general knowledge (80% of data), elementary math (20 questions), and STEM (44 questions). Sources include manually curated canonical multiple-choice questions translated by native speakers, with perturbations reflecting real-world variations. -
Subset details:
- Multilingual parallel subset: 40 canonical English questions (e.g., "The capital of France is...") translated into all five languages. Each question has 10–20 perturbed variants, filtered to ensure >70% model accuracy on canonical versions. Perturbations cover orthographic errors (e.g., Turkish typed with English keyboards), diacritics (Farsi optional marks), morphological challenges (Turkish agglutination), noise (OCR errors), and Unicode formatting.
- Math subset: 20 basic arithmetic questions (e.g., "10% of 100 is...") translated multilingually, with numeric formatting variants (e.g., "1,028.415" vs. "1.028,415").
- STEM subset: 44 technical questions featuring LaTeX expressions (e.g., m2s2kg), ASCII structures (e.g., molecular diagrams), and domain-specific formatting.
-
Usage in the paper:
The dataset evaluates 14 identical language models differing only in tokenizer (e.g., Gemma-2, GPT-2, TokenMonster). Models are tested on canonical versus perturbed samples to measure accuracy degradation. Mixture ratios prioritize multilingual coverage (80% general knowledge, 20% math/STEM), with language-specific perturbation ratios adjusted for linguistic characteristics (e.g., higher diacritic variants for Farsi). -
Processing details:
- Canonical questions were filtered via a "model-in-the-loop" process to retain only those answered correctly by >70% of models.
- Perturbations were manually curated by native speakers (acknowledged per language/dialect expertise).
- Zero-width characters are preserved as new tokens, maintained in 3-byte form, or normalized per tokenizer rules.
- A vocabulary unification framework creates bijective mappings between tokenizer-specific tokens to enable consistent embedding initialization.
- No cropping is applied; full perturbed sequences are evaluated to test end-to-end robustness.
Method
The authors leverage a unified framework to evaluate the impact of tokenization on downstream language model performance by aligning multiple tokenizers under a shared vocabulary space. The core of this approach is the construction of a “super vocabulary” SV, derived as the union of all individual tokenizer vocabularies Vi across a set of tokenizers T. This unification is performed at the UTF-8 byte level to ensure consistent string representation across systems, accommodating tokenizer-specific conventions such as WordPiece’s “##” prefixes or Unigram’s “_-” whitespace markers. A mapping function SV:V(X)↦SV(X) is then established for each tokenizer, translating its original token IDs into positions within SV, ensuring that any shared token string maps to the same index regardless of the tokenizer used. This enables consistent embedding initialization across models for overlapping tokens.
Refer to the framework diagram, which illustrates how multiple tokenizers—including GPT-2, TokenMonster, XGLM, and others—are integrated under a common architecture. The diagram also highlights how tokenization behavior varies across languages (e.g., Turkish, Chinese, Italian), error types (OCR, orthographic), and symbolic domains (emojis, chemical formulas), all mapped through the TokSuite framework to a shared Llama-3.2 1B model trained with 14 distinct tokenizers.
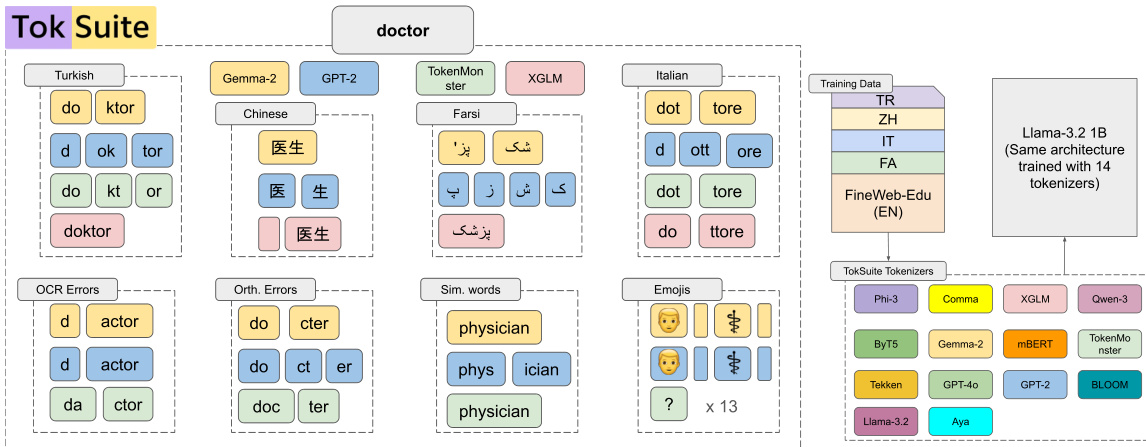
Model initialization follows the Llama-1B configuration but is adapted to the super vocabulary size ∣Esv∣=∣SV∣. Each model’s embedding table E is initialized by selecting rows from the shared super vocabulary embedding table Esv, such that E(x)=Esv(sv(X)). This ensures that all models begin training with identical initial embeddings for any token present in SV, thereby isolating the effect of tokenizer design from random initialization variance. The training data used includes multilingual corpora such as TR, ZH, IT, FA, and FineWeb-Edu (EN), which influence the composition and coverage of the resulting vocabularies. Tokenizer-specific preprocessing decisions—such as handling of contractions, numbers, or whitespace—are preserved during training but are normalized during alignment to maintain comparability across systems.
Experiment
- Evaluated 14 tokenizers across vocabulary sizes (259–256k tokens) and algorithms, validating that tokenization design critically impacts robustness more than vocabulary scale; TokenMonster (English-only, 32k tokens) achieved the lowest average performance drop (0.18) on multilingual perturbations, surpassing larger multilingual tokenizers like Aya and XGLM.
- Measured robustness via relative accuracy drop on TokSuite benchmark: noise perturbations caused significantly higher degradation for non-English (0.22) versus English (0.15); STEM and LaTeX content induced severe drops (up to 0.30 for XGLM), while Unicode styling had the highest average drop (0.53).
- Byte-level tokenizer ByT5 demonstrated exceptional noise resilience (0.18 average multilingual noise drop) and handled Turkish/Chinese robustly (0.04/0.06 orthographic error drops), but exhibited poor efficiency with the highest subword fertility scores across languages.
- Scaling analysis revealed minimal robustness gains from larger models (1B vs 7B parameters) or extended training, confirming tokenization design—not model size—dominates robustness characteristics across perturbation types.
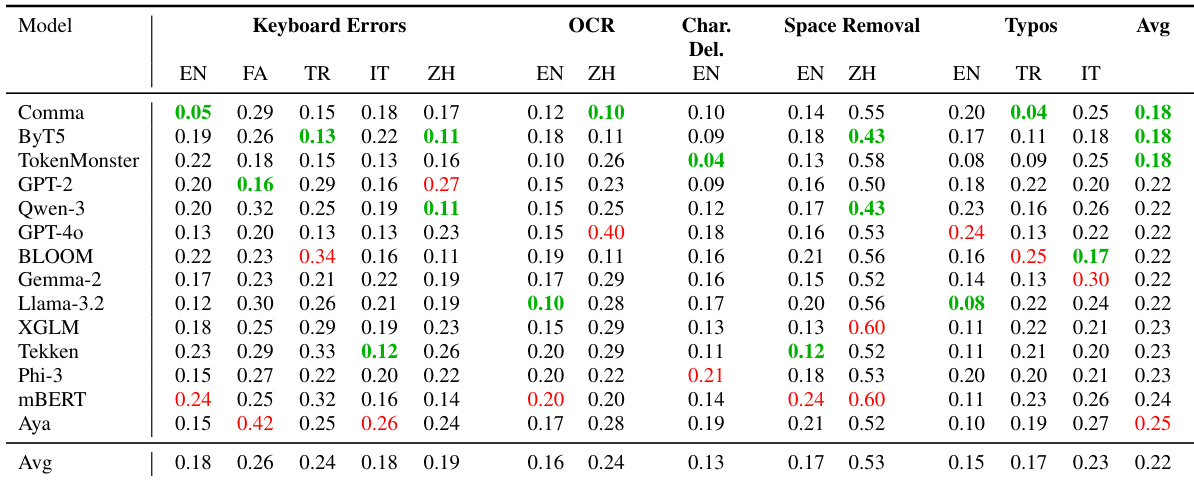
The authors evaluate 14 tokenizers on multilingual noise perturbations including keyboard errors, OCR, character deletion, space removal, and typos, reporting relative performance drops where lower values indicate greater robustness. TokenMonster and ByT5 achieve the lowest average drops (0.18), outperforming larger-vocabulary models, with ByT5 showing particular resilience in Chinese OCR and space removal. Results confirm that tokenization algorithm design, not vocabulary size, is the dominant factor in robustness under noise, especially for non-English languages.
The authors evaluate tokenization robustness using relative performance drop metrics across multiple perturbation categories, with lower values indicating greater resilience. TokenMonster and Gemma-2-EBL show strong overall robustness, particularly in noise and LaTeX handling, while Gemma-2 exhibits higher vulnerability in Unicode styling and STEM tasks. Results confirm that tokenization design, not just model scale or vocabulary size, critically determines robustness across diverse input perturbations.

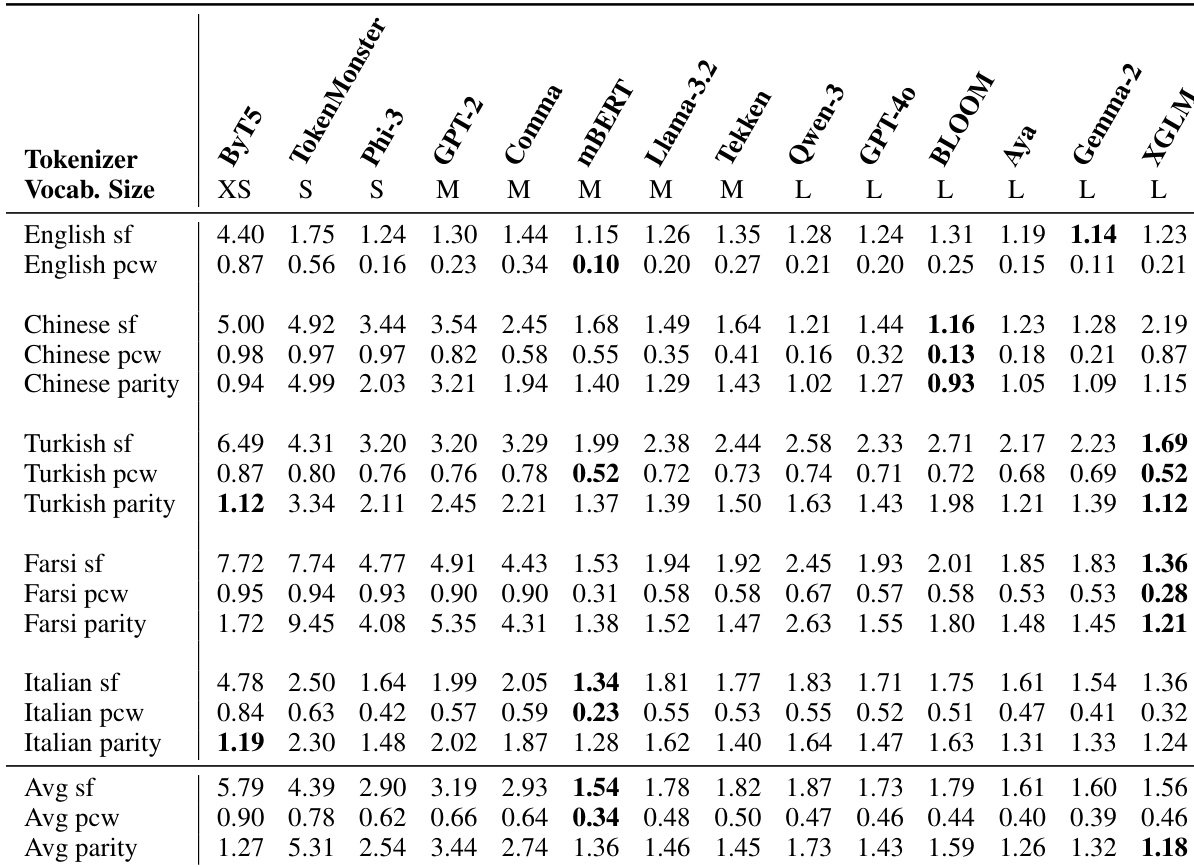
The authors evaluate 14 tokenizers across five languages using intrinsic efficiency metrics: subword fertility (SF), proportion of continued words (PCW), and cross-lingual parity. Results show that smaller-vocabulary tokenizers like ByT5 and TokenMonster exhibit higher SF and PCW, indicating more aggressive segmentation, while multilingual tokenizers such as mBERT and XGLM achieve better parity and lower average SF, suggesting more balanced cross-lingual compression. Vocabulary size alone does not guarantee efficiency, as some large-vocabulary tokenizers perform worse than smaller ones on key metrics.
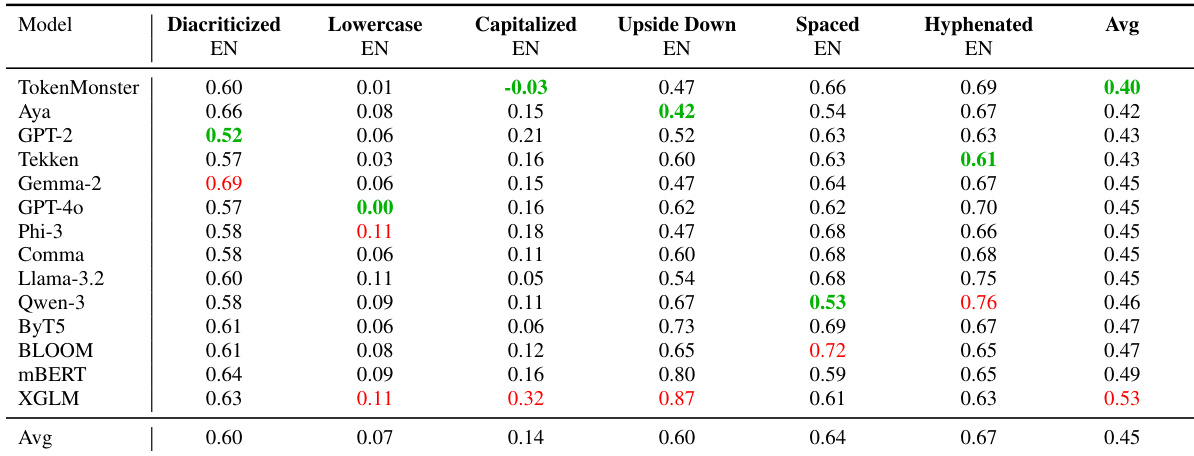
The authors evaluate 14 tokenizers on English text perturbations including diacritics, case variations, spacing, and formatting, measuring relative performance drop where lower values indicate greater robustness. TokenMonster achieves the best average robustness (0.40), while XGLM shows the highest average drop (0.53), with notable fragility under capitalized and upside-down text. Results confirm that tokenizer design, not just vocabulary size, critically influences robustness to surface-level text variations.
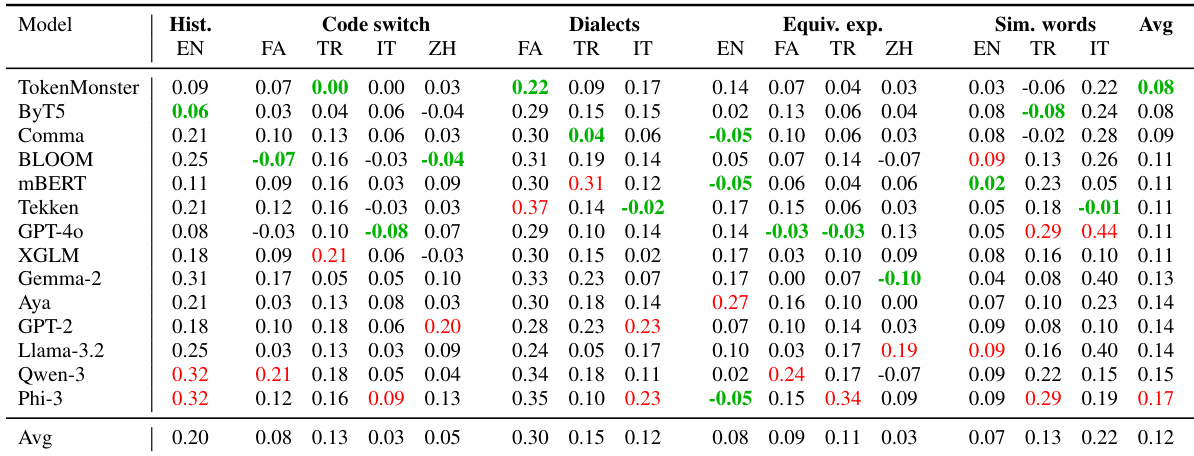
The authors evaluate 14 tokenizers on linguistic variety perturbations including historical spellings, code-switching, dialects, and equivalent expressions, finding that TokenMonster and ByT5 consistently show the strongest robustness across most categories. Results indicate that vocabulary size does not reliably predict performance, as smaller-vocabulary tokenizers like ByT5 outperform larger ones in several cases, highlighting the importance of tokenization algorithm design over scale. TokenMonster achieves the lowest average relative performance drop (0.08), demonstrating exceptional consistency despite its English-only training and modest vocabulary size.