Command Palette
Search for a command to run...
NHSにおけるプライマリケアにおけるLLM薬物療法安全レビューの実世界評価
NHSにおけるプライマリケアにおけるLLM薬物療法安全レビューの実世界評価
Oliver Normand Esther Borsi Mitch Fruin Lauren E Walker Jamie Heagerty Chris C. Holmes Anthony J Avery Iain E Buchan Harry Coppock
概要
大規模言語モデル(LLM)は、医療ベンチマークにおいて臨床医レベルの性能と同等あるいはそれを上回ることが多いが、実際の臨床データ上で評価されているモデルは極めて少なく、またヘッドライン上の指標以外の詳細な検証も行われていない。本研究では、われわれの知る限り、英国国民保健サービス(NHS)の一次医療データを用いた、LLMベースの薬物安全レビューシステムの初めての評価を報告する。また、臨床的複雑性の異なる状況下における主要な失敗行動の詳細な特徴づけも行っている。NHSチェシャー・アンド・マーレイサイド地域に所在する2,125,549人の成人を対象とした大規模電子健康記録(EHR)を用いた後向き研究において、臨床的複雑性と薬物安全リスクの多様な範囲をカバーするよう戦略的に患者をサンプリングした結果、データ品質上の除外を経て277人の患者が抽出された。これらの患者について、専門の臨床医がシステムが検出した問題および提案された介入策を評価・格付けした。主たるLLMシステムは、臨床的問題の存在を識別する能力において優れた性能を示した(感度:100% [95%信頼区間:98.2–100]、特異度:83.1% [95%信頼区間:72.7–90.1])が、問題と介入策の両方を正しく特定できたのは全体の46.9% [95%信頼区間:41.1–52.8]にとどまった。失敗分析の結果、この設定下で顕著な失敗要因は、薬物知識の欠如ではなく、文脈理解の不備であることが明らかになった。具体的には、以下の5つの主要なパターンが同定された:不確実性に対する過剰な自信、患者の個別状況を考慮せずに標準ガイドラインを機械的に適用する、実際の医療提供プロセスの理解不足、事実誤認、およびプロセスへの無関心(プロセス盲点)。これらのパターンは、患者の臨床的複雑性や人口統計的属性の違いに関わらず、また最先端の複数のモデルと設定においても一貫して観察された。本研究では、同定されたすべての失敗事例を網羅的にカバーする45の詳細な事例(ヴィニエット)を提供している。本研究は、LLMを用いた臨床AIを安全に導入する前に克服すべき課題を浮き彫りにしている。また、より大規模で前向きな評価、およびLLMが臨床現場でどのように振る舞うかについての深層的な検討の必要性を強く示唆している。
One-sentence Summary
Researchers from i.AI/DSIT, University of Liverpool, and et al. present the first real-world NHS evaluation of an LLM medication safety system, identifying contextual reasoning failures—particularly overconfidence and guideline rigidity—as the dominant limitation across 277 complex patient cases despite 100% sensitivity, revealing critical safety gaps requiring resolution before clinical deployment.
Key Contributions
- This study addresses the critical gap in evaluating large language models (LLMs) on real-world clinical data, as most prior research relies on synthetic benchmarks despite LLMs achieving clinician-level scores in controlled settings. It presents the first evaluation of an LLM-based medication safety review system using actual NHS primary care records, focusing on detailed failure analysis beyond headline metrics.
- The authors introduced a rigorous hierarchical evaluation framework applied to a population-scale EHR dataset of 2,125,549 adults, strategically sampling 277 high-complexity patients for expert clinician review to characterize failure modes across real-world clinical scenarios. Their analysis revealed that contextual reasoning failures—not missing medical knowledge—dominate errors, identifying five persistent patterns: overconfidence in uncertainty, rigid guideline application, misunderstanding healthcare delivery, factual errors, and process blindness.
- Evidence from the retrospective study shows the primary LLM system achieved high sensitivity (100%) but correctly identified all issues and interventions in only 46.9% of patients, with failure patterns consistent across patient complexity, demographics, and multiple state-of-the-art models. The work provides 45 detailed clinical vignettes documenting these failures, demonstrating that current LLMs cannot reliably handle nuanced clinical reasoning required for safe deployment.
Introduction
Medication safety reviews are critical in primary care due to the high global burden of preventable harm from prescribing errors, which cost the NHS up to £1.6 billion annually and contribute to 8% of hospital admissions. While large language models (LLMs) show promise in matching clinician-level performance on medical benchmarks, prior evaluations suffer from significant gaps: most studies rely on synthetic data or exam-style questions rather than real patient records, automated scoring often misses clinically significant errors like hallucinations, and failure modes remain poorly characterized in complex clinical workflows. The authors address this by conducting a real-world evaluation of LLMs on actual NHS primary care records, introducing a three-level hierarchical framework to dissect failures. They demonstrate that contextual reasoning flaws—such as misjudging temporal relevance or patient-specific factors—outnumber factual inaccuracies by a 6:1 ratio across 148 patients, revealing critical gaps between theoretical model competence and safe clinical deployment.
Dataset
The authors use electronic health records from NHS Cheshire and Merseyside's Trusted Research Environment (GraphNet Ltd.), covering 2,125,549 unique adults aged 18+ with structured SNOMED CT and dm+d coded data. Key details include:
- Primary dataset: Longitudinal patient profiles with GP events, medications, hospital episodes, and clinical observations (no free-text notes). Mean 1,010 GP events per patient; dates span 1976–2025. Population shows higher deprivation (26.6% in England’s most deprived decile vs. 7.7% least deprived).
- Evaluation subset: 300 patients sampled from a 200,000-patient test set, reduced to 277 after excluding 23 cases with data issues. Sampling included:
- 100 patients with prescribing safety indicators (stratified across 10 indicators)
- 100 indicator-negative patients matched on age, sex, prescriptions, and recent GP events
- 50 System-positive and 50 System-negative cases from indicator-negative populations
The authors processed raw parquet files into structured Pydantic patient profiles, converting them to chronologically ordered markdown for analysis. This included demographics, diagnoses, active/past medications, lab results, and clinical observations. For evaluation, clinician feedback on the 277 cases was synthesized into ground truth (validated clinical issues and interventions) using gpt-oss-120b. Data governance followed NHS Cheshire & Merseyside approvals, with pseudonymized profiles analyzed under strict TRE protocols (June–November 2025).
Method
The authors leverage a structured, three-stage pipeline to evaluate medication safety systems, integrating automated analysis with clinician validation. The process begins with longitudinal patient profiles extracted from electronic health records (EHRs), which include demographics, QOF registers, clinical events, and active medications. These profiles are formatted into a standardized patient prompt and fed into the system, which is instructed to flag safety issues and propose interventions. The system’s output comprises a summary, a list of clinical issues with supporting evidence, and a specific intervention plan if warranted.
Refer to the framework diagram, which illustrates the end-to-end workflow: from raw EHR-derived patient data through system analysis to clinician review. The system’s output is then manually evaluated by clinicians who assess both the presence and correctness of flagged issues and the appropriateness of proposed interventions. This manual review serves as the ground truth for subsequent automated scoring.

The evaluation employs a three-level hierarchical framework. Level 1 assesses whether the system correctly identifies any issue when one exists. Level 2, conditional on Level 1 success, evaluates whether the system correctly identifies all relevant issues. Level 3, conditional on Level 2, determines whether the proposed intervention directly resolves the identified safety concern. This tiered approach enables granular diagnosis of failure points, revealing where and why the system breaks down.
To scale evaluation across multiple models and configurations, the authors developed an automated scorer, Sautomated, which uses clinician-reviewed cases as ground truth. The scorer synthesizes clinician feedback into structured issue and intervention lists using an LLM, then employs a separate LLM judge to compute alignment scores based on F1 metrics for issue identification and intervention appropriateness. True negatives (agreement on absence of issues) receive a score of 1.0; disagreements on issue presence receive 0.0. This scorer enables quantitative comparison across models and analysis of performance variation, such as by patient ethnicity.
The system’s output must conform to a strict JSON schema, including fields for patient review, clinical issues (each with issue, evidence, and intervention_required), intervention plan, and intervention probability. Interventions must be specific, actionable, and directly resolve the safety concern—such as “Stop diltiazem”—rather than vague recommendations. The intervention_required flag is set to true only if the issue poses substantial, current, evidence-based risk that can be resolved with a concrete action.
Failure modes are systematically categorized using a five-category taxonomy derived from clinician review of 178 failure instances across 148 patients. Each failure is also classified by potential clinical harm using the WHO patient safety harm categories, ranging from none to death, to assess real-world impact if the system’s recommendation were implemented without review.
Experiment
- Evaluated gpt-oss-120b LLM system on real NHS primary care data with 277 patients, achieving 100% sensitivity [95% CI 98.2–100] and 83.1% specificity [95% CI 72.7–90.1] for binary intervention detection, but only 46.9% [95% CI 41.1–52.8] fully correct outputs identifying issues and interventions.
- Failure analysis revealed 86% of errors stemmed from contextual reasoning (e.g., overconfidence, protocol misapplication) versus 14% factual errors, with consistent patterns across patient complexity and demographic groups.
- Performance declined with clinical complexity (medication count r = -0.28, p < 0.001), and multi-model comparison showed gpt-oss-120b-medium outperformed smaller/fine-tuned models by 5.6–70.3% in clinician scoring.
- Anchoring bias analysis indicated a 7.9% gap between clinician agreement accuracy (95.7%) and model self-consistency ceiling (87.8%), while ethnicity counterfactual testing showed no significant performance differences across White, Asian, or Black patient profiles (p=0.976).
The authors use a clinician-reviewed evaluation to assess an LLM-based medication safety system on real NHS data, revealing that while the system achieves 100% sensitivity in flagging cases with issues, it correctly identifies all relevant issues in only 58.7% of those cases and proposes fully appropriate interventions in 58.7% of flagged cases. Results show that the system’s performance degrades across hierarchical evaluation levels, with only 46.9% of all patients receiving fully correct outputs, highlighting a gap between detecting problems and delivering contextually appropriate solutions.
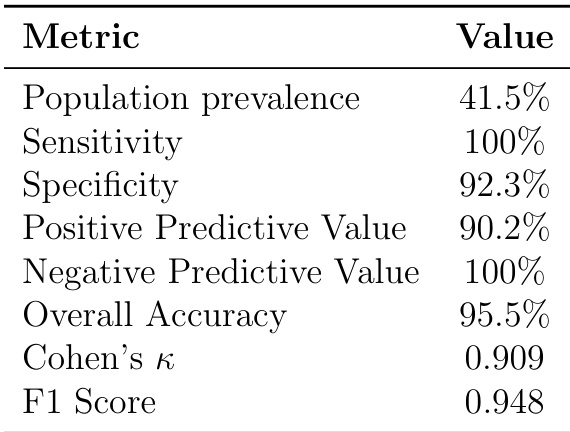
The authors use a stratified sampling approach to evaluate an LLM-based medication safety system on real NHS data, reporting population-level performance metrics derived from a subset of 95 unselected patients. Results show the system achieves 100% sensitivity and 92.3% specificity, with 95.5% overall accuracy and near-perfect negative predictive value, indicating strong detection of true negatives but potential for false positives in real-world deployment.
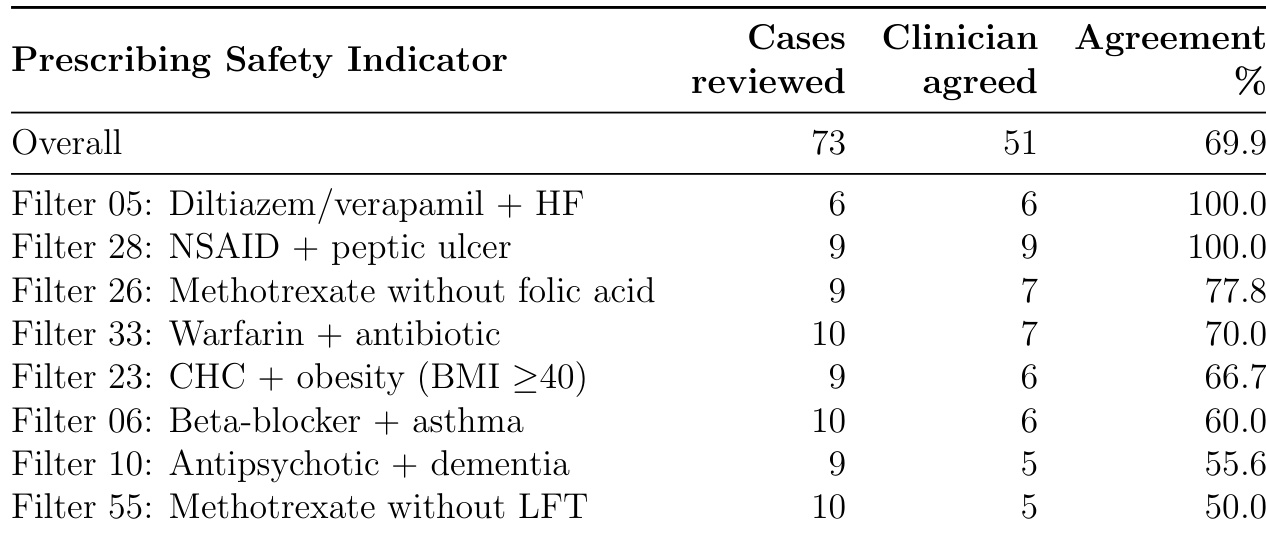
The authors evaluated clinician agreement with automated prescribing safety indicators across 73 cases, finding 69.9% overall agreement that flagged issues warranted intervention. Agreement varied significantly by indicator type, ranging from 100% for absolute contraindications like diltiazem/verapamil with heart failure to 50% for methotrexate without liver function test monitoring, highlighting that deterministic rules often require contextual clinical judgment.
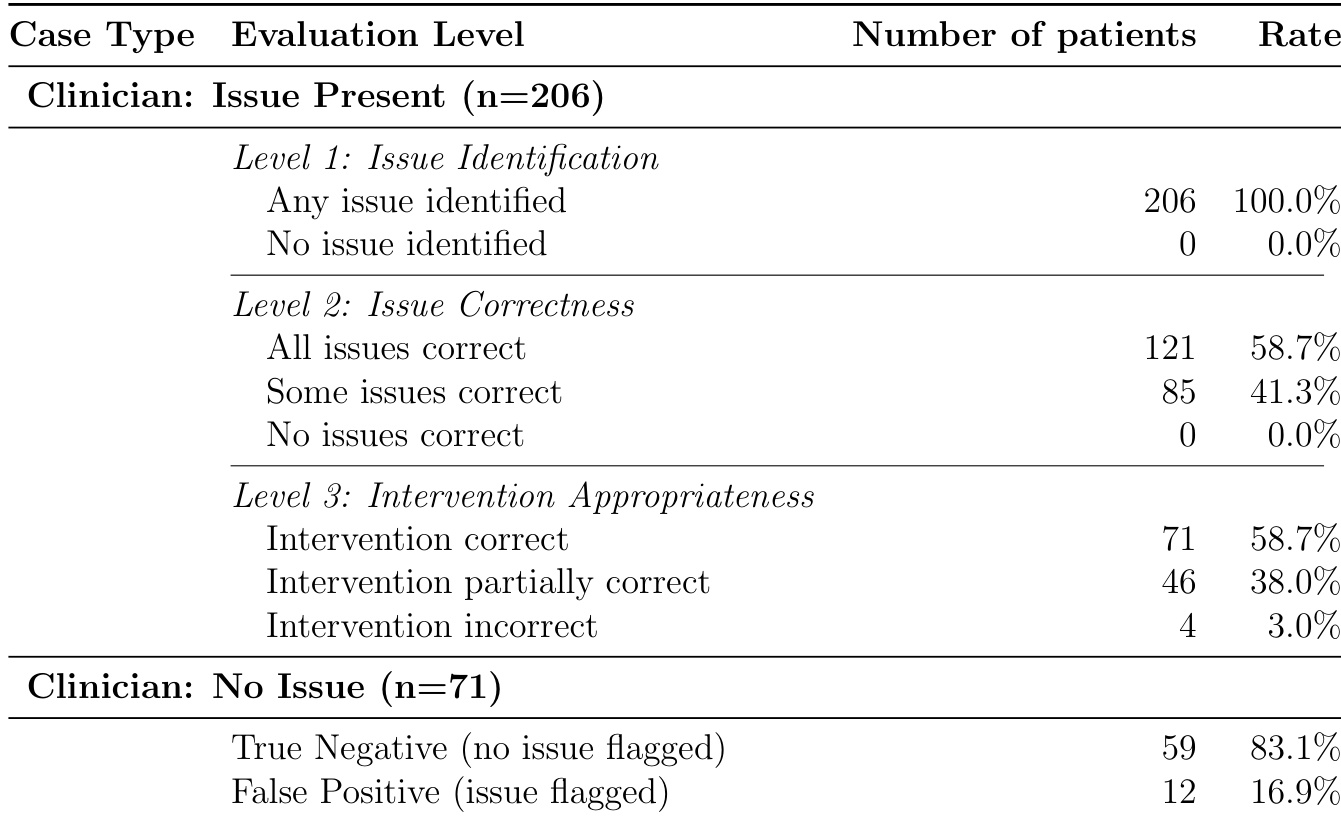
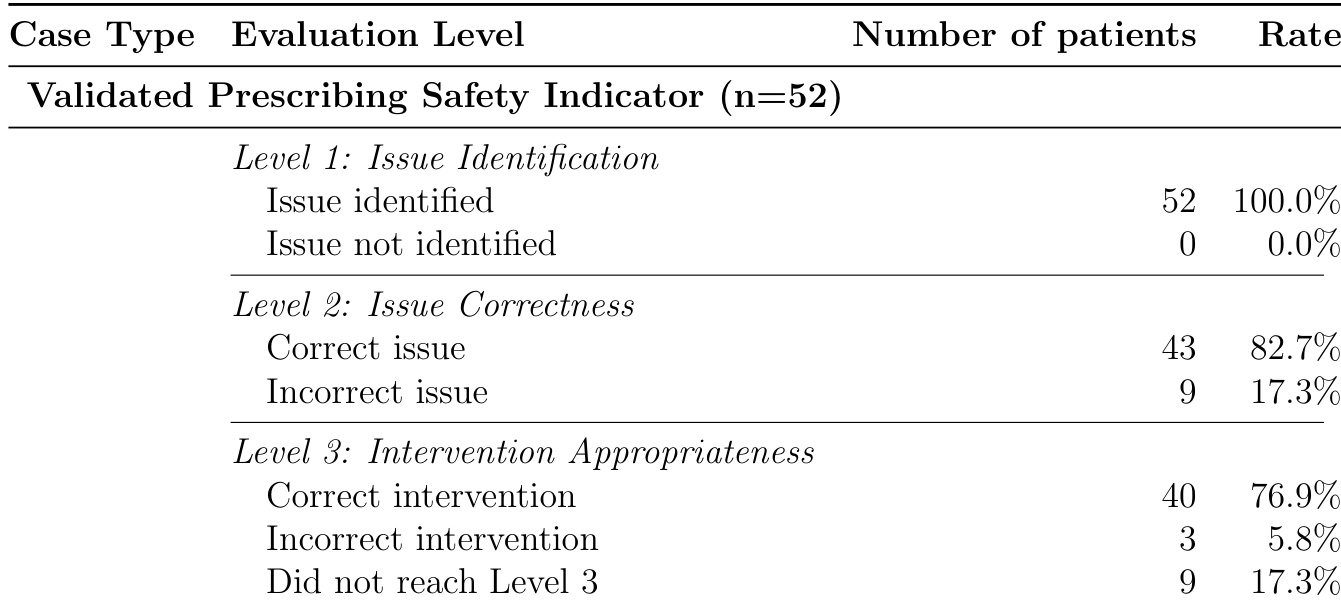
The authors evaluated an LLM system on 52 clinician-validated prescribing safety indicator cases and found it achieved 100% sensitivity at Level 1, correctly identifying all issues requiring intervention. At Level 2, the system accurately identified the specific indicator in 82.7% of cases, and at Level 3, it proposed appropriate interventions in 76.9% of cases where the issue was correctly identified. These results show strong detection capability but reveal a decline in precision and intervention quality as evaluation depth increases.
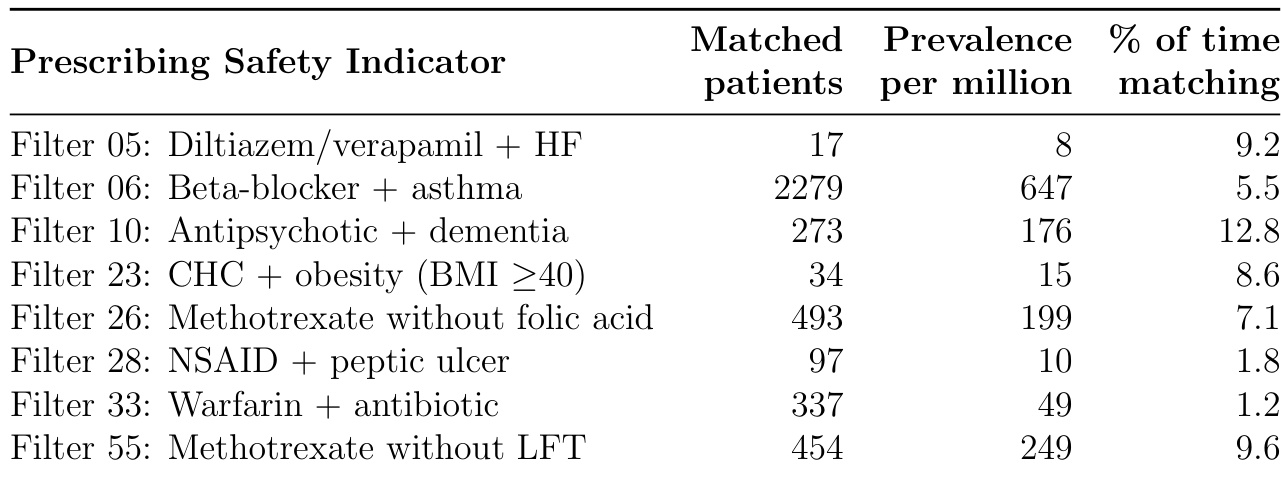
The table lists seven prescribing safety indicators with their matched patient counts, prevalence per million, and percentage of time patients met the criteria. Filter 06 (Beta-blocker + asthma) had the highest prevalence at 647 per million, while Filter 28 (NSAID + peptic ulcer) had the lowest at 10 per million. The percentage of time patients matched each filter varied, with Filter 10 (Antipsychotic + dementia) showing the highest continuity at 12.8%, indicating persistent risk, while Filter 33 (Warfarin + antibiotic) showed the lowest at 1.2%, reflecting transient interactions.