HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

幻覚の制御:反事実動画生成によるMLLMの動画理解能力の向上

SenseNova-MARS:強化学習を活用したマルチモーダルエージェント型推論と検索の実現



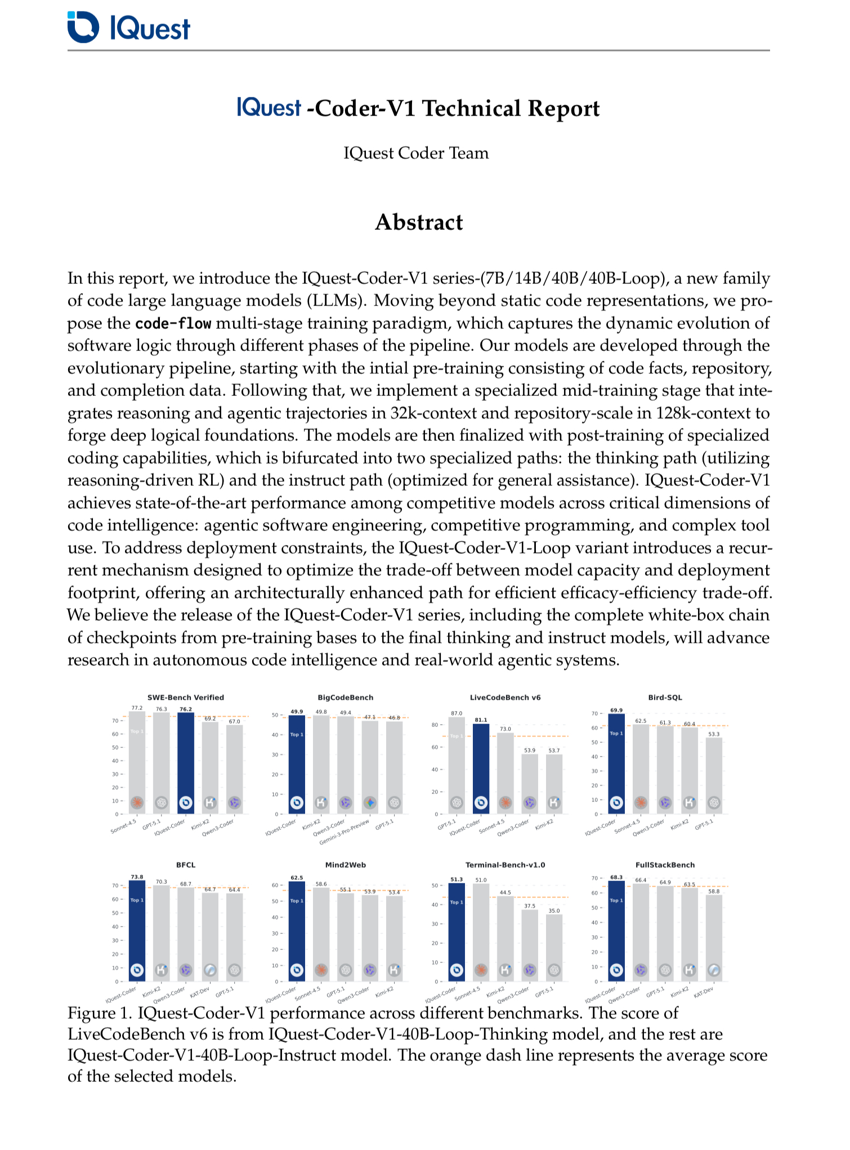
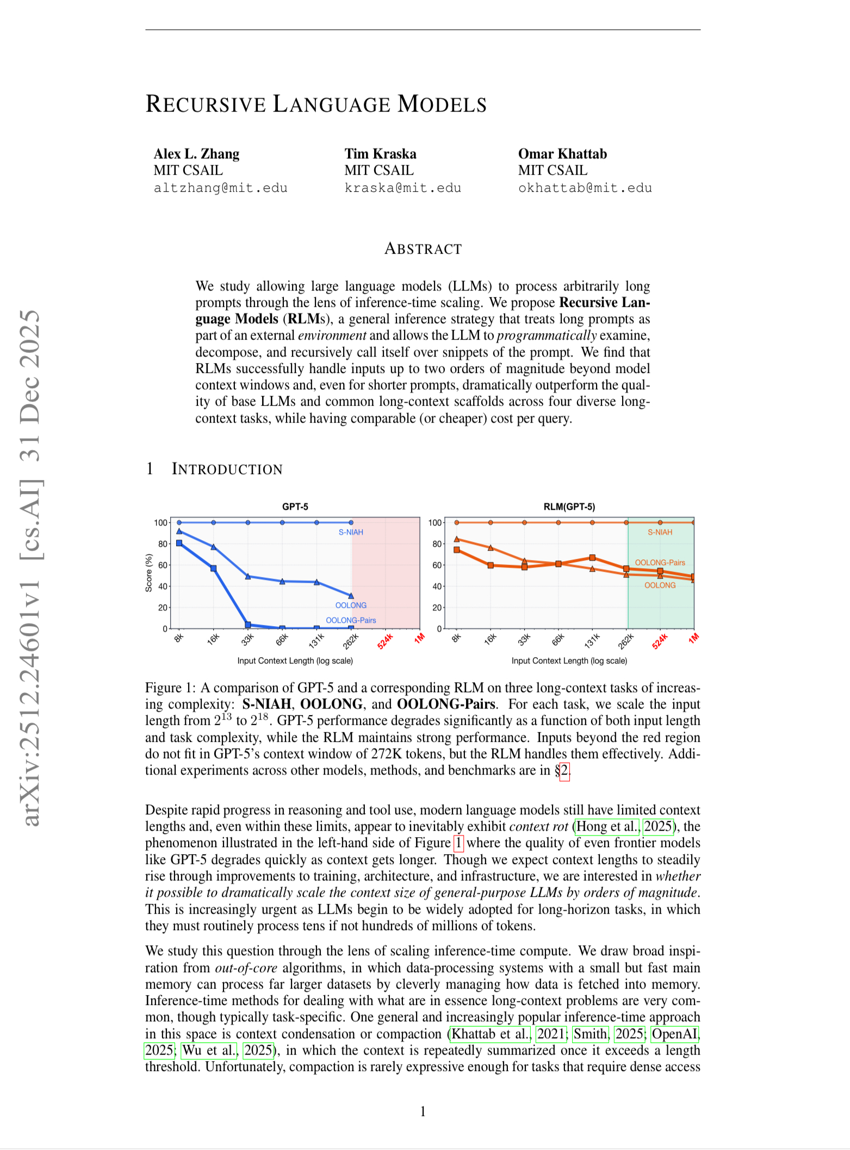



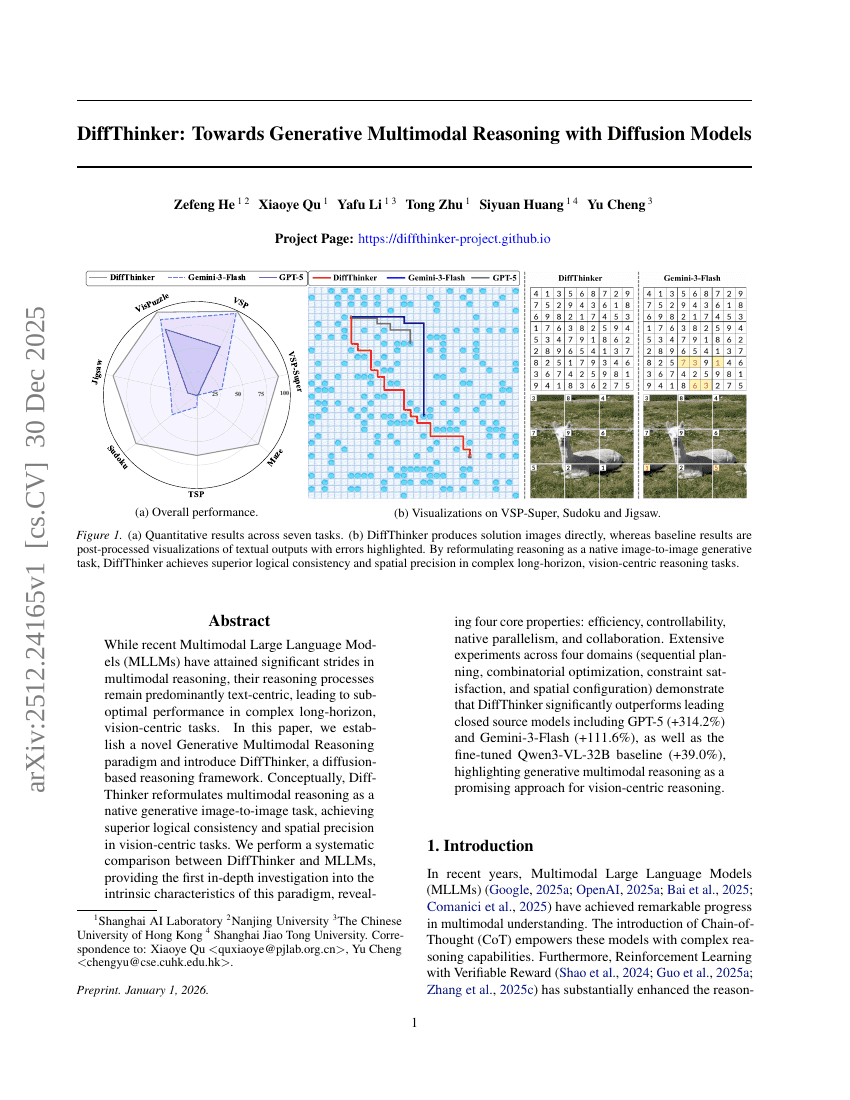






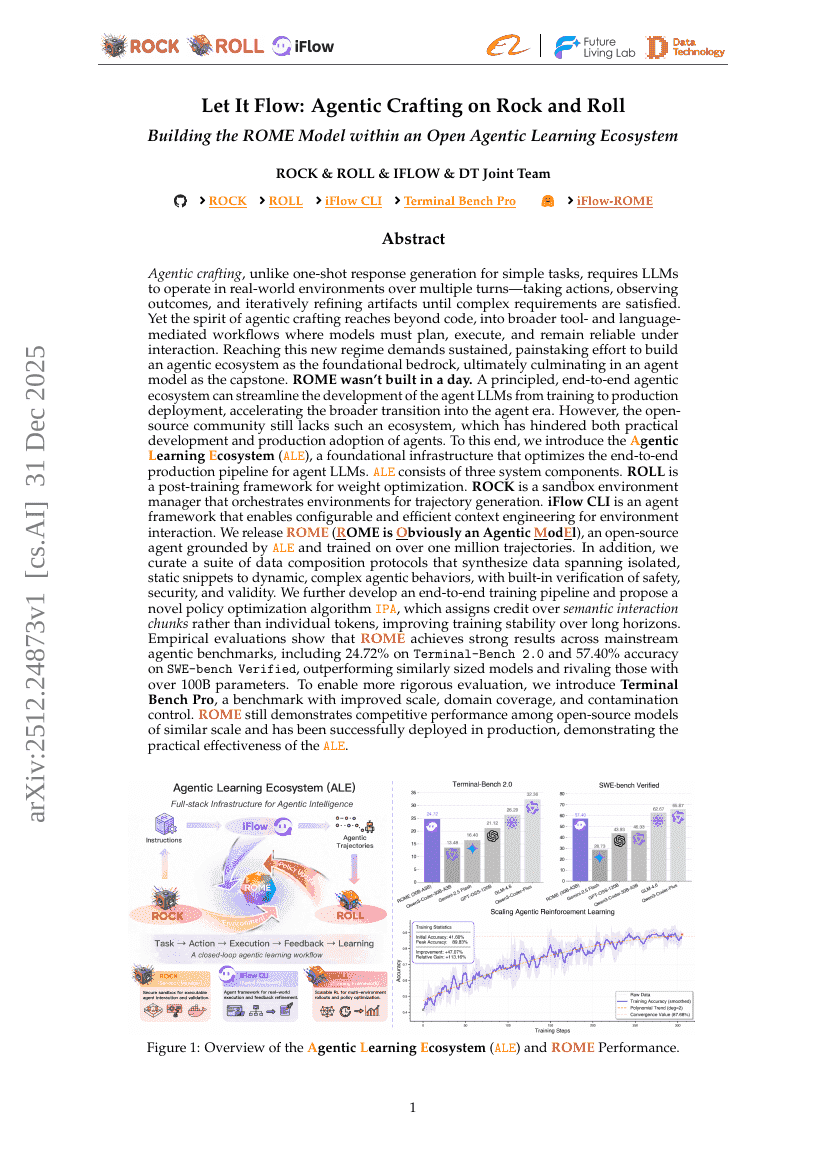











幻覚の制御:反事実動画生成によるMLLMの動画理解能力の向上
SenseNova-MARS:強化学習を活用したマルチモーダルエージェント型推論と検索の実現
アバター・フォースイング:自然な会話を実現するリアルタイム対話型ヘッドアバター生成
NeoVerse:リアルワールドの単眼動画を活用した4Dワールドモデルの強化
Youtu-Agent:自動生成とハイブリッドポリシー最適化によるエージェント生産性のスケーリング
IQuest-Coder-V1 技術報告
再帰型言語モデル
FlowBlending:段階認識型マルチモデルサンプリングによる高速かつ高忠実度の動画生成
Dream2Flow:3Dオブジェクトフローを用いたビデオ生成とオープンワールド操作の橋渡し
拡散LLMにおける離散性の役割
DiffThinker:拡散モデルを用いた生成型マルチモーダル推論へ向けて
動的大型概念モデル:適応型意味空間における潜在的推論
長文脈複雑関係モデリングにおけるハイパーグラフベースメモリを用いたマルチステップRAGの改善
AIが脳に出会う:認知神経科学から自律エージェントへ至る記憶システム
スケーラビリティの向上による開かれたエンドリーディング推論による未来予測
GaMO:スパースビュー3D再構成のための幾何学的注意型マルチビュー拡散外挿
mHC:多様体制約付きハイパーパス
Let It Flow: ロックンロールにおけるエージェンティック・クラフティング、オープンエージェンティック・ラーニングエコシステム内でのROMEモデル構築
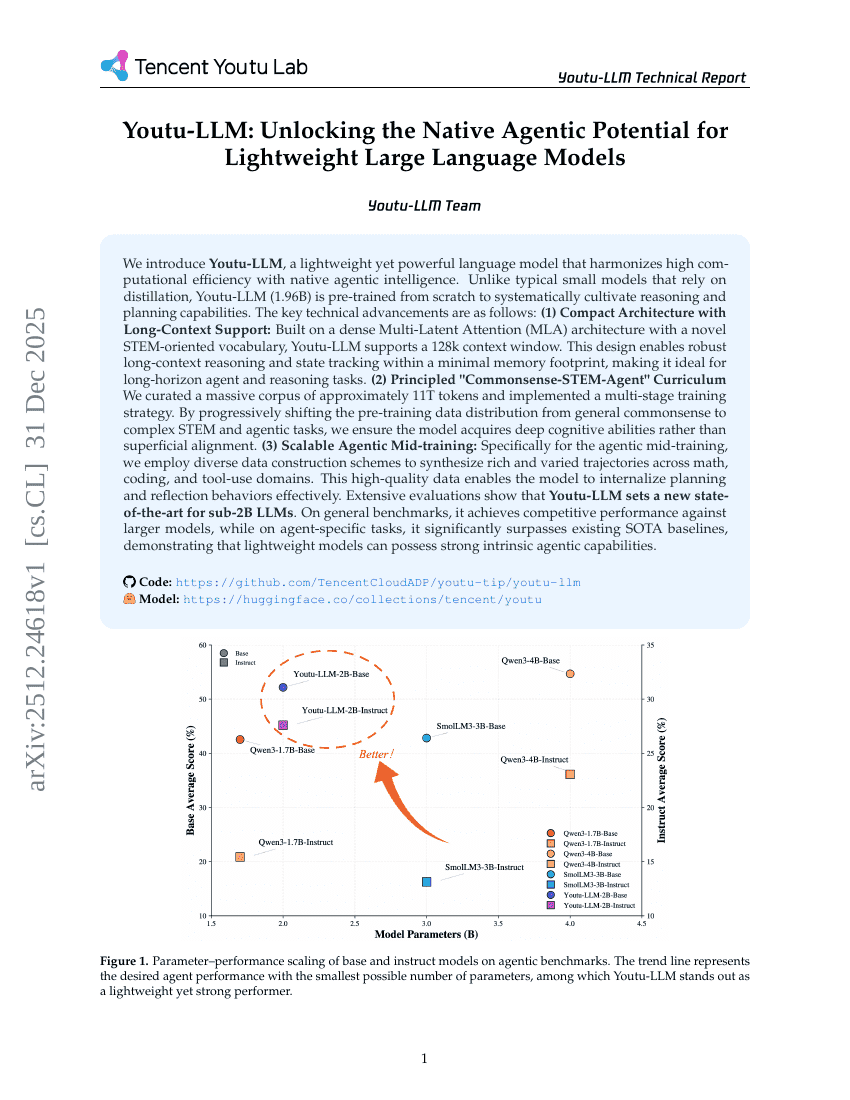
Youtu-LLM:軽量型大規模言語モデルにおけるネイティブなエージェント機能の潜在能力を解き放つ
GateBreaker:Mixture-of-Expert LLMsにおけるGate誘導型攻撃
GraphLocator:グラフ誘導型因果推論を用いた問題局所化
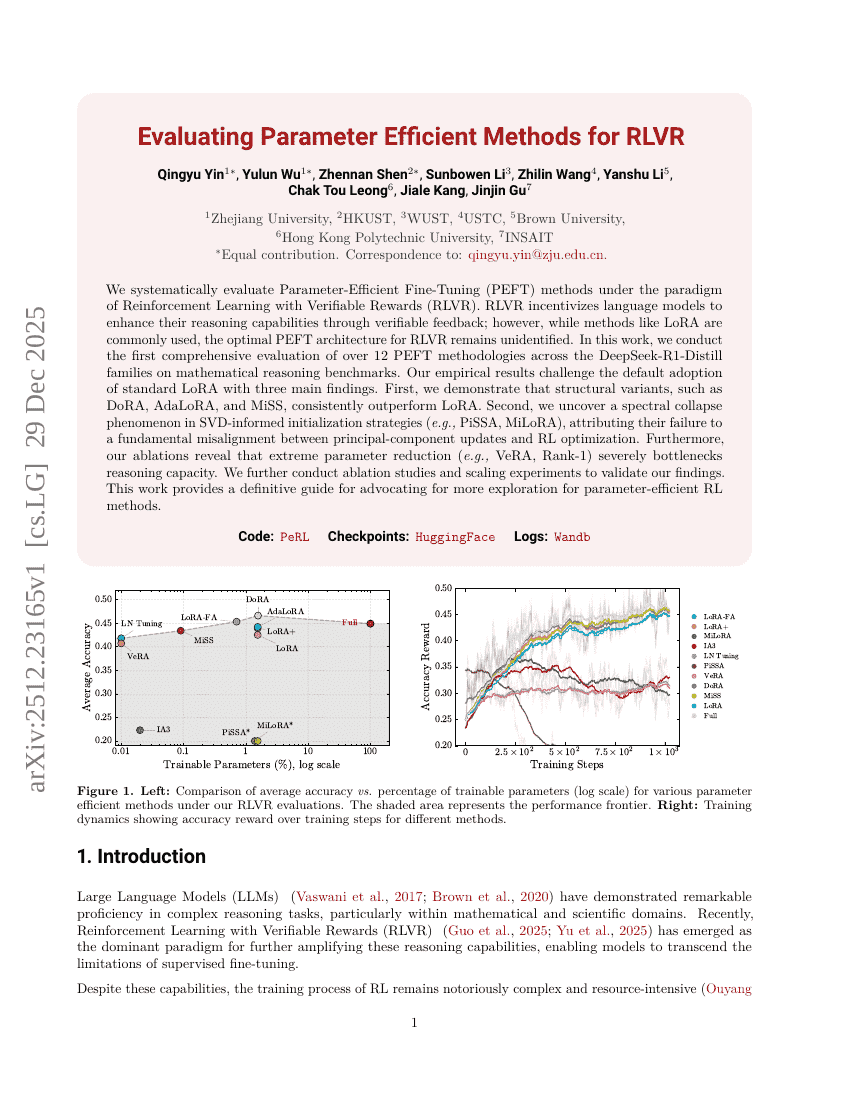
RLVRにおけるパラメータ効率的な手法の評価
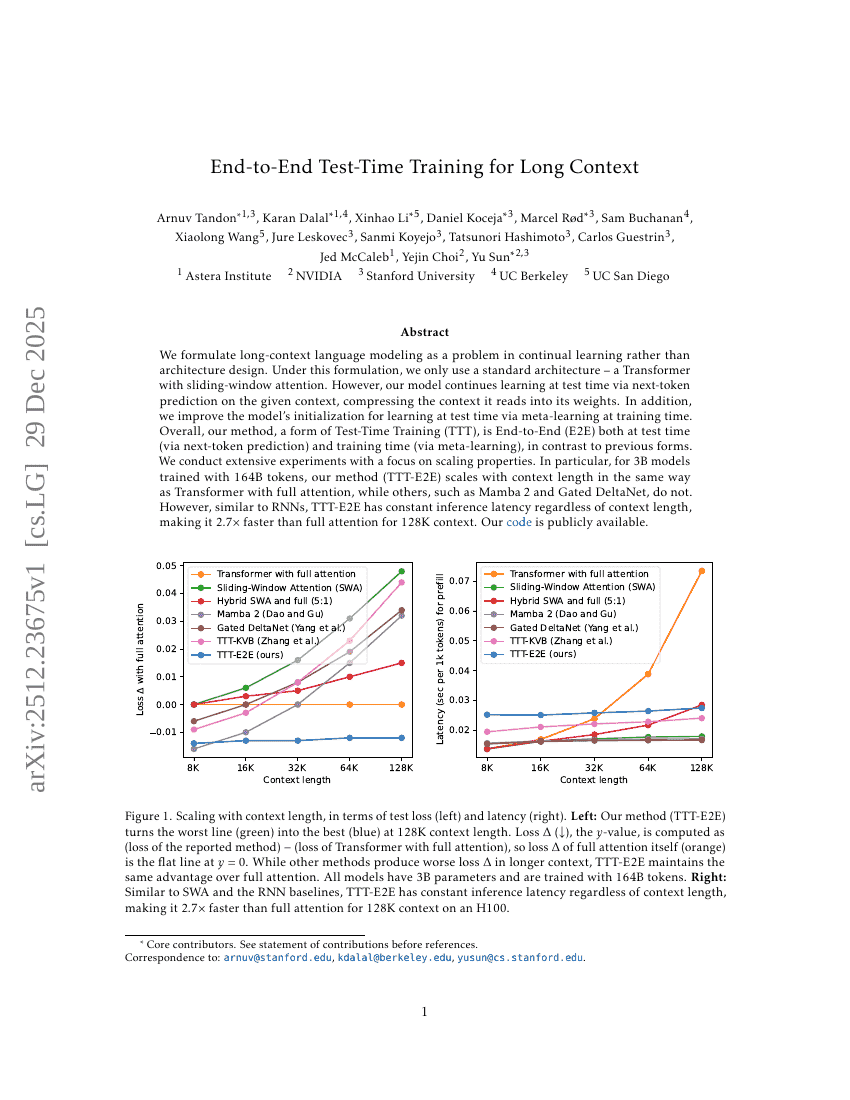
エンドツーエンドテスト時学習による長文脈処理
DreamOmni3:スクリブルベースの編集と生成
UltraShape 1.0:スケーラブルな幾何学的精緻化を用いた高忠実度3D形状生成
mimic-video:汎用的なロボット制御のためのビデオ・アクションモデル—VLAsを超えた枠組み
HY-Motion 1.0:テキストからモーション生成へのフローマッチングモデルのスケーリング
SurgWorld:ワールドモデリングを用いた動画からの外科ロボット方策学習
SpotEdit:拡散変換器における選択的領域編集
拡散モデルは透過性を理解する:動画拡散モデルを用いた透過物体の深度および法線推定
SmartSnap:自己検証型エージェントにおける能動的証拠探索
Yume-1.5:テキスト制御型インタラクティブな世界生成モデル
アバター・フォースイング:自然な会話を実現するリアルタイム対話型ヘッドアバター生成
NeoVerse:リアルワールドの単眼動画を活用した4Dワールドモデルの強化
Youtu-Agent:自動生成とハイブリッドポリシー最適化によるエージェント生産性のスケーリング
IQuest-Coder-V1 技術報告
再帰型言語モデル
FlowBlending:段階認識型マルチモデルサンプリングによる高速かつ高忠実度の動画生成
Dream2Flow:3Dオブジェクトフローを用いたビデオ生成とオープンワールド操作の橋渡し
拡散LLMにおける離散性の役割
DiffThinker:拡散モデルを用いた生成型マルチモーダル推論へ向けて
動的大型概念モデル:適応型意味空間における潜在的推論
長文脈複雑関係モデリングにおけるハイパーグラフベースメモリを用いたマルチステップRAGの改善
AIが脳に出会う:認知神経科学から自律エージェントへ至る記憶システム
スケーラビリティの向上による開かれたエンドリーディング推論による未来予測
GaMO:スパースビュー3D再構成のための幾何学的注意型マルチビュー拡散外挿
mHC:多様体制約付きハイパーパス
Let It Flow: ロックンロールにおけるエージェンティック・クラフティング、オープンエージェンティック・ラーニングエコシステム内でのROMEモデル構築
Youtu-LLM:軽量型大規模言語モデルにおけるネイティブなエージェント機能の潜在能力を解き放つ
GateBreaker:Mixture-of-Expert LLMsにおけるGate誘導型攻撃
GraphLocator:グラフ誘導型因果推論を用いた問題局所化
RLVRにおけるパラメータ効率的な手法の評価
エンドツーエンドテスト時学習による長文脈処理
DreamOmni3:スクリブルベースの編集と生成
UltraShape 1.0:スケーラブルな幾何学的精緻化を用いた高忠実度3D形状生成
mimic-video:汎用的なロボット制御のためのビデオ・アクションモデル—VLAsを超えた枠組み
HY-Motion 1.0:テキストからモーション生成へのフローマッチングモデルのスケーリング
SurgWorld:ワールドモデリングを用いた動画からの外科ロボット方策学習
SpotEdit:拡散変換器における選択的領域編集
拡散モデルは透過性を理解する:動画拡散モデルを用いた透過物体の深度および法線推定
SmartSnap:自己検証型エージェントにおける能動的証拠探索
Yume-1.5:テキスト制御型インタラクティブな世界生成モデル