HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

時間的な摩擦と裁判所の結果:2020–2024年におけるクック郡の刑事判決における時間遅延の影響分析

メタRLは言語エージェントにおける探索を誘発する


























時間的な摩擦と裁判所の結果:2020–2024年におけるクック郡の刑事判決における時間遅延の影響分析
メタRLは言語エージェントにおける探索を誘発する
LLMCache:Transformer推論における高速再利用のための階層的キャッシュ戦略
OPENTOUCH:現実世界のインタラクションにフルハンドタッチをもたらす
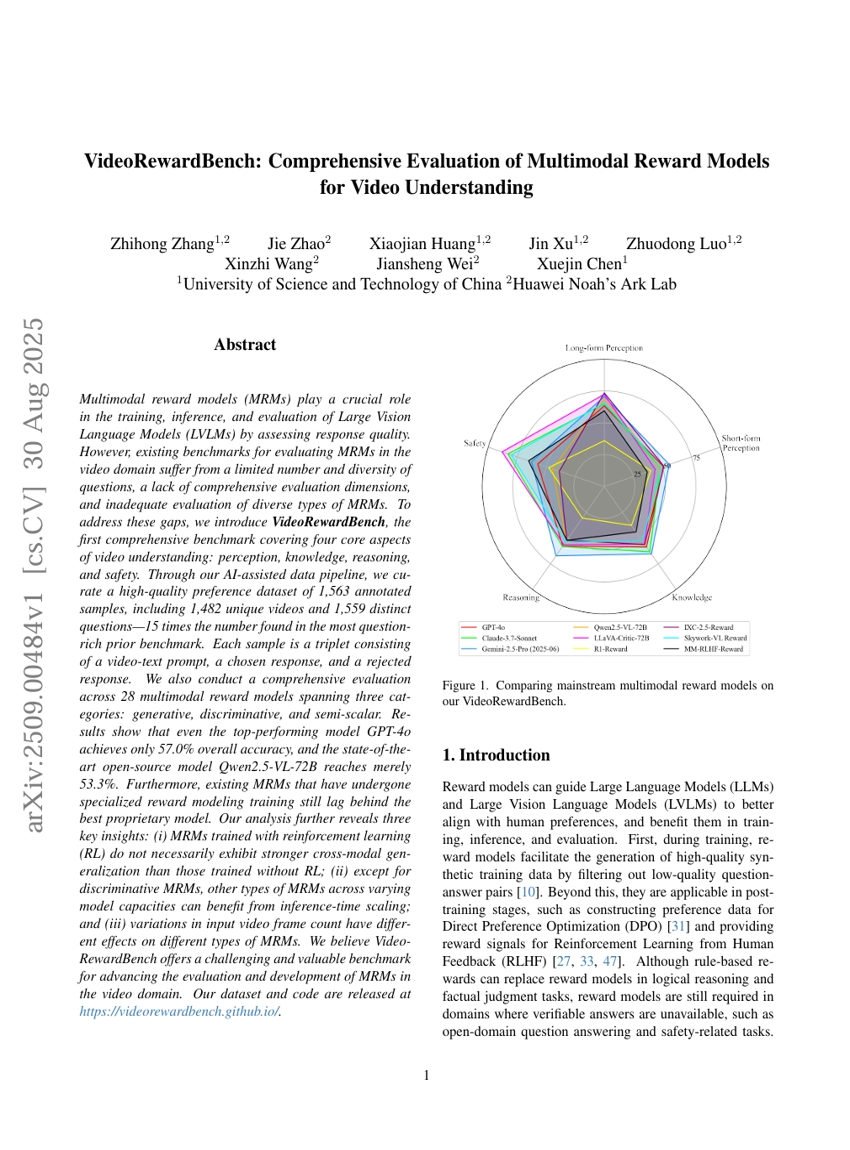
VideoRewardBench:動画理解におけるマルチモーダル報酬モデルの包括的評価
ソウル:高精度な長期マルチモーダルアニメーションのためのデジタル人間への生命の息吹き
IF-Bench:生成視覚を用いた赤外線画像におけるMLLMのベンチマーク評価と性能向上
RecGPT-V2 技ical Report
ベクトルプリズム:意味構造の階層化によるベクトルグラフィックスのアニメーション化
OpenDataArena:ポストトレーニングデータセット価値のベンチマーク評価のための公正でオープンなアリーナ
ビデオリアリティテスト:AI生成ASMR動画はVLMおよび人間を欺くことができるか?
WorldPlay:リアルタイムインタラクティブなワールドモデリングにおける長期的幾何学的一貫性の実現へ
MMGR:マルチモーダル・ジェネレーティブ・リーズニング
フロンティアサイエンス:AIが専門家レベルの科学的タスクを実行する能力の評価
FACTS Leaderboard:大規模言語モデルの事実性を評価する包括的なベンチマーク
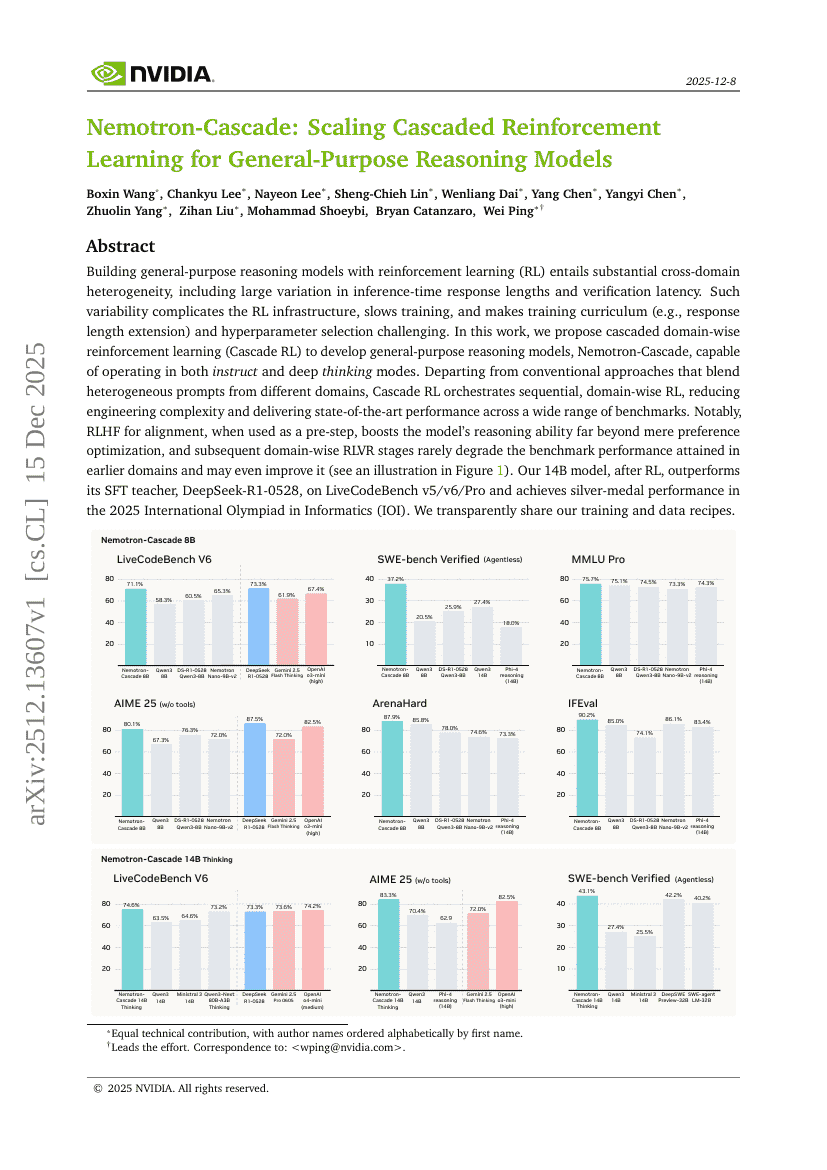
Nemotron-Cascade:汎用推論モデル向けカスケード強化学習のスケーリング
KlingAvatar 2.0 技術報告
QwenLong-L1.5:長文脈推論およびメモリ管理のためのポストトレーニングレシピ
ReFusion:並列自己回帰デコーディングを備えた拡散大規模言語モデル
エラーフリーな線形アテンションはフリーランチである:連続時間ダイナミクスからの正確な解
AIエージェントの時代における記憶
LongVie 2:マルチモーダル制御可能 Ultra-Long Video World Model
FirstAidQA:低接続環境における救急対応向けの合成データセット
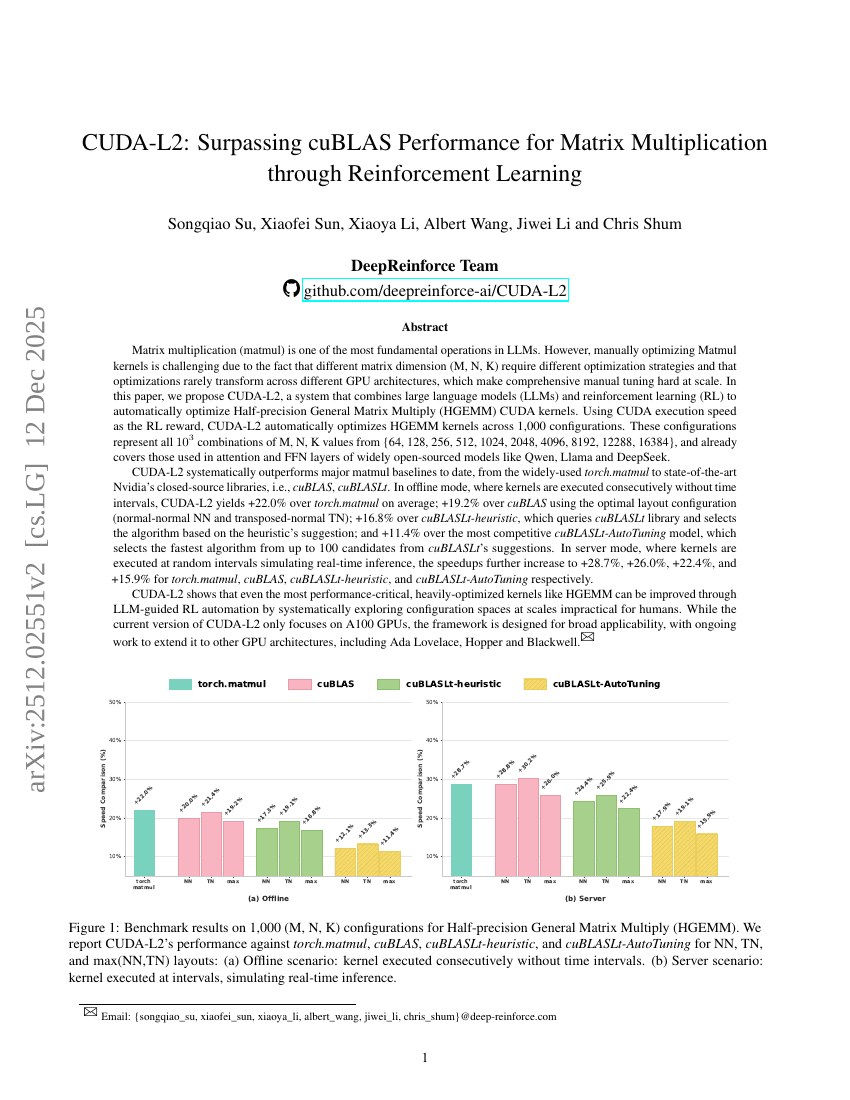
CUDA-L2:強化学習を活用した行列積演算におけるcuBLASを凌駕する性能
X-VLA:スケーラブルなクロスエン bodiment 視覚言語行動モデルとしてのソフトプロンプト付きトランスフォーマー
Nemotron 3 Nano:エージェンティックな推論向けに最適化されたオープンで効率的なMixture-of-Experts型ハイブリッドMamba-Transformerモデル
トラッキングからの構造:動画生成のための構造保存型運動の蒸留
MetaCanvasを用いたMLLM-Diffusion間情報伝達の探求
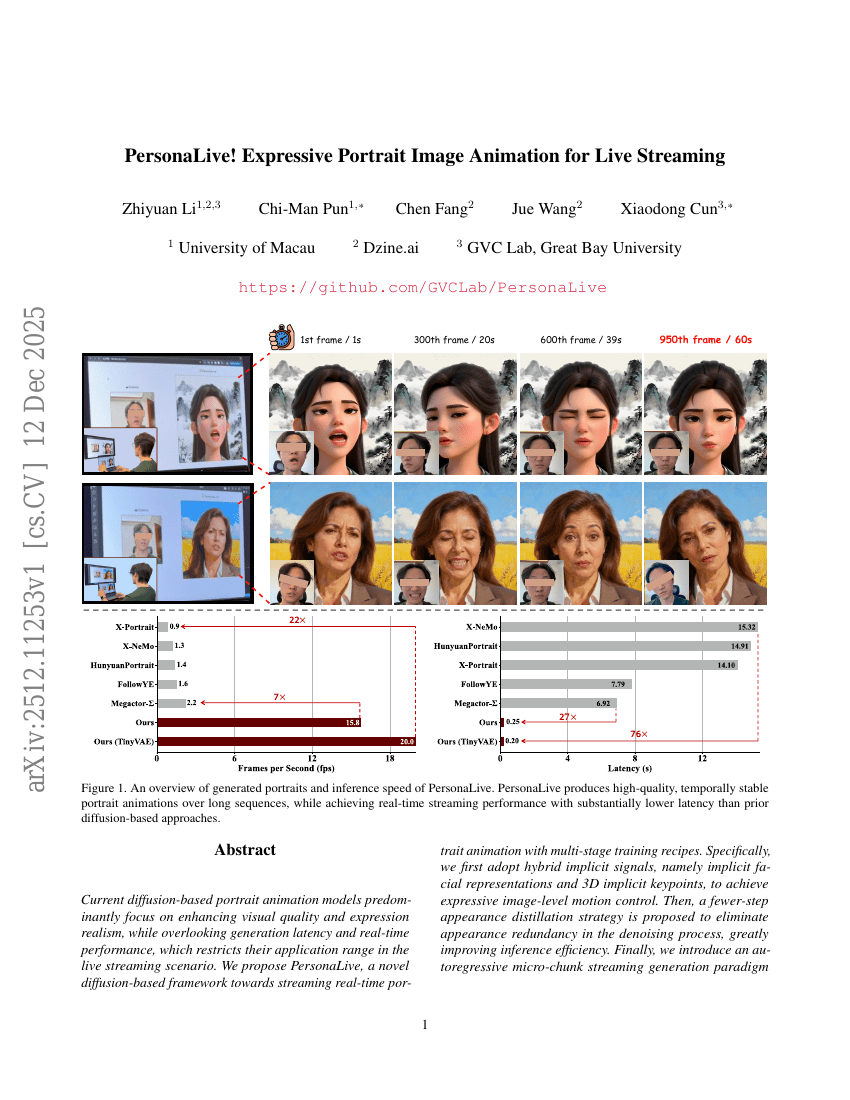
PersonaLive! ライブストリーミング向け表現力豊かなポートレート画像アニメーション
V-RGBX:内在特性に対する正確な制御を備えた動画編集
SVG-T2I:変分自己符号化器を用いずにテキストから画像への潜在拡散モデルのスケーリングアップ
DentalGPT:歯科におけるマルチモーダルな複雑な推論を促進するためのアプローチ
LLMCache:Transformer推論における高速再利用のための階層的キャッシュ戦略
OPENTOUCH:現実世界のインタラクションにフルハンドタッチをもたらす
VideoRewardBench:動画理解におけるマルチモーダル報酬モデルの包括的評価
ソウル:高精度な長期マルチモーダルアニメーションのためのデジタル人間への生命の息吹き
IF-Bench:生成視覚を用いた赤外線画像におけるMLLMのベンチマーク評価と性能向上
RecGPT-V2 技ical Report
ベクトルプリズム:意味構造の階層化によるベクトルグラフィックスのアニメーション化
OpenDataArena:ポストトレーニングデータセット価値のベンチマーク評価のための公正でオープンなアリーナ
ビデオリアリティテスト:AI生成ASMR動画はVLMおよび人間を欺くことができるか?
WorldPlay:リアルタイムインタラクティブなワールドモデリングにおける長期的幾何学的一貫性の実現へ
MMGR:マルチモーダル・ジェネレーティブ・リーズニング
フロンティアサイエンス:AIが専門家レベルの科学的タスクを実行する能力の評価
FACTS Leaderboard:大規模言語モデルの事実性を評価する包括的なベンチマーク
Nemotron-Cascade:汎用推論モデル向けカスケード強化学習のスケーリング
KlingAvatar 2.0 技術報告
QwenLong-L1.5:長文脈推論およびメモリ管理のためのポストトレーニングレシピ
ReFusion:並列自己回帰デコーディングを備えた拡散大規模言語モデル
エラーフリーな線形アテンションはフリーランチである:連続時間ダイナミクスからの正確な解
AIエージェントの時代における記憶
LongVie 2:マルチモーダル制御可能 Ultra-Long Video World Model
FirstAidQA:低接続環境における救急対応向けの合成データセット
CUDA-L2:強化学習を活用した行列積演算におけるcuBLASを凌駕する性能
X-VLA:スケーラブルなクロスエン bodiment 視覚言語行動モデルとしてのソフトプロンプト付きトランスフォーマー
Nemotron 3 Nano:エージェンティックな推論向けに最適化されたオープンで効率的なMixture-of-Experts型ハイブリッドMamba-Transformerモデル
トラッキングからの構造:動画生成のための構造保存型運動の蒸留
MetaCanvasを用いたMLLM-Diffusion間情報伝達の探求
PersonaLive! ライブストリーミング向け表現力豊かなポートレート画像アニメーション
V-RGBX:内在特性に対する正確な制御を備えた動画編集
SVG-T2I:変分自己符号化器を用いずにテキストから画像への潜在拡散モデルのスケーリングアップ
DentalGPT:歯科におけるマルチモーダルな複雑な推論を促進するためのアプローチ