Command Palette
Search for a command to run...
TongSIM:知能機械のシミュレーションを目的とした汎用プラットフォーム
TongSIM:知能機械のシミュレーションを目的とした汎用プラットフォーム
概要
人工知能(AI)の急速な進展、特にマルチモーダル大規模言語モデル(MLLM)の発展に伴い、研究の焦点は単一モーダルなテキスト処理から、より複雑なマルチモーダルおよび身体化知能(embodied AI)の領域へと移行しつつある。身体化知能は、従来のラベル付きデータセットに依存するのではなく、現実的なシミュレーション環境内にエージェントを配置し、物理的相互作用や行動フィードバックを活用して学習を進める。しかし、現存する大多数のシミュレーションプラットフォームは、特定のタスクに特化した狭義の設計にとどまっており、低レベルの身体化ナビゲーションから高レベルの複合的活動(多エージェント社会シミュレーションや人間-AI協働など)までを統合的にサポートできる汎用的な訓練環境は、依然としてほとんど存在しない。このギャップを埋めるために、本研究ではTongSIMを提案する。TongSIMは、高忠実度かつ汎用性に優れたエージェントの訓練・評価を可能にするプラットフォームである。TongSIMは、100以上に及ぶ多様な室内シナリオ(複数の部屋構成)と、自由に拡張可能なインタラクション豊富な屋外街並みのシミュレーションを提供することで、幅広い研究ニーズに応じた実用的利点を有している。また、知覚、認知、意思決定、人ロボット協働、空間的・社会的推論といったエージェントの能力を精緻に評価できる包括的な評価フレームワークとベンチマークを備えている。カスタマイズ可能なシーン、タスクに応じた忠実度調整、多様なエージェントタイプ、動的環境シミュレーションといった特徴により、TongSIMは研究者にとって柔軟性とスケーラビリティを提供し、汎用的な身体化知能の実現に向けた訓練・評価の加速を支える統合的プラットフォームとしての役割を果たす。
One-sentence Summary
BIGAI researchers et al. propose TongSIM, a high-fidelity general-purpose embodied AI platform overcoming narrow task-specific simulators through 100+ multi-room indoor scenarios and an open-ended outdoor town. It enables unified training and evaluation of navigation, social simulation, and human-AI collaboration via customizable scenes and dynamic environmental fidelity, advancing scalable research toward general embodied intelligence.
Key Contributions
- Current embodied AI simulation platforms are narrowly task-specific, lacking a versatile environment that supports both low-level navigation and high-level composite activities like multi-agent social simulations and human-AI collaboration.
- TongSIM introduces a high-fidelity, general-purpose platform featuring over 100 diverse indoor scenarios and an open-ended outdoor town simulation, with customizable scenes, task-adaptive fidelity, diverse agent embodiments, and dynamic environmental simulation for flexible agent training.
- The platform provides a comprehensive evaluation framework with five benchmark categories covering single-agent, multi-agent, human-robot interaction, and family composite tasks to assess agent capabilities in perception, cognition, decision-making, and social reasoning.
Introduction
Embodied AI research increasingly requires realistic simulation environments to train agents through physical interaction rather than labeled datasets, moving beyond single-modality text processing toward multimodal and social intelligence. However, existing platforms remain narrowly designed for specific tasks like navigation or object manipulation, forcing researchers to choose between high-speed simulation with simplified physics or high-fidelity physics with impractical computational costs, while lacking support for complex scenarios such as multi-agent social dynamics or human-AI collaboration. The authors leverage these gaps to introduce TongSIM, a unified high-fidelity platform featuring over 100 diverse indoor scenes and an open-world outdoor town simulation. It uniquely supports both low-level embodied navigation and high-level composite tasks through customizable environments, task-adaptive fidelity, and a comprehensive benchmark suite evaluating perception, spatial reasoning, and social interaction—enabling scalable training and evaluation of general embodied intelligence.
Dataset
The authors use the TongSIM platform to provide diverse simulation environments for agent training and evaluation, structured as follows:
-
Dataset composition and sources:
The dataset comprises 115 expert-designed indoor scenes and a unified urban-scale outdoor metropolis, both generated via the TongSIM simulation platform. -
Key subset details:
- Indoor scenes (115 total): Manually curated by professional designers to ensure semantic realism and adherence to anthropomorphic behavioral logic. Covers residential units, cafes, and retail stores across architectural styles (modern, medieval, traditional Japanese/Chinese). Expanded via an automated pipeline from initial expert layouts.
- Outdoor scenarios: A contiguous virtual metropolis integrating educational, residential, commercial, and medical zones with a full road network and dynamic traffic system. Enables seamless long-horizon navigation across spatially connected regions.
-
Usage in the paper:
The data trains and evaluates agents in the Multi-Agent Cooperative Search (MACS) benchmark—a post-flood scenario requiring collaboration under partial observability. Key tasks include:- Multi-agent supply collection
- Evasion of stochastic dynamic hazards
- Energy-efficient navigation using local sensory data
Environments are configured with a continuous 2D action space (Box(-1.0, 1.0)) and high-dimensional observations from radial ray-casting sensors.
-
Processing and metadata:
Indoor scenes undergo automated expansion from expert layouts; outdoor zones maintain spatial continuity for contextual navigation. The MACS task implements radial ray-casting to simulate partial observability (visualized via green sensor lines), with agent sensory ranges defined by blue-dotted circumferences in training arrays. No explicit cropping is applied—the platform leverages full-scene continuity for holistic task execution.
Method
The authors leverage a modular, engine-driven architecture to construct TongSIM, a simulation platform designed for embodied AI research. At its core, the system integrates Unreal Engine 5.6 with a Python-based control layer, enabling bidirectional communication between high-fidelity rendering and programmatic agent manipulation. This dual-stack design facilitates both low-level physics simulation and high-level task orchestration, forming the backbone for scalable agent training and evaluation.
Refer to the framework diagram, which illustrates the platform’s layered structure. The infrastructure layer combines Unreal Engine’s native rendering and physics capabilities with a Python SDK, allowing developers to dynamically instantiate objects, manage scenes, and retrieve real-time state data—including semantic segmentation, object metadata, and navigation meshes. This interface supports granular control over agent embodiments, enabling the execution of both kinematic primitives and complex, multi-step interactions such as pouring liquids or assembling furniture.
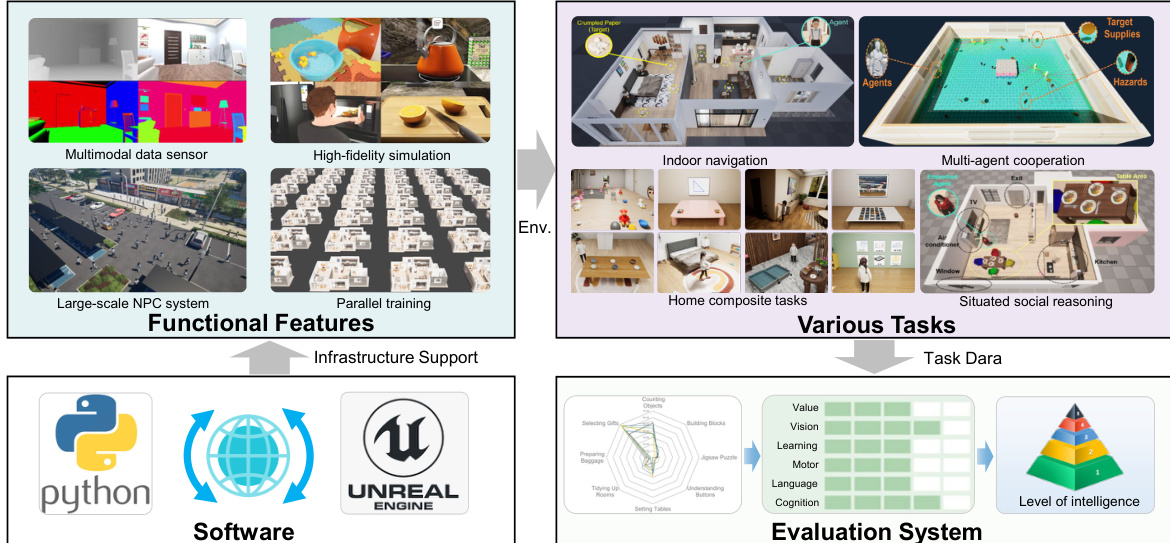
The simulation environment is enriched with four key functional modules: multimodal data sensors for perception, high-fidelity rendering for visual realism, a large-scale NPC system for social dynamics, and parallel training infrastructure for scalable experimentation. These modules collectively support diverse embodied tasks—from indoor navigation and home composite activities to multi-agent cooperation and situated social reasoning. Each environment is equipped with a Scene Manager that provides ground-truth data, including spawn points, semantic annotations, and baked navigation meshes, enabling both rule-based and learning-based agent control.
To ensure environmental diversity and generalizability, the authors implement a procedural generation pipeline that operates in two phases. In the coarse-grained stage, existing indoor scenes are decomposed into functional units (e.g., kitchen, bedroom) and stochastically recombined using door frames as alignment anchors. In the fine-grained stage, micro-variations are introduced through randomized object placement and asset substitution from a curated object library. This process is validated through human-in-the-loop curation to eliminate semantically implausible configurations.
The platform’s agent system supports both AI-driven embodiments and rule-based NPCs, governed by a hybrid control mechanism that combines deterministic logic with LLM-driven decision-making. Agents are equipped with a rich action space spanning low-level motor primitives, target-driven navigation, and high-level composite behaviors. Interaction with objects is mediated through a protocol-based system that defines 28 distinct interaction primitives, including electromechanical logic (decoupling power state from activation state) and spatial interaction anchors (e.g., placement points for precise object docking).
For physical realism, TongSIM leverages Unreal’s Chaos physics engine to simulate rigid bodies, fluids, and deformable materials. The authors also integrate NVIDIA Flex as an experimental extension, enabling unified particle-based simulation across heterogeneous object types. This capability is critical for evaluating embodied agents under real-world physical constraints, such as accounting for center-of-mass shifts when manipulating liquid-filled containers.
The evaluation framework is structured hierarchically, assessing agents across multiple dimensions: from low-level locomotion and perception to high-level social intelligence and multi-agent collaboration. A standardized testing pipeline is introduced for complex tasks such as seating arrangement, which requires agents to extract NPC preferences, construct environmental representations, and generate multi-constraint solutions. Performance is quantified using metrics like the prioritization gap (PG), defined as:
PG=Shigh−Slowwhere Shigh and Slow denote the satisfaction rates of high- and low-weighted preferences, respectively.
As shown in the figure below, the platform also supports real-time robot simulation with standard ROS2 interfaces, enabling seamless integration with robotic control stacks. This bridge facilitates testing in dynamic social environments, where agents must navigate photorealistic crowds and respond to safety-critical scenarios such as halting for pedestrians.

Finally, the platform enables situated planning tasks, such as social seating arrangement, where agents must synthesize environmental knowledge, NPC preferences, and spatial constraints to generate optimal configurations. This workflow, depicted in the figure below, illustrates how embodied exploration, social interaction modeling, and situated planning converge to evaluate high-level reasoning under real-world constraints.
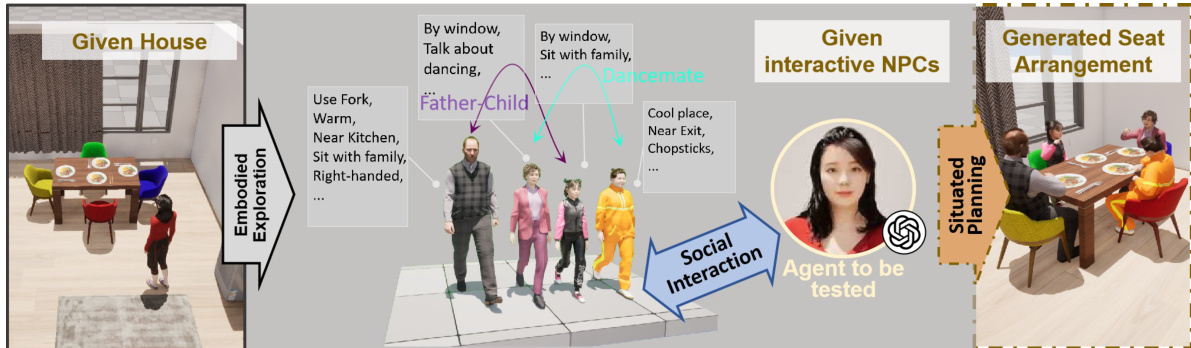
The architecture is extensible, supporting custom task creation via standardized APIs and third-party asset import (glTF, FBX, Datasmith). This flexibility allows researchers to construct domain-specific scenarios—from domestic service tasks to extreme environment operations—without being constrained by predefined benchmarks.
Experiment
- Parallel training mechanism validated on spatial exploration task: achieved near-linear scaling in steps per second with increased environments, saturating at high parallelism due to system overhead.
- Spatial exploration benchmark (cleanup task): PPO RL agent achieved 60% success rate, significantly lagging behind human performance due to poor obstacle avoidance and long-horizon navigation.
- MARL evaluation on MACS Task: MAPPO outperformed IPPO with 19.24 vs. 14.75 mean episodic return per agent, confirming centralized training’s effectiveness for multi-agent coordination.
- Social navigation in dynamic crowds: Human teleoperation scored 92.7 total, while MPPI planner reached 43.1 and DWA failed (10.4), highlighting traditional planners’ lack of social cognition.
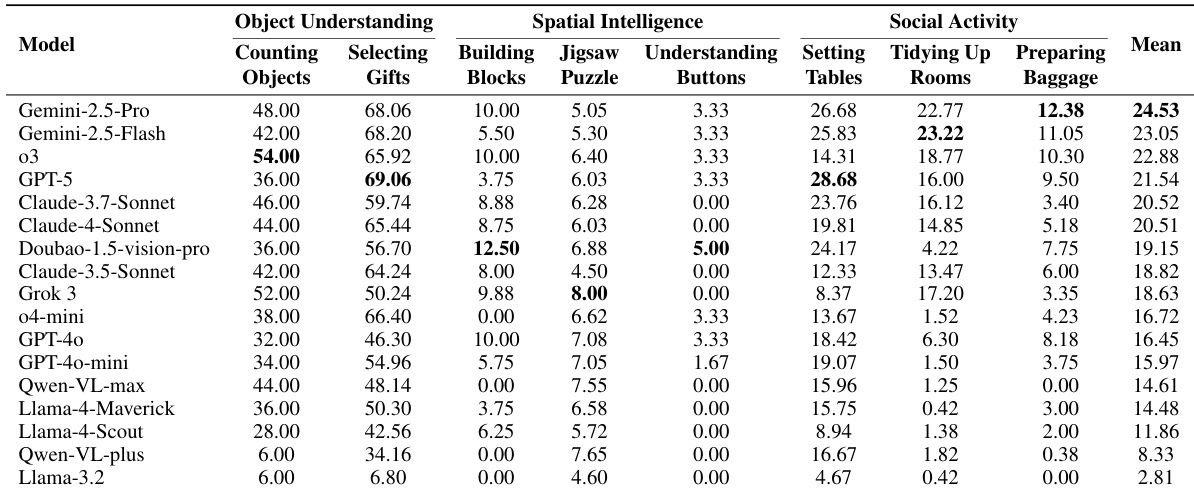
- MLLM assessment on household tasks: Gemini-2.5-Pro led at 24.53/100 average score, with spatial intelligence identified as the weakest domain across all models.
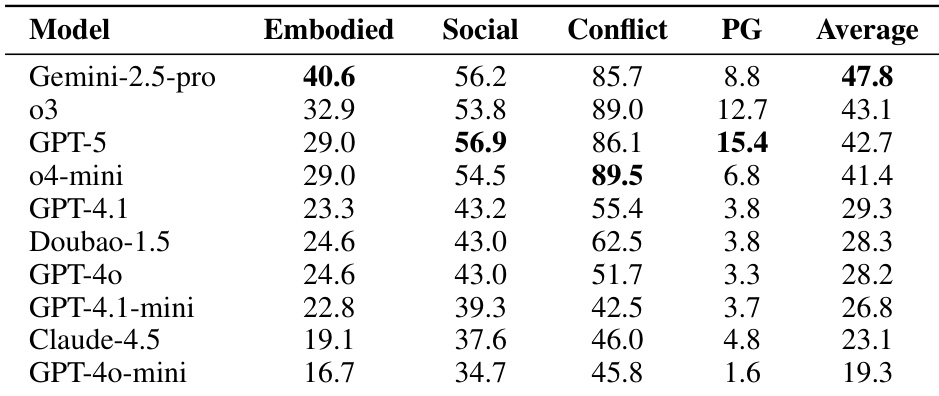
- S³IT benchmark: Gemini-2.5-Pro achieved 47.8, demonstrating spatial intelligence as foundational for embodied social reasoning while models consistently underperformed in embodied dimensions.
The authors evaluate three navigation strategies in a crowded social environment using metrics for efficiency, success rate, safety, and social norm compliance. Human teleoperation achieves the highest total score of 92.7, significantly outperforming both automated planners, with A* + DWA scoring only 10.4 due to frequent collisions and zero safety compliance, while A* + MPPI improves to 43.1 but still lags far behind human performance. Results confirm that traditional planners lacking social reasoning fail to navigate dynamic crowds safely or appropriately.

The authors evaluate a PPO-trained RL agent against human operators on a spatial exploration and navigation task, finding the agent achieves a 60% success rate and 0.34 efficiency, significantly lower than the human baseline of 100% success and 0.54 efficiency. Results indicate the agent struggles with obstacle avoidance and long-horizon navigation in cluttered environments.

Results show that Gemini-2.5-pro achieves the highest average score of 47.8 on the S³IT benchmark, outperforming all other models primarily due to its superior performance in the embodied dimension (40.6). All models exhibit consistently lower scores in embodied and social dimensions compared to conflict resolution, confirming spatial intelligence as a critical bottleneck for embodied social reasoning. GPT-5 demonstrates the strongest ability to prioritize preferences, reflected in its highest prioritization gap score of 15.4.
The authors evaluate two multi-agent reinforcement learning algorithms on a cooperative task, finding that MAPPO under the centralized training with decentralized execution paradigm achieves a higher mean episodic return per agent (19.24) compared to the fully decentralized IPPO (14.75). Results show both learning-based methods significantly outperform the random policy baseline, indicating that leveraging global state information during training improves coordination among agents.

The authors evaluate 17 MLLMs on a composite embodied task benchmark spanning object understanding, spatial intelligence, and social activity domains. Results show that even the top-performing model, Gemini-2.5-Pro, achieves only a mean score of 24.53 out of 100, revealing a substantial gap in embodied reasoning capabilities. Spatial intelligence tasks, such as block building and puzzle solving, consistently yield the lowest scores across all models, highlighting a critical weakness in physical reasoning and manipulation planning.