HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

FutureOmni:マルチモーダルLLMにおけるオムニモーダルコンテキストからの将来予測の評価

Being-H0.5:クロスエムボディメント一般化のためのヒューマンセントリックロボット学習のスケーリング


























FutureOmni:マルチモーダルLLMにおけるオムニモーダルコンテキストからの将来予測の評価
Being-H0.5:クロスエムボディメント一般化のためのヒューマンセントリックロボット学習のスケーリング
LLMを活用したソフトウェア工学における問題解決の進展と先端的研究:包括的サーベイ
Nemotron-Math: マルチモード学習による数学的推論の効率的な長文脈(Long-Context)蒸留
Gemini向けの本番環境対応プローブの構築
LFM2 技術報告
CoDance:ロバストなマルチサブジェクトアニメーションのためのアンバインド・リバインドパラダイム
アシスタント軸:言語モデルのデフォルト・ペルソナの位置づけと安定化
ABC-Bench:現実世界の開発におけるエージェント型バックエンドコーディングのベンチマーク
マルチプレックス思考:トークン単位の分岐・統合による推論
推論モデルが思考の社会を生成する
マルチエージェントAIシステムの開発と課題に関する大規模研究
ACoT-VLA:視覚言語行動モデルにおけるアクション・チェーン・オブ・シンキング
パーソナライゼーションが誤解を招くとき:パーソナライズドLLMにおける幻覚の理解と緩和
RubricHub:自動的コアス・トゥ・ファイン生成による包括的かつ高判別力なルーブリックデータセット
隠れた経験の解禁:テキストからツール利用軌道を合成する
ポイズンド・アップル効果:AIエージェントの技術拡張を用いた中間市場の戦略的操作
あなたのグループ相対優位はバイアスされている
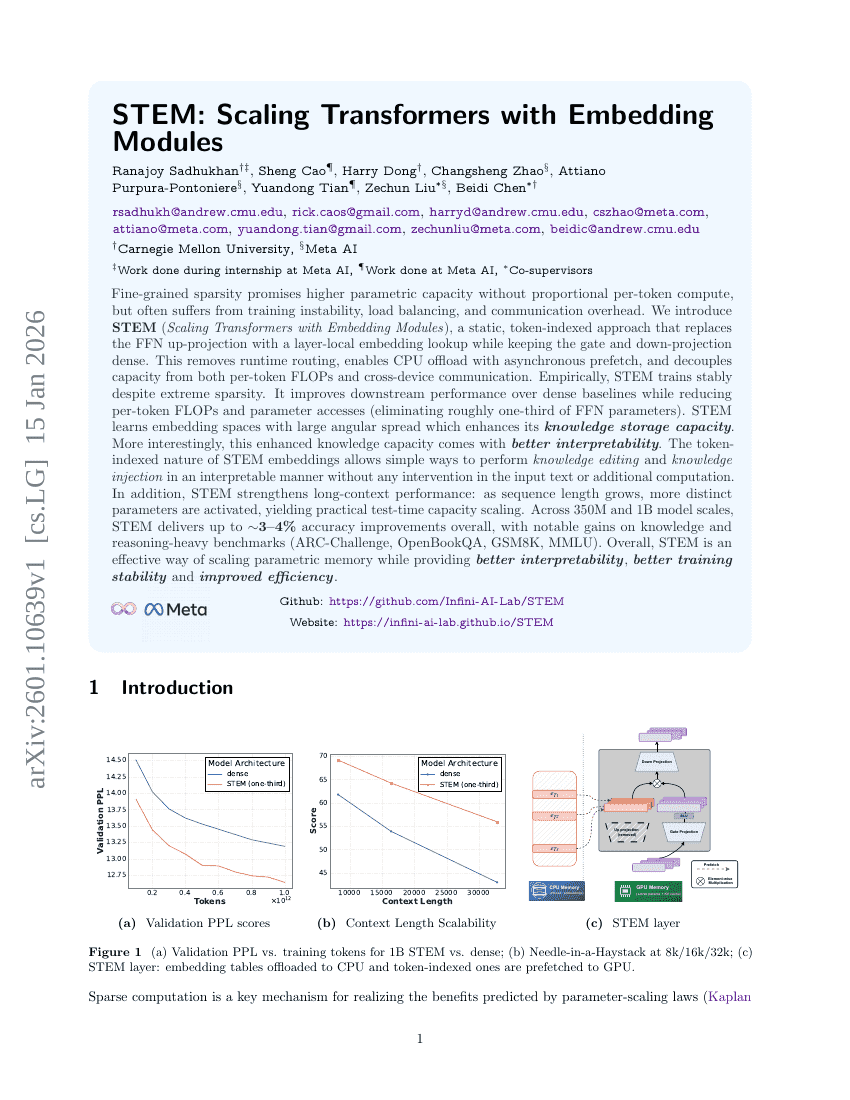
STEM:埋め込みモジュールを用いたTransformerのスケーリング
ノイズの中での喪失:文脈的干渉要因により推論モデルが失敗する理由
静的ツールを越えて:科学的推論におけるテスト時ツール進化
VIBE:視覚指令に基づくエディタ
推論のための協調的マルチエージェント・テスト時強化学習
レアなものを報酬する:LLMにおける創造的問題解決のための独自性認識型RL
都市におけるビジュアル・ランゲージ推論を用いたソーシャル意味セグメンテーション
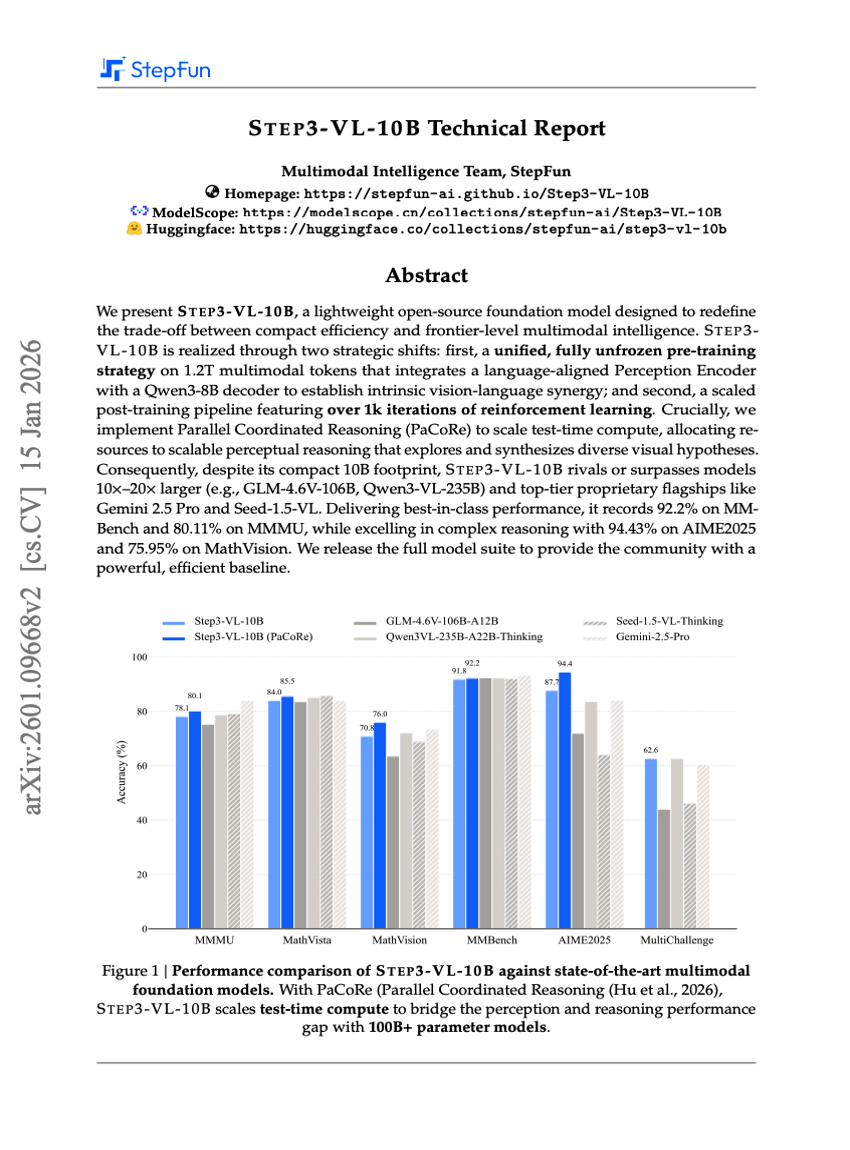
STEP3-VL-10B 技術報告
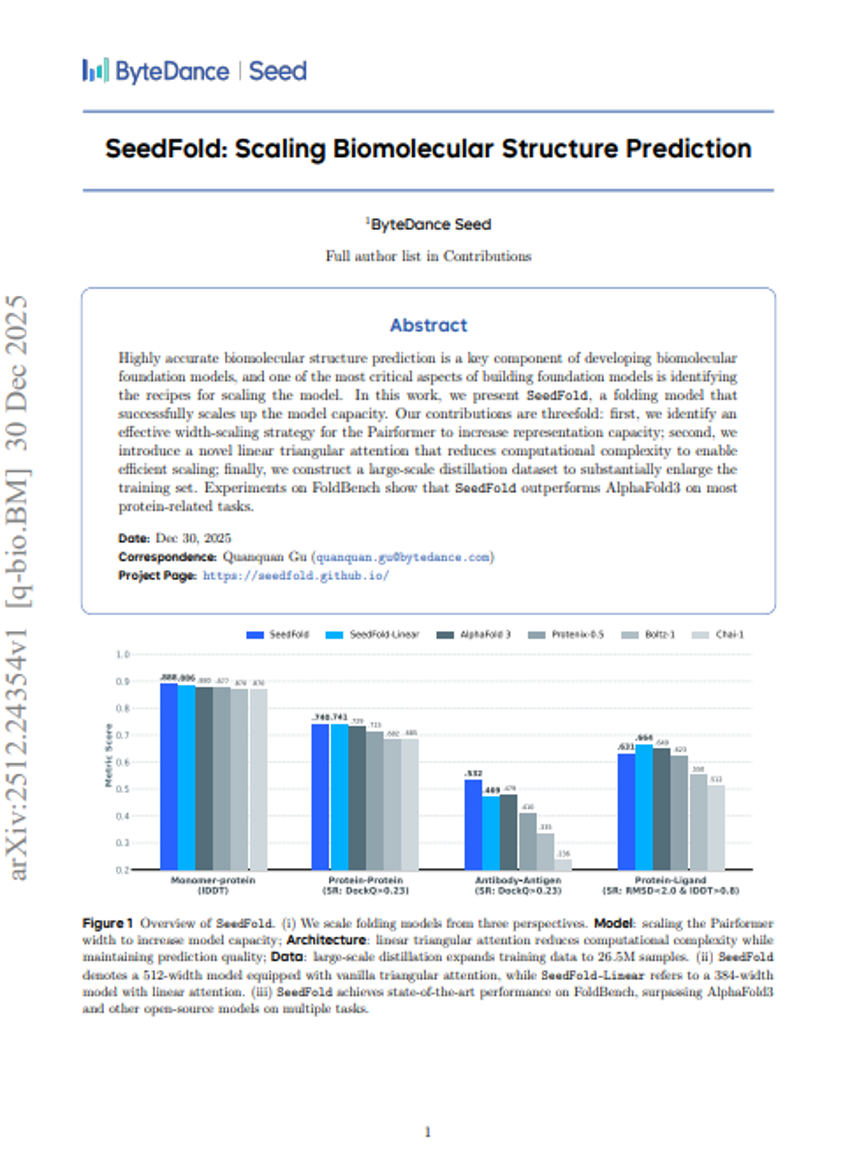
SeedFold:バイオ分子構造予測のスケーリング
Gemma技術報告
Fast-ThinkAct:語彙化可能な潜在的計画を用いた効率的な視覚言語行動推論
SkinFlow:動的視覚符号化と段階的RLを活用したオープン皮膚科診断における効率的な情報伝送
A^3-Bench:アンカーおよびアトラクタ活性化を用いたメモリ駆動型科学的推論のベンチマーク
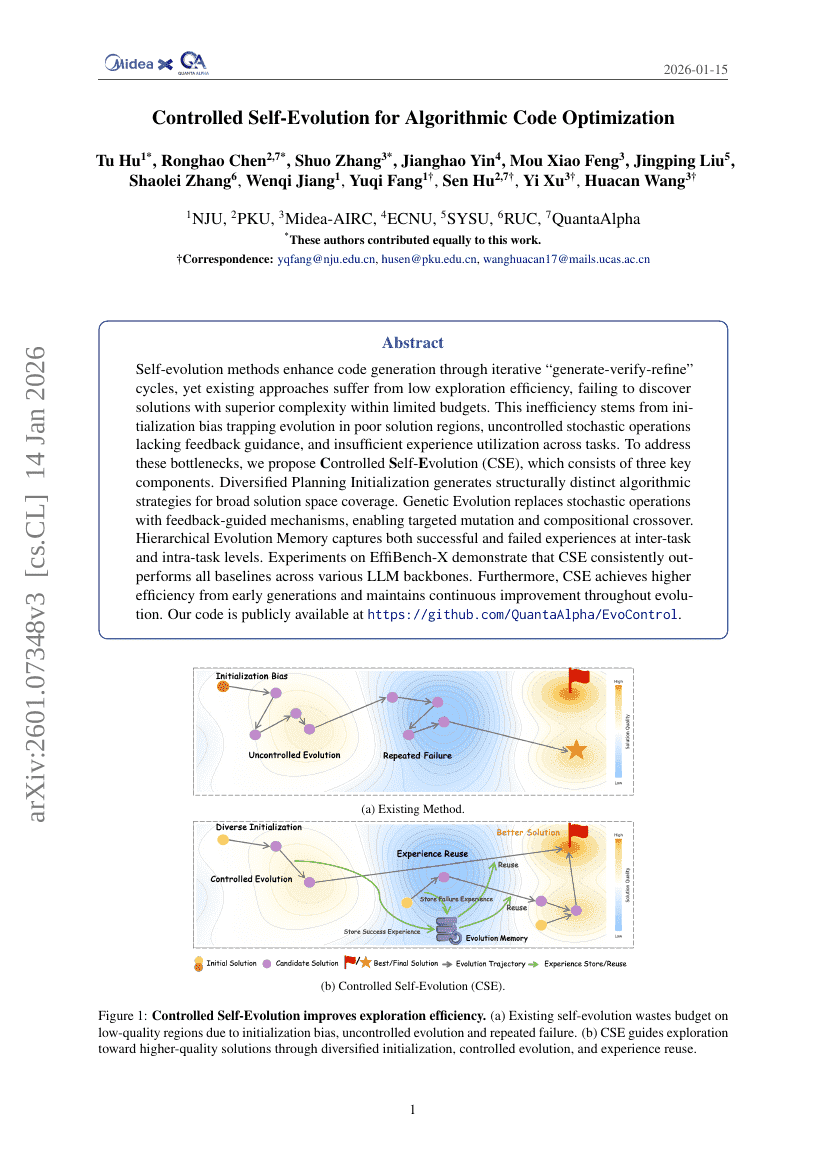
アルゴリズムコード最適化のための制御された自己進化
LLMを活用したソフトウェア工学における問題解決の進展と先端的研究:包括的サーベイ
Nemotron-Math: マルチモード学習による数学的推論の効率的な長文脈(Long-Context)蒸留
Gemini向けの本番環境対応プローブの構築
LFM2 技術報告
CoDance:ロバストなマルチサブジェクトアニメーションのためのアンバインド・リバインドパラダイム
アシスタント軸:言語モデルのデフォルト・ペルソナの位置づけと安定化
ABC-Bench:現実世界の開発におけるエージェント型バックエンドコーディングのベンチマーク
マルチプレックス思考:トークン単位の分岐・統合による推論
推論モデルが思考の社会を生成する
マルチエージェントAIシステムの開発と課題に関する大規模研究
ACoT-VLA:視覚言語行動モデルにおけるアクション・チェーン・オブ・シンキング
パーソナライゼーションが誤解を招くとき:パーソナライズドLLMにおける幻覚の理解と緩和
RubricHub:自動的コアス・トゥ・ファイン生成による包括的かつ高判別力なルーブリックデータセット
隠れた経験の解禁:テキストからツール利用軌道を合成する
ポイズンド・アップル効果:AIエージェントの技術拡張を用いた中間市場の戦略的操作
あなたのグループ相対優位はバイアスされている
STEM:埋め込みモジュールを用いたTransformerのスケーリング
ノイズの中での喪失:文脈的干渉要因により推論モデルが失敗する理由
静的ツールを越えて:科学的推論におけるテスト時ツール進化
VIBE:視覚指令に基づくエディタ
推論のための協調的マルチエージェント・テスト時強化学習
レアなものを報酬する:LLMにおける創造的問題解決のための独自性認識型RL
都市におけるビジュアル・ランゲージ推論を用いたソーシャル意味セグメンテーション
STEP3-VL-10B 技術報告
SeedFold:バイオ分子構造予測のスケーリング
Gemma技術報告
Fast-ThinkAct:語彙化可能な潜在的計画を用いた効率的な視覚言語行動推論
SkinFlow:動的視覚符号化と段階的RLを活用したオープン皮膚科診断における効率的な情報伝送
A^3-Bench:アンカーおよびアトラクタ活性化を用いたメモリ駆動型科学的推論のベンチマーク
アルゴリズムコード最適化のための制御された自己進化