HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

戦略入札を用いた小規模エージェントのスケーリング

バイブAIGC:エージェント統合によるコンテンツ生成の新たなパラダイム


























戦略入札を用いた小規模エージェントのスケーリング
バイブAIGC:エージェント統合によるコンテンツ生成の新たなパラダイム
PaperSearchQA:RLVRを用いた科学論文における検索と推論の学習
EgoActor:視覚言語モデルを活用した空間認識型自己中心行動へのタスク計画の根拠化による人間型ロボット向けアプローチ
A-RAG:階層的リトリーブインターフェースを活用したエージェント型リトリーブ増強生成のスケーラビリティ向上
Quant VideoGen:2ビットKVキャッシュ量子化を用いた自己回帰型長時間動画生成
SoMA:ロボット柔体操作における現実世界からシミュレーションへのニューラルシミュレータ
3Dアウェアな暗黙的モーション制御を用いた視点適応型人体動画生成
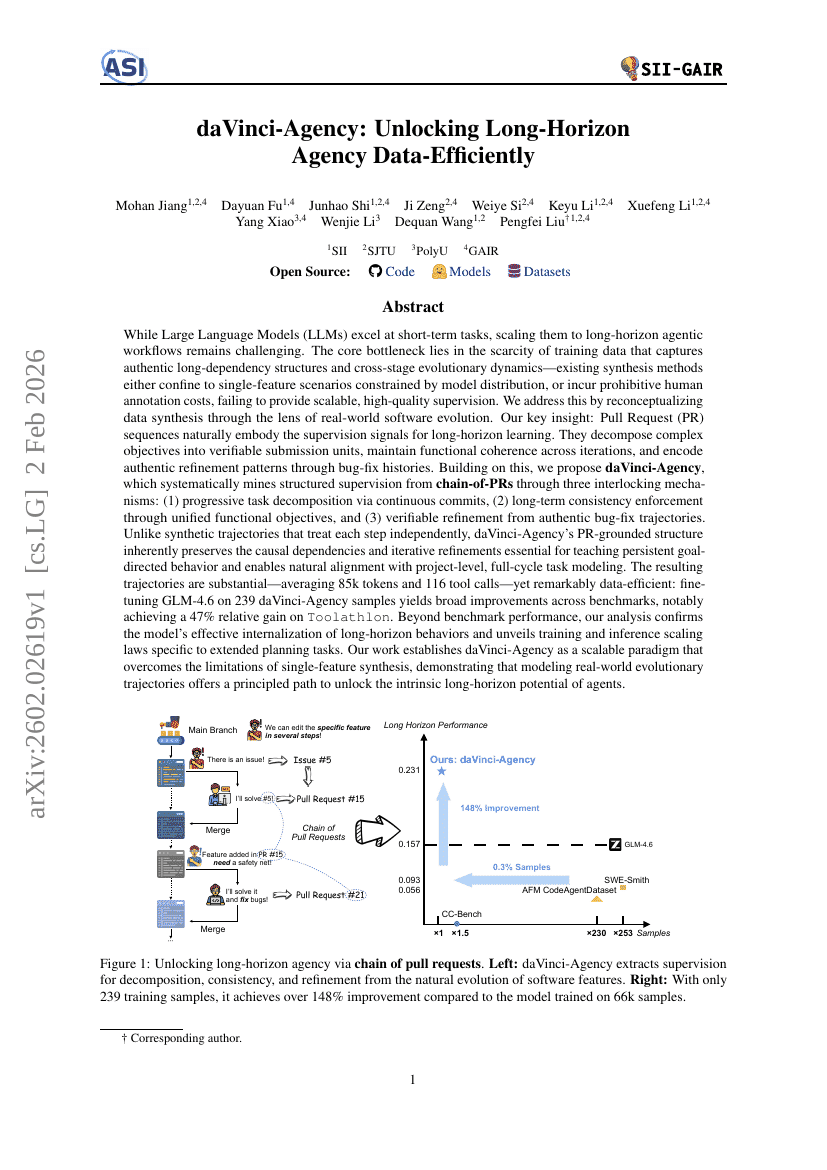
daVinci-Agency:長期スパンのエージェンシー・データを効率的に活用する
世界モデルに関する研究は、単に特定のタスクに世界知識を注入するものにとどまらない
AOrchestra:エージェントオーケストレーションにおけるサブエージェント作成の自動化
チェーン・オブ・シンキングにおけるグローバル・プランの不在:LLMの潜在的計画ホライズンの解明
CodeOCR:視覚言語モデルのコード理解における有効性について
DeepPlanning:検証可能な制約条件を用いた長期予測エージェント計画のベンチマーク
CL-bench:コンテキスト学習のためのベンチマーク
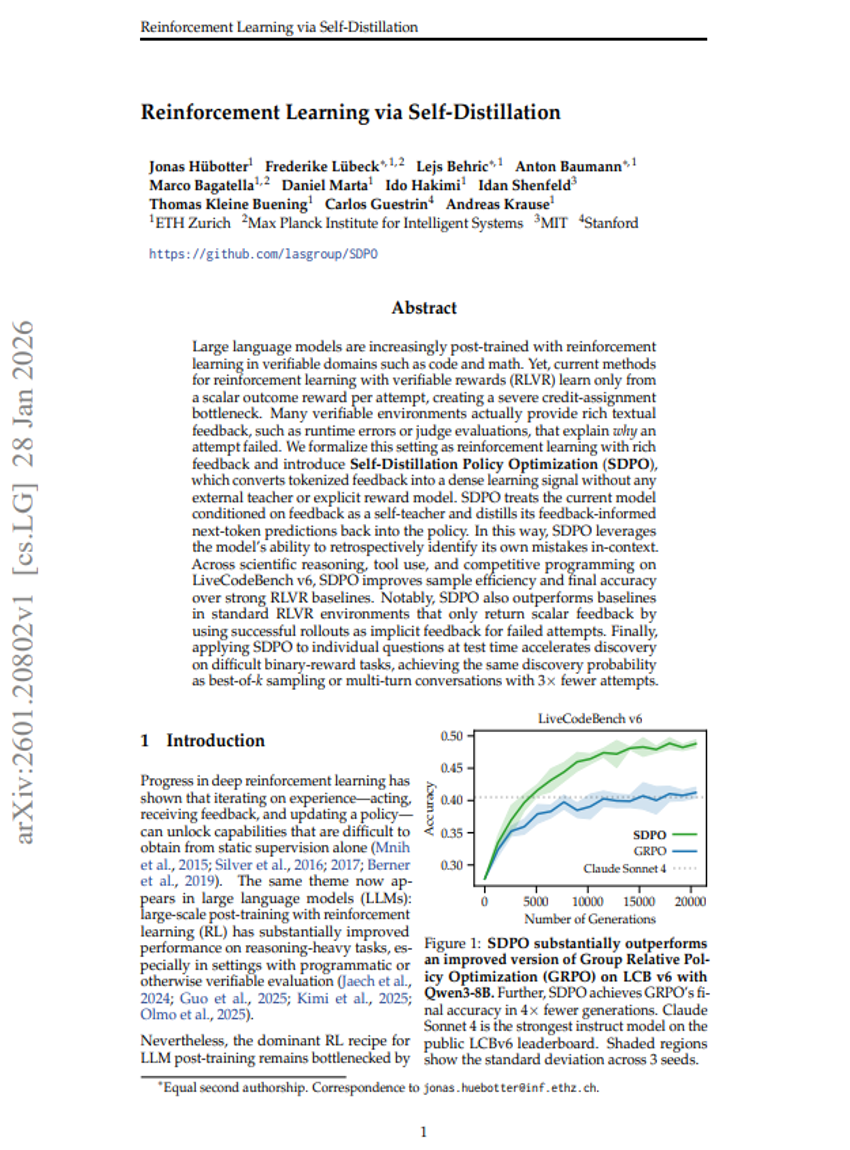
自己蒸留を用いた強化学習
チャットボットを社交的コンパニオンとして:人々が機械における意識、人間らしさ、および社会的健康上の利点をどのように認識しているか
POPE:専用オンポリシー探索を活用した難問における推論の学習
UniReason 1.0:世界知識の整合型画像生成および編集を実現する統一推論フレームワーク
ループを閉じる:RPG-Encoderを用いたユニバーサルリポジトリ表現
ビジョン・ディープリサーチベンチマーク:マルチモーダル大規模言語モデルにおける視覚的およびテキスト検索の再考
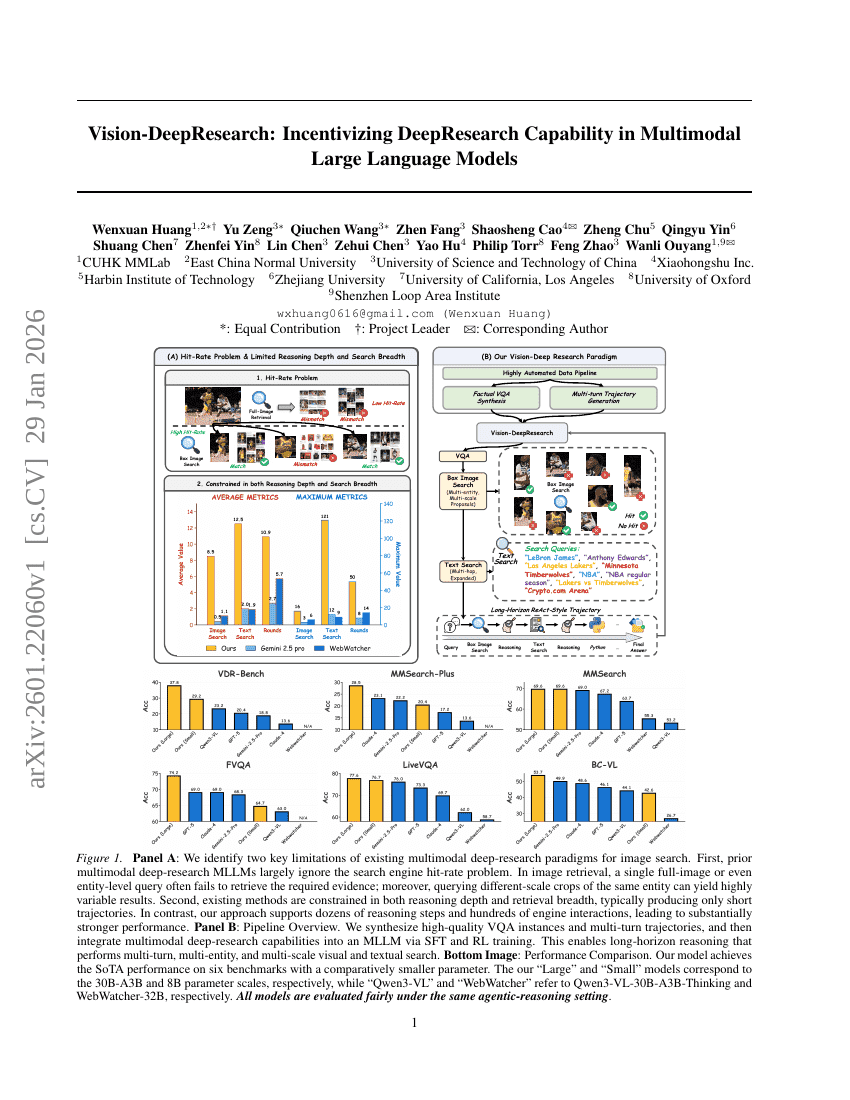
ビジョン・ディープリサーチ:マルチモーダル大規模言語モデルにおけるディープリサーチ能力の促進
Kimi K2.5:視覚的エージェント知能
Green-VLA:汎用ロボット向けの段階的ビジュアル・言語・アクションモデル
PaperBanana:AI研究者のための学術図解の自動化
Geminiを用いた準自律的数学発見:Erdős問題に関する事例研究
潜在チェーン・オブ・シンキングを計画として:推論と言語化を分離する
リアルタイム対応型の意味論を超える報酬モデル
DenseGRPO:フローマッチングモデルの整合性向上のためのスパースからディンスな報酬へ
DreamActor-M2:時空間的コントキスト学習を用いたユニバーサルなキャラクター画像アニメーション
TTCS:自己進化型におけるテスト時カリキュラム合成
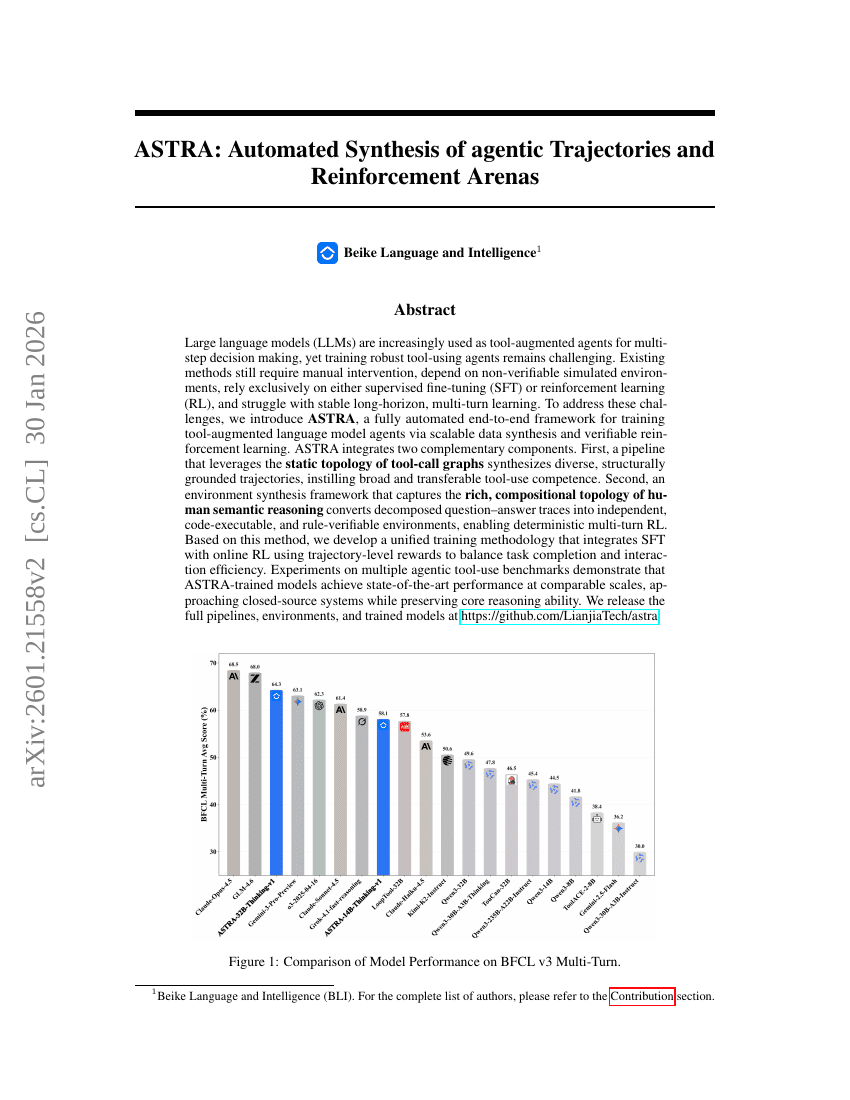
ASTRA:エージェント軌道および強化学習アリーナの自動合成
PaperSearchQA:RLVRを用いた科学論文における検索と推論の学習
EgoActor:視覚言語モデルを活用した空間認識型自己中心行動へのタスク計画の根拠化による人間型ロボット向けアプローチ
A-RAG:階層的リトリーブインターフェースを活用したエージェント型リトリーブ増強生成のスケーラビリティ向上
Quant VideoGen:2ビットKVキャッシュ量子化を用いた自己回帰型長時間動画生成
SoMA:ロボット柔体操作における現実世界からシミュレーションへのニューラルシミュレータ
3Dアウェアな暗黙的モーション制御を用いた視点適応型人体動画生成
daVinci-Agency:長期スパンのエージェンシー・データを効率的に活用する
世界モデルに関する研究は、単に特定のタスクに世界知識を注入するものにとどまらない
AOrchestra:エージェントオーケストレーションにおけるサブエージェント作成の自動化
チェーン・オブ・シンキングにおけるグローバル・プランの不在:LLMの潜在的計画ホライズンの解明
CodeOCR:視覚言語モデルのコード理解における有効性について
DeepPlanning:検証可能な制約条件を用いた長期予測エージェント計画のベンチマーク
CL-bench:コンテキスト学習のためのベンチマーク
自己蒸留を用いた強化学習
チャットボットを社交的コンパニオンとして:人々が機械における意識、人間らしさ、および社会的健康上の利点をどのように認識しているか
POPE:専用オンポリシー探索を活用した難問における推論の学習
UniReason 1.0:世界知識の整合型画像生成および編集を実現する統一推論フレームワーク
ループを閉じる:RPG-Encoderを用いたユニバーサルリポジトリ表現
ビジョン・ディープリサーチベンチマーク:マルチモーダル大規模言語モデルにおける視覚的およびテキスト検索の再考
ビジョン・ディープリサーチ:マルチモーダル大規模言語モデルにおけるディープリサーチ能力の促進
Kimi K2.5:視覚的エージェント知能
Green-VLA:汎用ロボット向けの段階的ビジュアル・言語・アクションモデル
PaperBanana:AI研究者のための学術図解の自動化
Geminiを用いた準自律的数学発見:Erdős問題に関する事例研究
潜在チェーン・オブ・シンキングを計画として:推論と言語化を分離する
リアルタイム対応型の意味論を超える報酬モデル
DenseGRPO:フローマッチングモデルの整合性向上のためのスパースからディンスな報酬へ
DreamActor-M2:時空間的コントキスト学習を用いたユニバーサルなキャラクター画像アニメーション
TTCS:自己進化型におけるテスト時カリキュラム合成
ASTRA:エージェント軌道および強化学習アリーナの自動合成