Command Palette
Search for a command to run...
Fast-ThinkAct:語彙化可能な潜在的計画を用いた効率的な視覚言語行動推論
Fast-ThinkAct:語彙化可能な潜在的計画を用いた効率的な視覚言語行動推論
Chi-Pin Huang Yunze Man Zhiding Yu Min-Hung Chen Jan Kautz Yu-Chiang Frank Wang Fu-En Yang
概要
視覚・言語・行動(Vision-Language-Action: VLA)タスクは、複雑な視覚シーンに対する推論と、動的環境における適応的行動の実行を要する。近年のVLA推論に関する研究では、明示的な連鎖的思考(Chain-of-Thought: CoT)が汎化性能の向上に寄与することが示されているが、長大な推論経路により推論遅延が高くなるという課題がある。本研究では、言語化可能な潜在的推論を用いて、コンパクトでありながら高い性能を発揮する計画能力を実現する効率的な推論フレームワーク「Fast-ThinkAct」を提案する。Fast-ThinkActは、教師モデルから知識蒸留(knowledge distillation)により潜在的CoTを効率的に学習し、言語的および視覚的計画能力を統合的に転移可能な操作軌道を導くように、好みに基づく最適化目標(preference-guided objective)を駆動力としている。これにより、短縮された推論と行動実行との間に効果的な接続を実現する、推論強化型ポリシー学習が可能となる。多様なエンベデッド操作および推論ベンチマークにおける広範な実験結果から、Fast-ThinkActは最先端の推論VLAと比較して最大89.3%の推論遅延削減を達成しつつ、長時間スパンの計画、少サンプル適応、失敗からの回復といった重要な能力を維持することが示された。
One-sentence Summary
The authors, affiliated with NVIDIA and multiple institutions, propose Fast-ThinkAct, a compact reasoning framework that distills latent chain-of-thought reasoning from a teacher model using a preference-guided objective, enabling efficient, high-performance embodied control with up to 89.3% lower inference latency than prior reasoning VLAs while preserving long-horizon planning, few-shot adaptation, and failure recovery across diverse manipulation tasks.
Key Contributions
- Vision-Language-Action (VLA) tasks demand robust reasoning over complex visual scenes and adaptive action execution in dynamic environments, but existing reasoning VLAs relying on lengthy explicit chain-of-thought (CoT) traces suffer from high inference latency, limiting their applicability in real-time embodied systems.
- Fast-ThinkAct introduces a compact reasoning framework that distills efficient, verbalizable latent reasoning from a teacher model using a preference-guided objective, aligning both linguistic and visual planning through trajectory-level supervision to preserve critical spatial-temporal dynamics.
- Experiments across multiple embodied manipulation and reasoning benchmarks show Fast-ThinkAct reduces inference latency by up to 89.3% compared to state-of-the-art reasoning VLAs while maintaining strong performance in long-horizon planning, few-shot adaptation, and failure recovery.
Introduction
Vision-Language-Action (VLA) models enable embodied agents to reason over complex visual scenes and execute adaptive actions, but prior reasoning-enhanced approaches rely on lengthy chain-of-thought (CoT) traces that introduce high inference latency—hindering real-time applications like robotic manipulation and autonomous driving. While supervised and reinforcement learning-based methods improve generalization, they struggle with efficiency and often sacrifice performance when compressing reasoning. The authors propose Fast-ThinkAct, a framework that distills explicit textual reasoning into compact, verbalizable latent representations using preference-guided distillation and visual trajectory alignment. This enables efficient, high-fidelity planning by encoding both linguistic and visual reasoning in continuous latents, which are then decoded into interpretable language via a verbalizer while preserving action accuracy. The result is up to 89.3% lower inference latency than state-of-the-art reasoning VLAs, with maintained capabilities in long-horizon planning, few-shot adaptation, and failure recovery.
Dataset

- The dataset comprises multiple sources for training and evaluation, including single-arm visual trajectories from MolmoAct (Lee et al., 2025) within the OXE dataset (O'Neill et al., 2024), dual-arm trajectories from the AIST dataset (Motoda et al., 2025), and QA tasks from PixMo (Deitke et al., 2024), RoboFAC (Lu et al., 2025), RoboVQA (Sermanet et al., 2024), ShareRobot (Ji et al., 2025), EgoPlan (Chen et al., 2023), and Video-R1-CoT (Feng et al., 2025).
- The single-arm subset includes approximately 1.3M 2D visual trajectories from MolmoAct, while the bimanual subset consists of around 92K dual-arm trajectories extracted from AIST. Trajectories are derived using Molmo-72B to detect gripper positions in the first frame and CoTracker3 for end-to-end tracking across video sequences.
- For training, the authors perform supervised fine-tuning on roughly 4 million samples combining visual trajectories and QA data from the above sources to build foundational embodied knowledge.
- To enhance reasoning, they conduct chain-of-thought supervised fine-tuning using 200K samples (5% of SFT data) and 165K high-quality CoT-annotated samples from Video-R1-CoT. Prompts are structured to elicit reasoning in tags and answers in tags for CoT data, while direct answers are used for non-CoT data.
- The model is trained using a mixture of these datasets, with PixMo used to preserve general visual understanding and prevent catastrophic forgetting during embodied task training.
- Evaluation is conducted on four embodied reasoning benchmarks—EgoPlan-Bench (Qiu et al., 2024), RoboVQA, OpenEQA (Majumdar et al., 2024), and RoboFAC—and three robot manipulation benchmarks: SimplerEnv (Li et al., 2024), LIBERO (Liu et al., 2023), and RoboTwin2.0 (Chen et al., 2025), with task success rate as the primary metric for manipulation tasks.
Method
The authors leverage a two-stage framework to achieve efficient reasoning and action execution in embodied tasks. The overall architecture, as illustrated in the figure below, consists of a reasoning module that generates compact visual plans and a policy module that translates these plans into executable actions. The framework begins with a textual teacher VLM, FθT, which processes the observation ot and instruction l to produce explicit reasoning chains, including a sequence of waypoints that represent the intended visual trajectory. This teacher model is trained with trajectory-level rewards to ensure grounded visual planning. 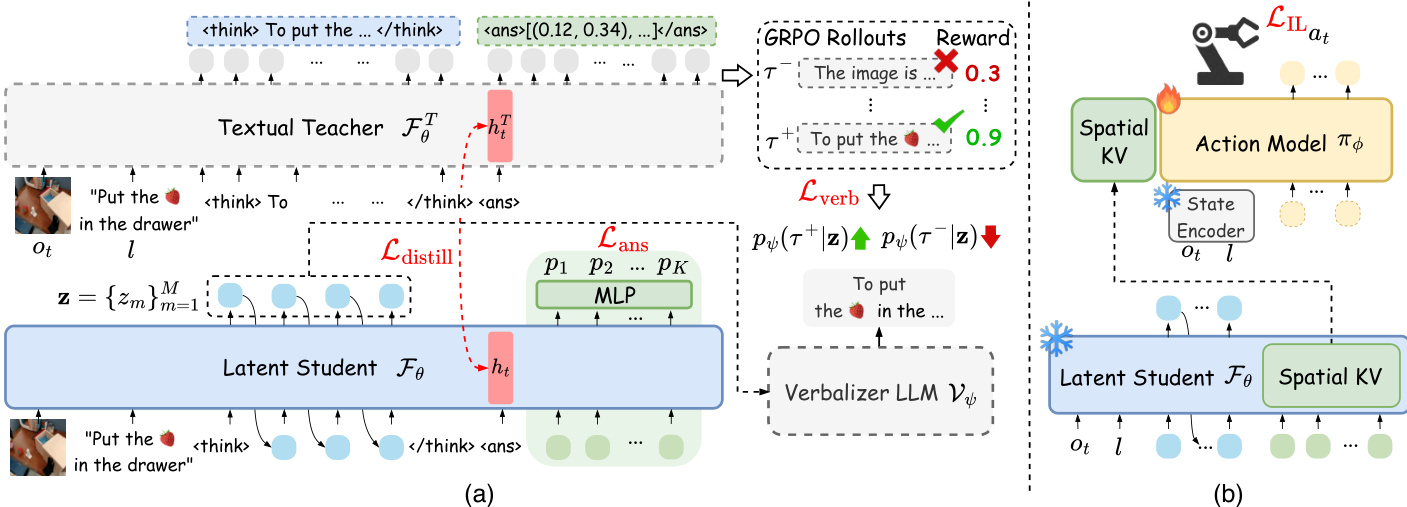
The core of the method is the latent student VLM, Fθ, which distills the teacher's reasoning into a compact latent space. This distillation is guided by a preference-based loss, Lverb, which uses a verbalizer LLM, Vψ, to decode the student's latent tokens z into text and compare them against the teacher's reasoning chains. To ensure the student captures the visual planning capability, the authors introduce action-aligned visual plan distillation, Ldistill, which minimizes the L2 distance between the hidden states of the token from the teacher and the student, thereby aligning their trajectory-level representations. To enable efficient parallel prediction of the visual trajectory, the student employs K learnable spatial tokens appended to the reasoning latent sequence. Each spatial token's output hidden state is projected to a waypoint via an MLP, and the loss Lans is computed as the L2 distance between the predicted and ground-truth waypoints. The total training objective for the student is the sum of these three components: Lstudent=Lverb+Ldistill+Lans. 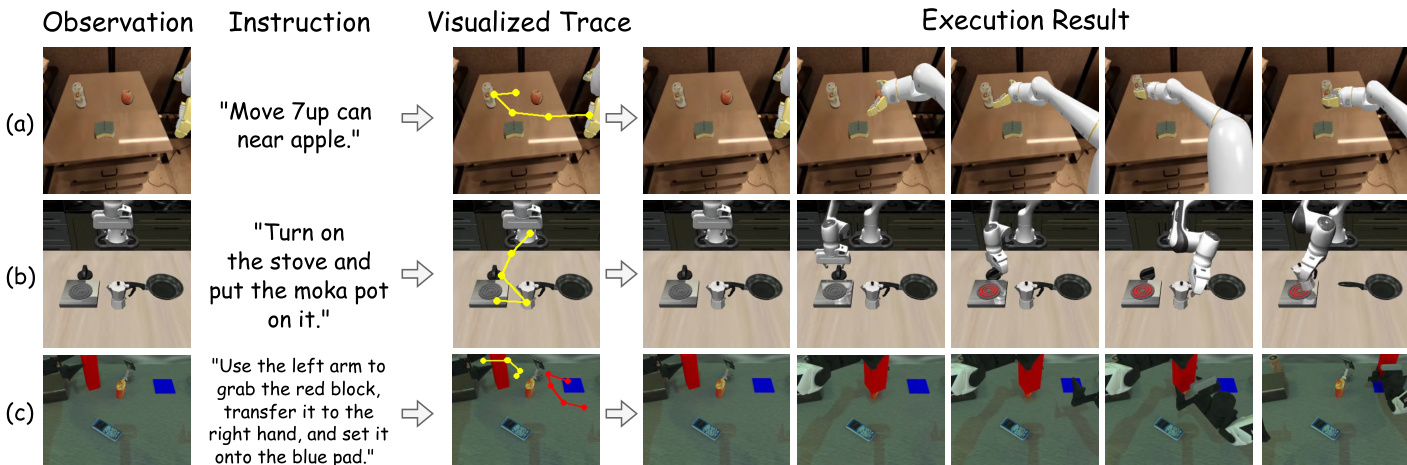
Following the student's generation of a visual plan latent ct, the framework transitions to action execution. The visual latent planning ct is extracted from the key-value cache of the spatial tokens in the student VLM and is used to condition a diffusion Transformer-based action model, πϕ. This action model is trained with an imitation learning objective, LIL, by freezing the student VLM and the state encoder while updating only the action model's parameters. The action model's cross-attention mechanism attends to both the visual planning context and the state observations, effectively bridging the high-level visual planning with low-level action generation. 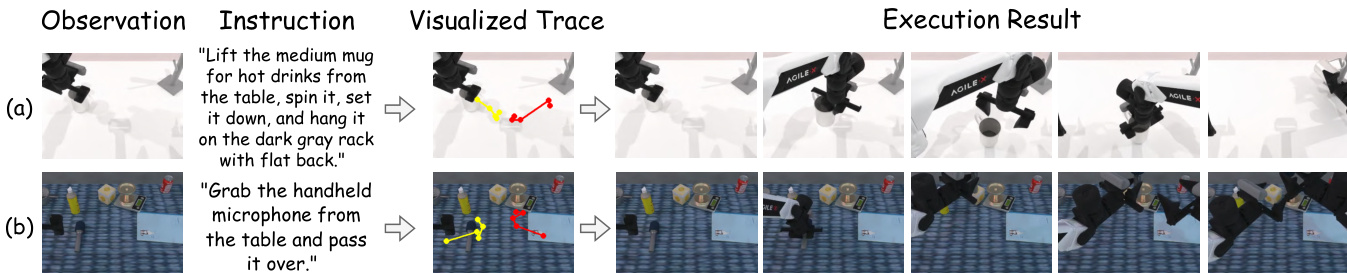
During inference, the process is streamlined. The student VLM processes the observation and instruction to generate a compact visual plan via the spatial tokens. The visual latent planning ct is then extracted and used to condition the action model, which predicts the next action at. This inference pipeline requires only the student VLM and the action model, eliminating the need for the verbalizer, which is used solely during training. The authors report that this approach achieves up to 89.3% inference latency reduction compared to state-of-the-art reasoning VLAs while maintaining strong performance across diverse embodied benchmarks. 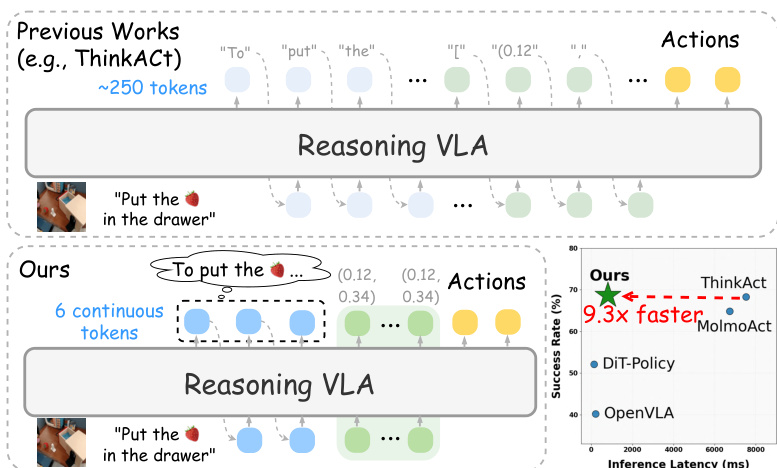
Experiment
- Evaluated on robotic manipulation benchmarks: LIBERO, SimplerEnv, and RoboTwin2.0, Fast-ThinkAct achieves state-of-the-art success rates, outperforming OpenVLA, CoT-VLA, ThinkAct, and MolmoAct, with 89.3% and 88.0% latency reduction compared to ThinkAct-7B and 7× faster inference than ThinkAct-3B.
- On RoboTwin2.0, Fast-ThinkAct achieves 9.3% and 3.6% higher success rates than RDT on easy and hard settings, and 3.3% and 1.7% higher than ThinkAct, while maintaining superior efficiency.
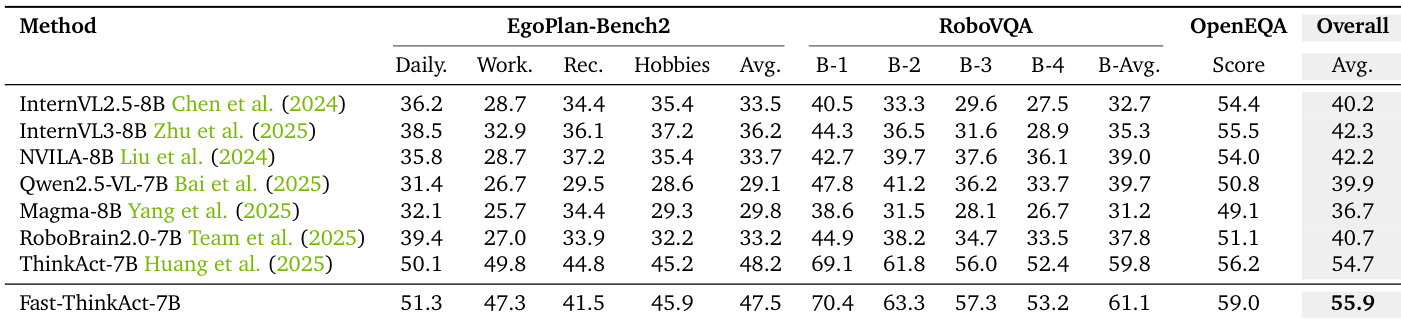
- Demonstrates strong embodied reasoning capabilities on EgoPlan-Bench2, RoboVQA, and OpenEQA, surpassing all baselines including GPT-4V and Gemini-2.5-Flash, with gains of 2.4% on EgoPlan-Bench2, 5.5 BLEU on RoboVQA, and 1.1 points on OpenEQA.
- Excels in long-horizon planning, achieving 48.8 and 16.8 average scores on long-horizon tasks in RoboTwin2.0 (easy/hard), outperforming RDT (35.0/12.3) and ThinkAct (42.8/15.3), with accurate visual trajectory predictions.
- Shows robust failure recovery on RoboFAC, improving by 10.9 points (sim) and 16.4 points (real) over RoboFAC-3B, with effective root cause analysis and corrective planning.
- Achieves strong few-shot adaptation on RoboTwin2.0 with only 10 demonstrations, significantly outperforming pi0 and ThinkAct while maintaining low reasoning latency.
- Ablation studies confirm the necessity of mathcalLtextverb and mathcalLtextdistill, with M=6 latent reasoning steps providing optimal performance.
- The compact latent reasoning design enables efficient, accurate, and interpretable reasoning, with verbalized outputs that are more concise and relevant than teacher-generated text.
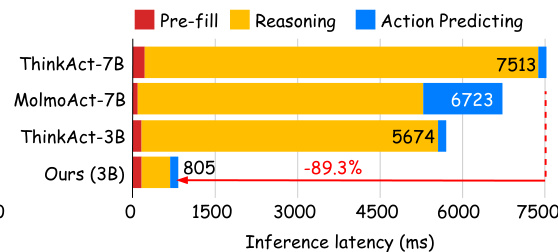
Results show that Fast-ThinkAct achieves significantly lower inference latency compared to ThinkAct-7B and MolmoAct-7B, with a latency of 805 ms, which is 89.3% lower than ThinkAct-7B. The authors use this reduction to demonstrate substantial efficiency gains while maintaining competitive performance.
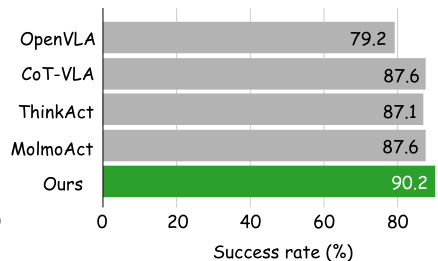
Results show that Fast-ThinkAct achieves a success rate of 90.2%, outperforming OpenVLA, CoT-VLA, ThinkAct, and MolmoAct on the evaluated robotic manipulation tasks. The authors use this result to demonstrate that their method achieves higher performance than existing reasoning-based vision-language action models.
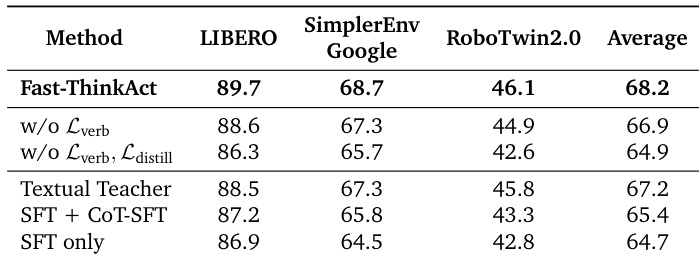
Results show that Fast-ThinkAct achieves the highest success rates across all evaluated benchmarks, with an average score of 68.2, outperforming all ablated variants and baseline methods. The ablation study indicates that both the verbalization loss and distillation loss are critical for maintaining high performance, as their removal leads to significant drops in success rates.
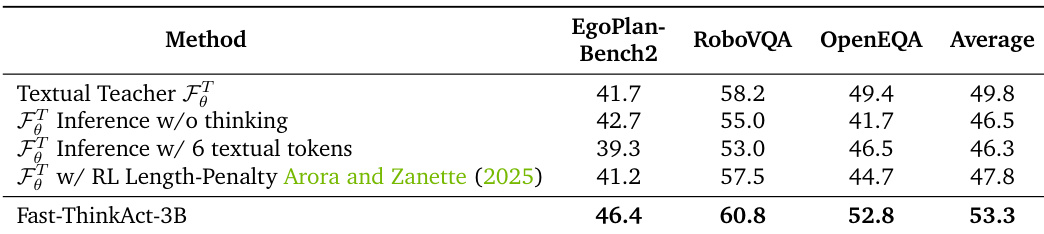
Results show that Fast-ThinkAct-3B achieves higher performance than the textual teacher and its variants across all three embodied reasoning benchmarks, with the highest scores on RoboVQA and OpenEQA, demonstrating that compact latent reasoning outperforms constrained textual reasoning methods.
Results show that Fast-ThinkAct-7B achieves the highest overall score of 55.9 on the embodied reasoning benchmarks, outperforming all compared methods including proprietary models like GPT-4V and Gemini-2.5-Flash. It significantly surpasses the runner-up ThinkAct-7B by 1.2 points on the overall score, demonstrating superior reasoning capabilities across EgoPlan-Bench2, RoboVQA, and OpenEQA.