Command Palette
Search for a command to run...
RubricHub:自動的コアス・トゥ・ファイン生成による包括的かつ高判別力なルーブリックデータセット
RubricHub:自動的コアス・トゥ・ファイン生成による包括的かつ高判別力なルーブリックデータセット
Sunzhu Li Jiale Zhao Miteto Wei Huimin Ren Yang Zhou Jingwen Yang Shunyu Liu Kaike Zhang Wei Chen
概要
検証可能な報酬を用いた強化学習(Reinforcement Learning with Verifiable Rewards; RLVR)は、数学など推論が求められる分野において、顕著な進展をもたらしてきました。しかし、開かれた生成タスクの最適化は、真の正解(ground truth)が存在しないため依然として困難です。ルーブリックベースの評価は検証のための構造化された代替指標を提供しますが、従来の手法はスケーラビリティのボトルネックと粗い評価基準に起因し、教師信号の上限(supervision ceiling effect)を引き起こしています。これを解決するために、本研究では自動化された「粗い段階から細かい段階へ」のルーブリック生成フレームワークを提案します。本手法は、原則に基づく合成、複数モデルの統合、難易度の進化を統合することで、微細な差異を捉えられる包括的かつ高識別性の評価基準を生成します。このフレームワークを基盤として、大規模(約11万件)かつ多分野にわたるデータセット「RubricHub」を構築しました。その有用性は、ルーブリックベースの拒否採択サンプリング微調整(RuFT)と強化学習(RuRL)を含む二段階の後学習パイプラインを用いて検証されました。実験結果から、RubricHubが顕著な性能向上をもたらすことが示されました。後学習を施したQwen3-14Bは、HealthBenchにおいて69.3という最先端(SOTA)の成績を達成し、GPT-5を含むプロプライエタリな最先端モデルを上回りました。コードとデータは近日中に公開予定です。
One-sentence Summary
The authors from Li Auto Inc., The Chinese University of Hong Kong, Shenzhen, Zhejiang University, and Nanyang Technological University propose RubricHub, a large-scale, multi-domain dataset generated via a novel coarse-to-fine rubric framework that integrates principle-guided synthesis and difficulty evolution, enabling fine-grained, scalable evaluation for open-ended reasoning tasks; this approach drives state-of-the-art performance in post-training with RuFT and RuRL, achieving SOTA results on HealthBench (69.3) with Qwen3-14B, outperforming proprietary models like GPT-5.
Key Contributions
- Existing rubric-based evaluation methods for open-ended generation suffer from scalability issues and coarse criteria, leading to a supervision ceiling that limits model performance improvements.
- The authors propose an automated Coarse-to-Fine Rubric Generation framework that combines principle-guided synthesis, multi-model aggregation, and difficulty evolution to produce fine-grained, highly discriminative evaluation criteria.
- The resulting RubricHub dataset (≈110k entries across multiple domains) enables a two-stage post-training pipeline (RuFT and RuRL), leading to Qwen3-14B achieving state-of-the-art results on HealthBench (69.3), surpassing even proprietary models like GPT-5.
Introduction
The authors address the challenge of aligning large language models (LLMs) in open-ended, non-verifiable domains—where ground truth is absent—by advancing rubric-based evaluation as a scalable proxy for supervision. While reinforcement learning with verifiable rewards (RLVR) excels in math and coding, it fails in real-world, subjective tasks. Existing rubric methods are limited by manual effort, narrow domain coverage, and coarse, low-discriminative criteria that cannot differentiate high-quality responses, creating a supervision ceiling. To overcome this, the authors propose an automated Coarse-to-Fine Rubric Generation framework that combines principle-guided synthesis, multi-model aggregation, and difficulty evolution to produce fine-grained, highly discriminative criteria. This enables the creation of RubricHub, a large-scale (~110k), multi-domain dataset with rich, nuanced evaluation criteria. Validated through a two-stage post-training pipeline—Rubric-based Rejection Sampling Fine-Tuning (RuFT) and Reinforcement Learning (RuRL)—the framework enables a Qwen3-14B model to achieve state-of-the-art performance on HealthBench (69.3), surpassing even proprietary models like GPT-5.
Dataset

- The authors constructed RubricHub by aggregating queries from five domains: Science (RaR-science, ResearchQA, MegaScience), Instruction Following (IFTRAIN), Writing (LongWriter, LongWriter-Zero, DeepWriting-20K, LongAlign), Medical (II-medical), and Chat (WildChat-1M, LMSys-1M).
- After removing samples with abnormal lengths or formatting issues, the final dataset comprises approximately 110k question-rubric pairs.
- Domain distribution shows Medical and Science each account for 27.1% of the dataset, followed by Instruction Following (20.9%) and Writing (15.9%).
- For complex domains like Writing and Medical, the rubrics include over 30 fine-grained evaluation criteria on average, enabling detailed and rigorous assessment.
- The dataset exhibits high score density and strong discriminative power across model scales, as shown in Figure 4, with top models like Qwen3-235B achieving an average score of only ~0.6, indicating significant room for improvement.
- The authors use RubricHub to train and evaluate their model, leveraging its diverse domain coverage and fine-grained criteria to ensure robust performance assessment.
- No explicit cropping strategy is described, but filtering for length and formatting ensures data quality.
- Metadata is implicitly constructed through domain labeling and rubric structure, supporting downstream analysis and model training with clear evaluation criteria.
Method
The authors present a coarse-to-fine rubric generation framework designed to synthesize high-quality, discriminative evaluation criteria for model assessment. The overall pipeline, illustrated in Figure 2, operates in three distinct phases: response-grounded and principle-guided generation, multi-model aggregation, and difficulty evolution. This framework is initialized with a curated corpus of approximately 110,000 open-ended queries spanning multiple domains, which serves as the foundation for rubric synthesis.

The first phase, response-grounded and principle-guided generation, aims to prevent rubric drift by anchoring criteria to concrete context. The process conditions the large language model (LLM) generator M on both a query q and a reference response oi, ensuring the generated criteria are relevant to the specific output. This is further constrained by a set of meta-principles Pmeta that enforce standards for consistency, structure, clarity, and evaluability. Using a specific generation prompt Pgen, a candidate rubric Rcand(i) is synthesized, which is explicitly grounded in the response and guided by the meta-principles.
The second phase, multi-model aggregation, addresses the inherent bias of single-model generation. To achieve comprehensive and objective standards, the framework synthesizes parallel candidate rubrics from multiple heterogeneous frontier models, forming a unified pool Rcand. This pool is then distilled into a compact base rubric Rbase through an aggregation prompt Pagg, which consolidates redundant items and resolves conflicts, resulting in a robust standard that mitigates single-source bias.
The third phase, difficulty evolution, enhances the rubric's discriminability to distinguish between high-performing responses. This is achieved by identifying a pair of high-quality reference responses Aref and applying an augmentation prompt Paug to analyze them. This analysis extracts discriminative nuances that elevate a response from excellent to exceptional, forming a set of additive criteria Radd. The final rubric Rfinal is obtained by merging the base and evolved criteria, combining comprehensive coverage with rigorous discriminability.
The generated rubrics are then utilized in two post-training paradigms. In rubric-based rejection sampling fine-tuning, a pool of candidate responses is generated for each query-rubric pair. Each response is scored based on the rubric's weighted criteria, and responses below a threshold τ are rejected, with the highest-scoring response selected for supervised fine-tuning. In rubric-based reinforcement learning, the rubric defines a reward signal. For each criterion, a unified grader G produces a binary score, with rule-based systems handling verifiable criteria and LLM-based evaluators handling semantic ones. The final dense reward r(q,o) is calculated as the weight-normalized sum of these binary scores, providing a structured signal for policy optimization.
Experiment
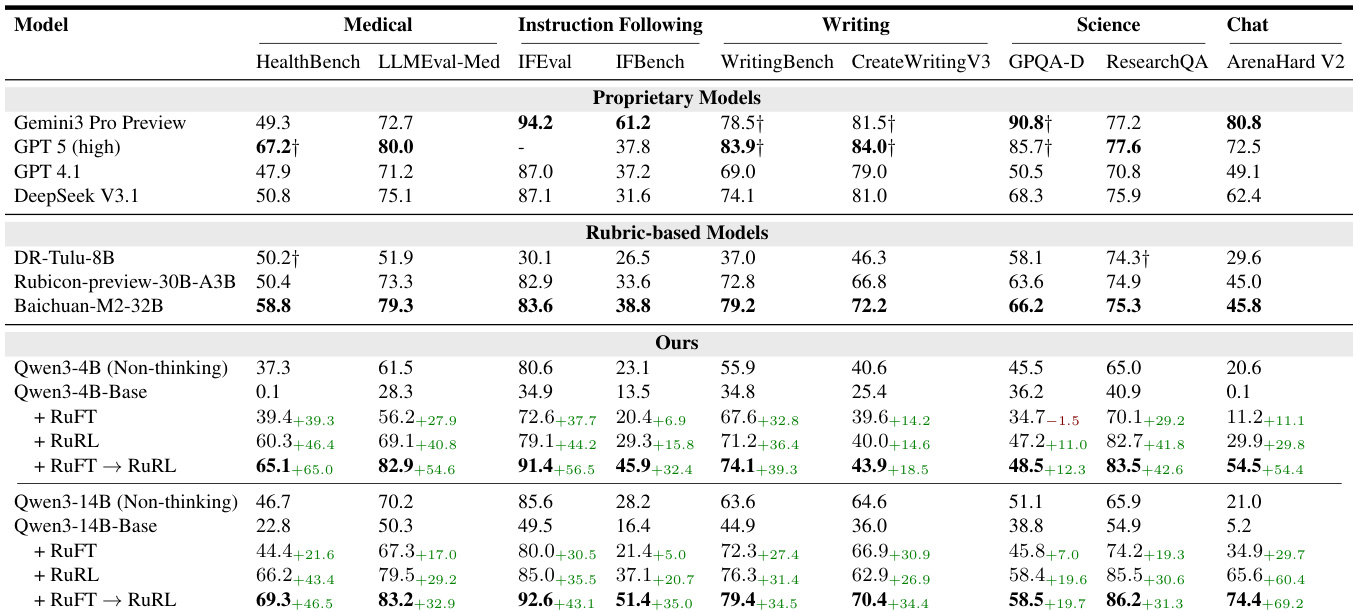
- Main experiments validate a two-stage post-training framework (RuFT followed by RuRL) on Qwen3-4B and Qwen3-14B base models across five domains: Science, Instruction-Following, Writing, Medical, and Chat.
- On Arena-Hard-V2, Qwen3-14B achieved a score of 74.4, a significant improvement from the base model’s 5.2, demonstrating strong gains in chat and multi-turn engagement.
- In the medical domain, the model achieved SOTA performance with a score of 69.3 on HealthBench, outperforming GPT-5 (67.2) and surpassing larger baselines like Baichuan-M2-32B in four out of five domains.
- The RuFT→RuRL pipeline consistently outperformed base, RuFT, and RuRL stages alone, with the largest gains in general chat and medical reasoning.
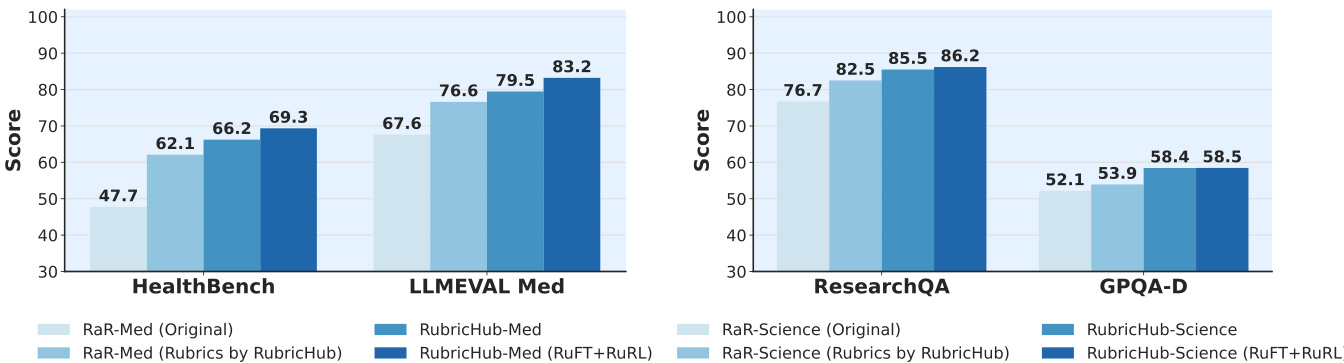
- Rubric-based rejection sampling and the Coarse-to-Fine rubric generation pipeline significantly improved performance: HealthBench score increased from 47.7 (original RaR) to 62.1 (RubricHub), and further to 69.3 with full pipeline.
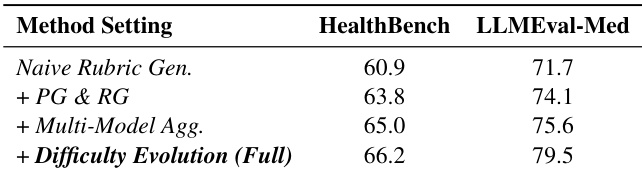
- Ablation studies confirmed the additive value of each component: principle-guided and response-grounded constraints, multi-model aggregation, and difficulty evolution.
- Increasing candidate samples in rejection sampling raised training set scores from 63.45 to 79.51 and improved HealthBench performance from 43.61 to 48.81.
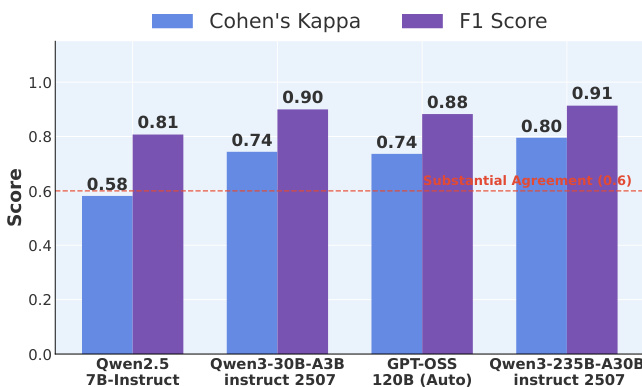
- Sensitivity analysis showed positive-only rubric criteria outperformed those with negative penalties, and gpt-oss-120B was selected as the optimal grader balancing accuracy and speed.
- Human-LLM agreement analysis revealed that LLMs above 30B scale achieve substantial agreement (F1: 0.90, κ: 0.74), with performance saturating beyond 30B.
- Training dynamics showed steady, balanced improvement across rubric dimensions, indicating holistic capability enhancement without over-optimization.
Results show that the agreement between human and LLM evaluations improves with model scale, with the Qwen3-235B-A30B instruct 2507 model achieving the highest inter-rater reliability (Cohen's Kappa: 0.91) and F1 Score (0.91), surpassing the substantial agreement threshold.
The authors use a multi-stage alignment strategy, RuFT followed by RuRL, to improve model performance across medical and science domains. Results show that their method achieves significant gains over baseline approaches, with the RuFT→RuRL pipeline reaching 83.2 on LLMEval-Med and 86.2 on ResearchQA, outperforming both original and rubric-enhanced baselines.
The authors conduct an ablation study on the Coarse-to-Fine Rubric Generation Pipeline, showing that each added component improves performance. Starting from Naive Rubric Gen., incorporating Principle-Guided and Response-Grounded constraints (+ PG & RG) increases HealthBench and LLMEval-Med scores, with further gains from Multi-Model Aggregation and Difficulty Evolution, which achieves the highest score of 79.5 on LLMEval-Med.
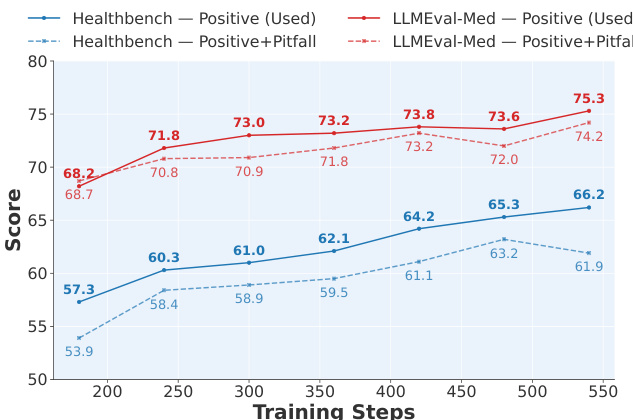
The authors use a sensitivity analysis to evaluate the impact of rubric criteria composition on model performance, comparing training with only positively weighted criteria against a combination of positive and negative penalties. Results show that the positive-only formulation consistently outperforms the positive-plus-pitfall approach across both HealthBench and LLMEval-Med, achieving higher scores and indicating that negative penalties hinder optimization due to the grader's low accuracy on negative criteria.
The authors use a multi-stage post-training approach, RuFT and RuRL, to align Qwen3 models across five domains, with results showing consistent performance improvements from Base to RuFT to RuRL. The Qwen3-14B model achieves state-of-the-art results in the medical domain with a HealthBench score of 69.3, outperforming even GPT-5, and demonstrates strong competitive performance across other benchmarks, particularly in chat and instruction-following tasks.