Command Palette
Search for a command to run...
アルゴリズムコード最適化のための制御された自己進化
アルゴリズムコード最適化のための制御された自己進化
概要
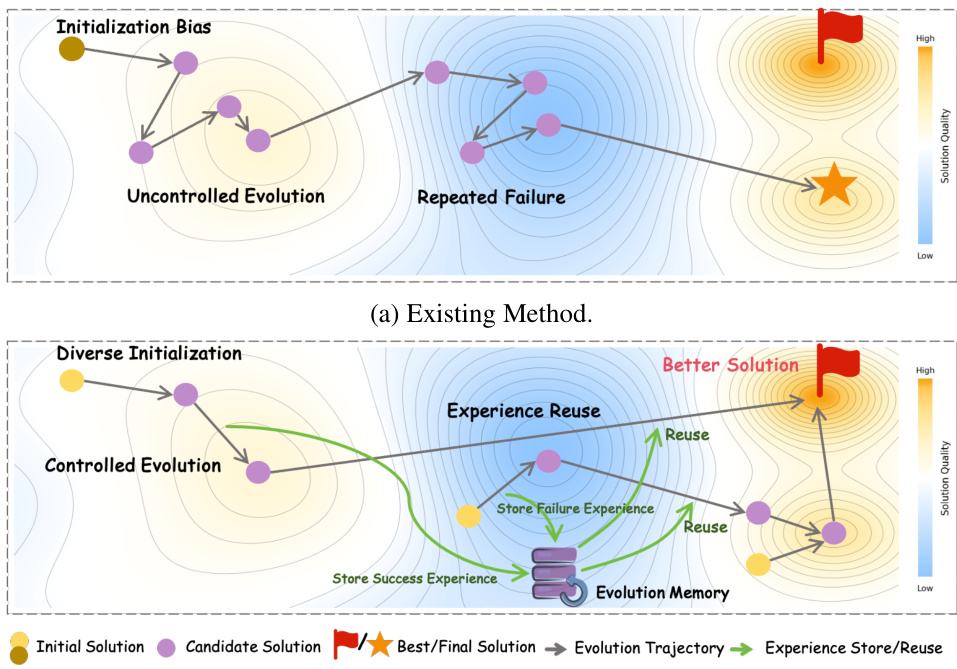
自己進化手法は、反復的な「生成-検証-改善」サイクルを通じてコード生成を向上させるが、従来のアプローチは探索効率が低く、限られたリソース内では優れた複雑性を持つ解決策を発見できていない。この非効率性の原因は、初期化バイアスにより進化が劣った解空間に閉じ込められること、フィードバックを受けることなく制御されない確率的操作が行われること、およびタスク間・タスク内での経験の活用が不十分であることに起因する。これらの課題を克服するため、本研究では制御された自己進化(Controlled Self-Evolution; CSE)を提案する。CSEは以下の3つの主要な構成要素からなる。まず、多様な計画的初期化(Diversified Planning Initialization)により、構造的に異なるアルゴリズム戦略を生成し、解空間の広範なカバーを実現する。次に、遺伝的進化(Genetic Evolution)により、確率的操作をフィードバックに基づく制御されたメカニズムに置き換え、ターゲット指向の突然変異と構成的交叉を可能にする。さらに、階層的進化記憶(Hierarchical Evolution Memory)により、タスク間およびタスク内レベルで成功した経験と失敗した経験の両方を蓄積・活用する。EffiBench-Xを用いた実験により、CSEが様々なLLMバックボーンにおいて、すべてのベースラインを一貫して上回ることを示した。さらに、CSEは初期世代から高い効率性を発揮し、進化の全過程にわたって継続的な改善を実現している。コードは公開されており、https://github.com/QuantaAlpha/EvoControl にて入手可能である。
One-sentence Summary
The authors from NJU, PKU, Midea-AIRC, ECNU, SYSU, RUC, and QuantaAlpha propose Controlled Self-Evolution (CSE), a method that enhances code generation via diversified initialization, feedback-guided genetic operations, and hierarchical memory for experience reuse, enabling efficient exploration and sustained improvement across LLM backbones on EffiBench-X.
Key Contributions
- Existing self-evolution methods for code generation suffer from low exploration efficiency due to initialization bias, uncontrolled stochastic operations, and poor reuse of evolutionary experience, limiting their ability to discover high-quality, complex solutions within constrained computational budgets.
- The proposed Controlled Self-Evolution (CSE) framework introduces three key innovations: Diversified Planning Initialization for broad solution space coverage, Genetic Evolution with feedback-guided mutation and compositional crossover for targeted refinement, and Hierarchical Evolution Memory to store and reuse both task-specific and cross-task experiences.
- On the EffiBench-X benchmark, CSE consistently outperforms all baselines across multiple LLM backbones, achieving higher efficiency from early generations and demonstrating sustained improvement throughout the evolution process.
Introduction
The authors address the challenge of generating high-efficiency algorithmic code within strict computational budgets, a critical need in real-world LLM applications where latency and cost are constrained. Prior self-evolution methods, while effective at iterative refinement through generate-verify-refine cycles, suffer from low exploration efficiency due to initialization bias, unguided stochastic operations, and poor reuse of evolutionary experience across tasks. These limitations hinder their ability to discover optimal solutions with superior time and space complexity. To overcome this, the authors propose Controlled Self-Evolution (CSE), a framework featuring three core innovations: Diversified Planning Initialization, which generates structurally varied starting strategies to avoid poor solution regions; Genetic Evolution, which replaces random mutations with feedback-guided, targeted refinement and compositional crossover; and Hierarchical Evolution Memory, which captures both task-specific and cross-task optimization patterns for reuse. Experiments on EffiBench-X show CSE consistently outperforms baselines across multiple LLM backbones, achieving faster convergence and sustained improvement, demonstrating its effectiveness in balancing efficiency and solution quality.
Method
The authors leverage a three-component framework for controlled self-evolution in code optimization, designed to address the inefficiencies of unguided exploration in existing methods. The overall architecture, as illustrated in the system diagram, consists of a planning phase that generates an initial population, an evolutionary loop that iteratively refines solutions, and a memory system that stores and reuses experiences to guide future search.
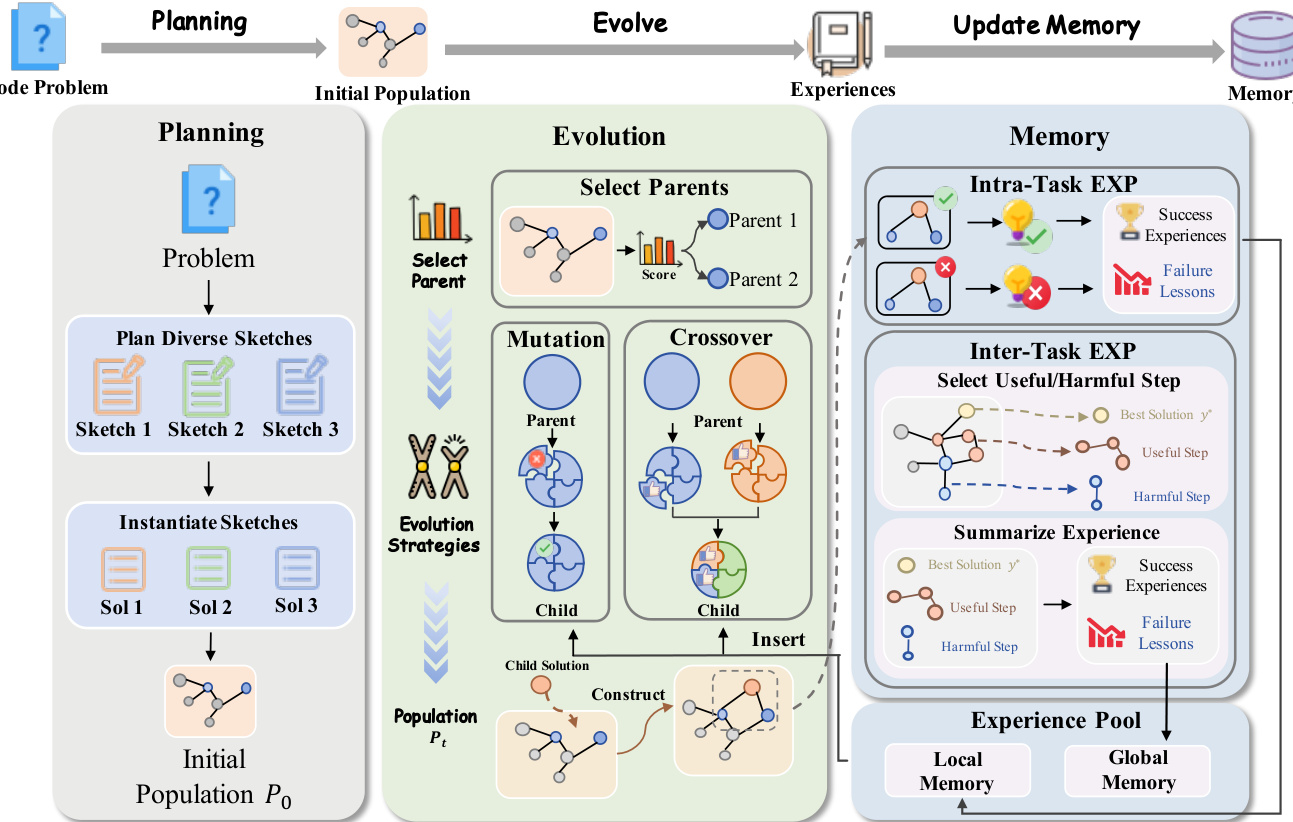
The process begins with diversified planning initialization, which aims to establish a broad and high-quality starting point for evolution. This stage employs a large language model to generate a set of distinct solution sketches, each representing a fundamentally different algorithmic strategy. These sketches are then instantiated into concrete code implementations to form the initial population. This approach ensures that the search space is explored from multiple promising starting points, mitigating the risk of premature convergence that can occur with random initialization.
The core of the method is the genetic evolution process, which operates on the initial population. At each iteration, parent solutions are selected based on a probability distribution proportional to their reward, a mechanism that allows for the retention of potentially useful low-reward solutions. The evolution is guided by two controlled strategies: controlled mutation and compositional crossover. Controlled mutation involves the model identifying a specific faulty component within a solution and regenerating it while preserving the rest of the code, enabling targeted improvements. Compositional crossover, in contrast, recombines functional components from different parent solutions to create offspring that inherit complementary strengths, such as combining a time-efficient algorithm with a robust error-handling module.
To enhance the efficiency of this process, the framework incorporates a hierarchical evolution memory system. This system maintains two levels of memory: local and global. The local memory captures intra-task experiences by storing success insights and failure lessons from each evolutionary step. These experiences are distilled and compressed to prevent information overload and are injected into the prompt context of subsequent steps to guide the model's search. The global memory, stored in a vector database, accumulates task-level experiences from previous problems. When the model encounters a new challenge, it generates targeted queries to retrieve relevant past experiences from the global memory, enabling it to leverage knowledge from similar tasks and avoid repeating past mistakes. This bidirectional guidance from both recent and historical experiences allows the model to navigate the solution space more effectively.
Experiment
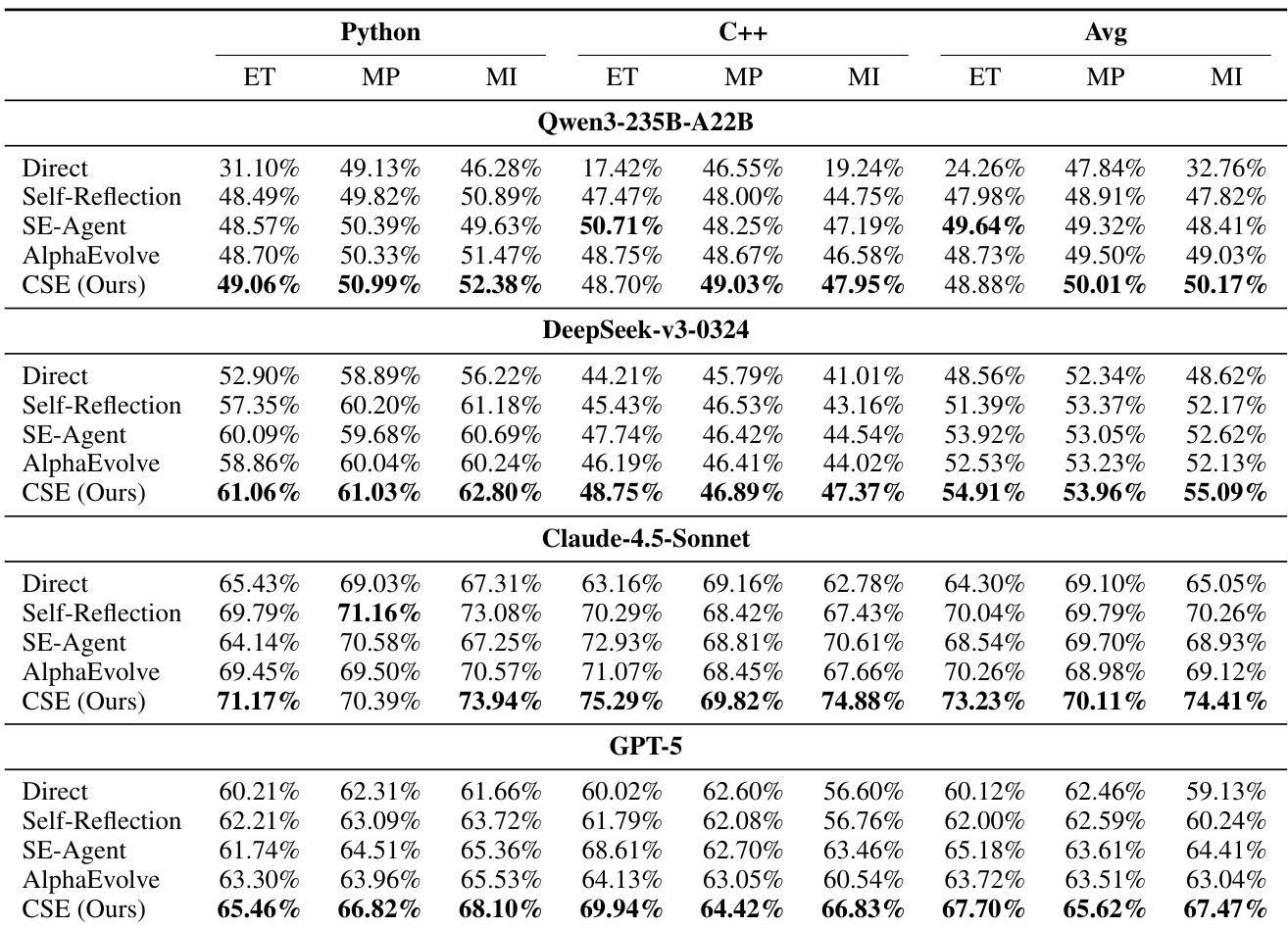
- CSE is evaluated on EffiBench-X, a benchmark of 623 algorithmic problems across Python and C++, using normalized efficiency metrics: Execution-Time ratio (ET), Memory-Peak ratio (MP), and Memory-Integral ratio (MI), with higher values indicating better performance.
- CSE outperforms four baselines—Direct, Self-Reflection, SE-Agent, and AlphaEvolve—across all three metrics on both languages, achieving the highest MI, ET, and MP scores, with particularly strong gains in memory efficiency.
- On EffiBench-X, CSE achieves an average MI of 142.3% (Python) and 138.7% (C++), surpassing the best baseline (AlphaEvolve) by over 20 percentage points, demonstrating superior exploration efficiency and solution quality.
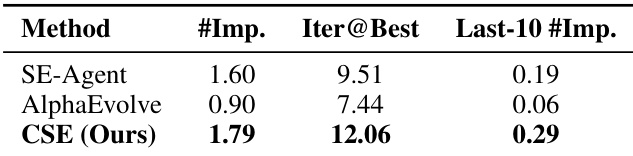
- Ablation studies show that all components—diversified planning, genetic evolution, and hierarchical memory—are essential; removing any leads to significant performance drops, with memory having the largest impact.
- Hierarchical memory provides the greatest benefit when combined with both planning and evolution, yielding a ΔMI of +5.02, indicating synergistic improvement rather than additive gains.
- CSE exhibits more frequent and sustained improvements over generations, with 1.79 improvement events per run and 0.29 in the final 10 generations, outperforming baselines that plateau early.
- Case studies confirm CSE’s ability to discover high-efficiency solutions through diverse initialization, controlled structural edits, and memory-guided exploration, resulting in final solutions that differ significantly from human references yet achieve better efficiency.
The authors use a controlled ablation study to evaluate the contribution of each component in CSE. Results show that removing any of the three components—planning, evolution, or memory—leads to significant performance drops across all metrics, with memory having the largest impact. The full CSE model achieves the highest scores on ET, MP, and MI, demonstrating that the synergistic interaction of all components is essential for optimal efficiency.
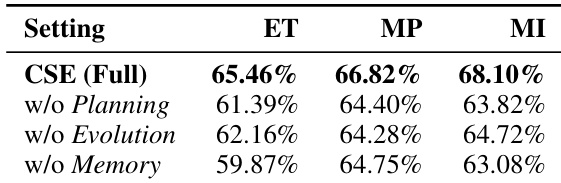
The authors use a case study to illustrate the evolution dynamics of CSE, showing that the method achieves significant early improvements through diversified initialization and controlled mutation, followed by sustained progress via compositional crossover and hierarchical memory. Results show that CSE rapidly reduces the memory-time integral, reaching a final value of 93.913 after 25 generations, with major breakthroughs at iterations 5 and 22, demonstrating effective feedback-guided exploration and structural refinement.
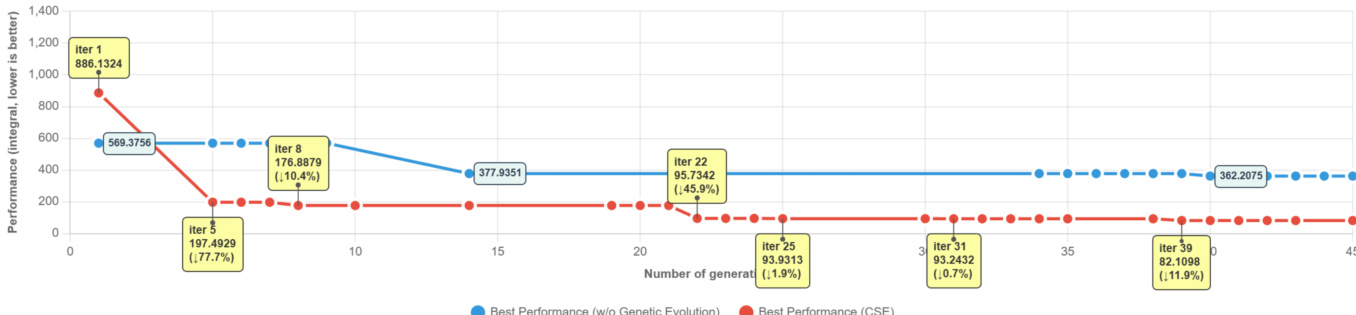
The authors use a case study to illustrate the evolution dynamics of CSE on a specific problem, showing that the method achieves significant early improvements through diversified initialization and controlled mutation, followed by sustained progress via compositional crossover and hierarchical memory. Results show that CSE consistently reduces the memory-time integral across generations, with major breakthroughs occurring at key iterations, ultimately reaching a much lower final performance than the baseline that lacks memory, demonstrating the effectiveness of memory-guided exploration.
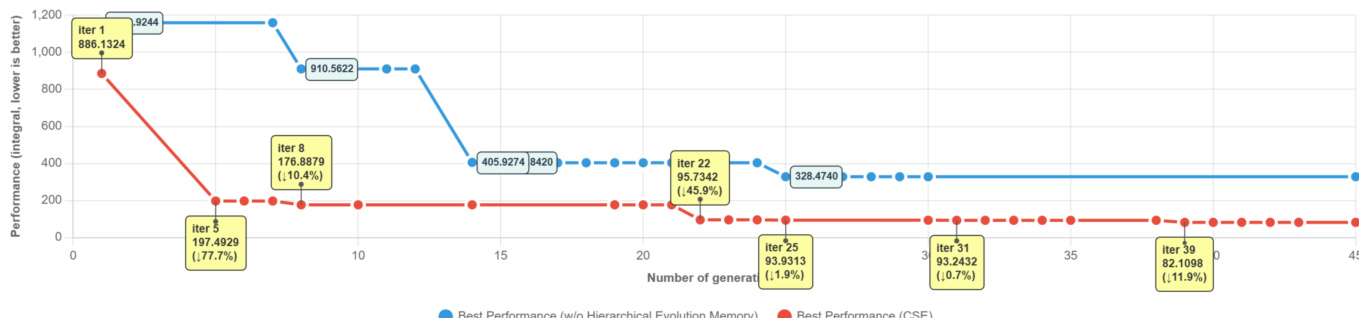
The authors use a fine-grained analysis of evolution dynamics to compare CSE with baselines, showing that CSE achieves more frequent improvements and stronger late-stage progress. Results show CSE makes 1.79 improvements on average, finds the best solution later in the budget, and sustains more progress in the final 10 generations compared to SE-Agent and AlphaEvolve.
The authors use a benchmark of 623 algorithmic problems across Python and C++ to evaluate code efficiency, measuring execution time, peak memory, and memory integral ratios relative to human solutions. Results show that CSE consistently outperforms all baselines across both languages and models, achieving the highest scores in all three metrics, with particularly strong gains in memory integral, demonstrating its effectiveness in discovering efficient solutions within limited exploration budgets.