HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
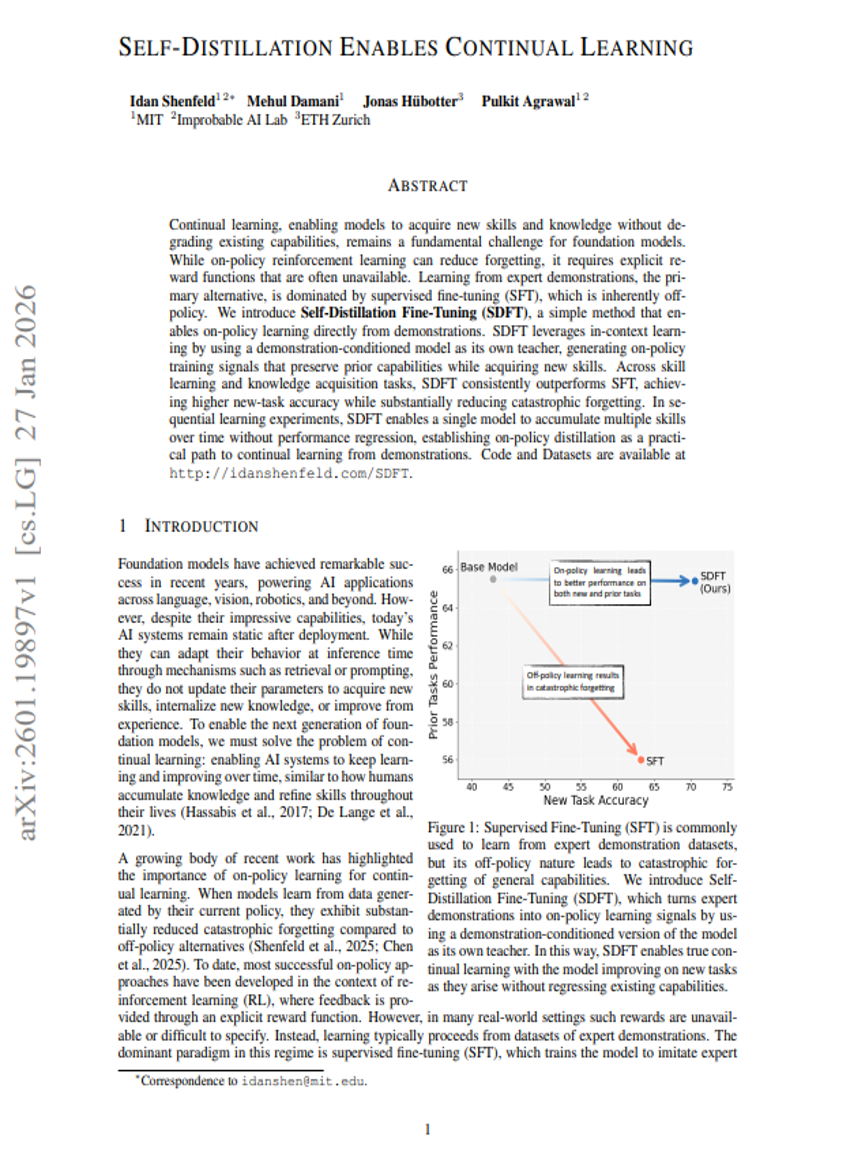
自己蒸留による継続的学習の実現

実行を基盤とする自動AI研究
















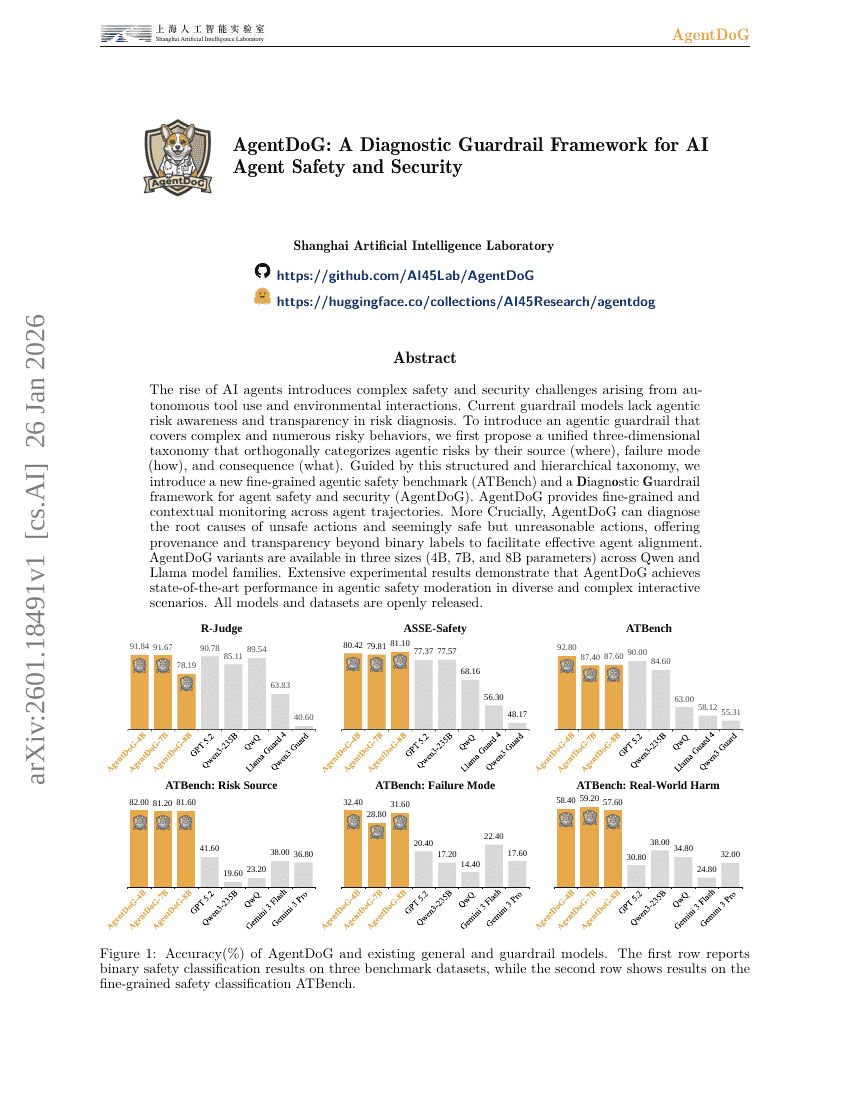
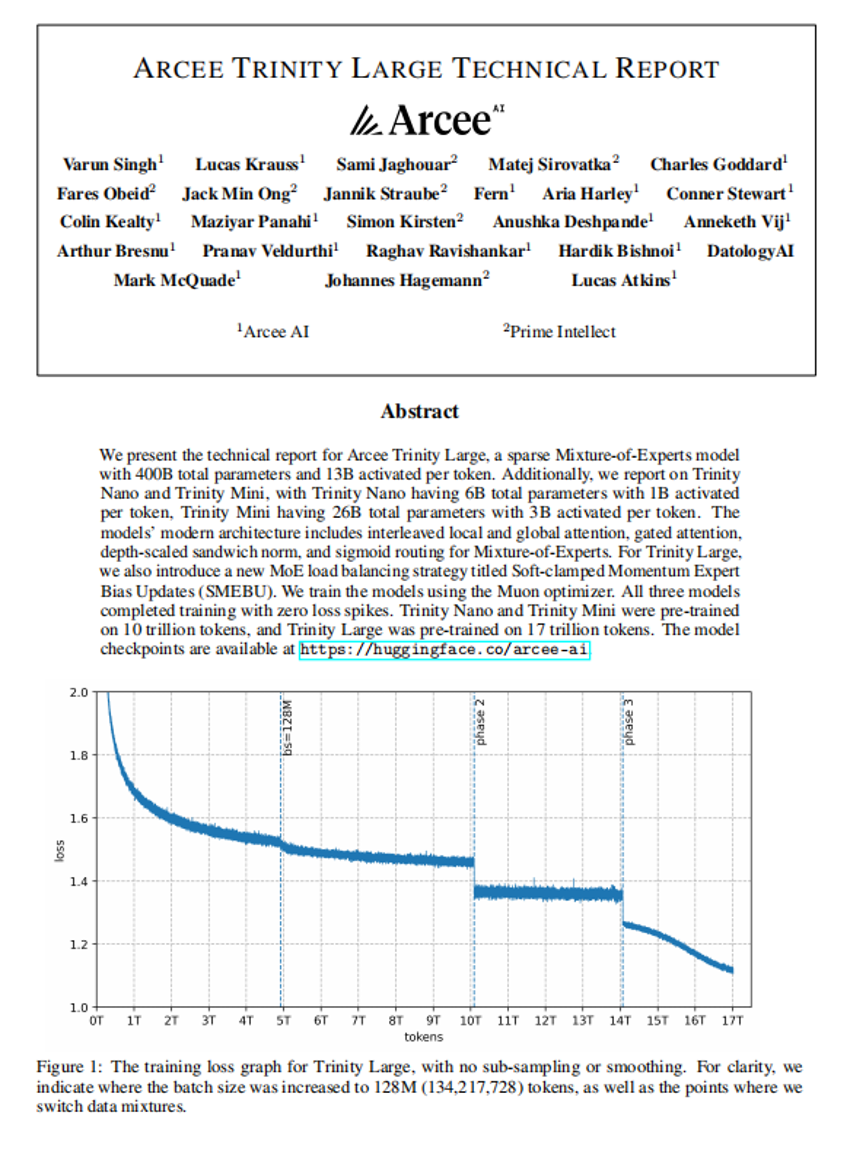
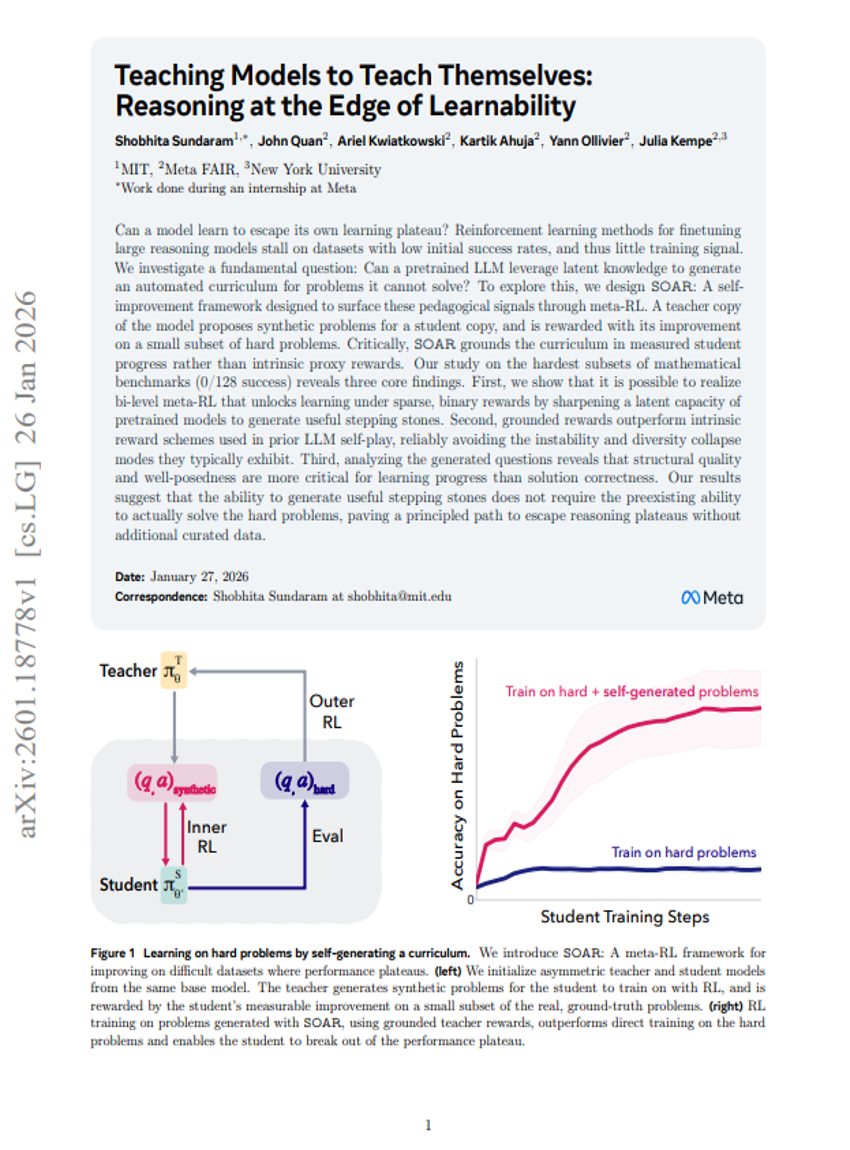


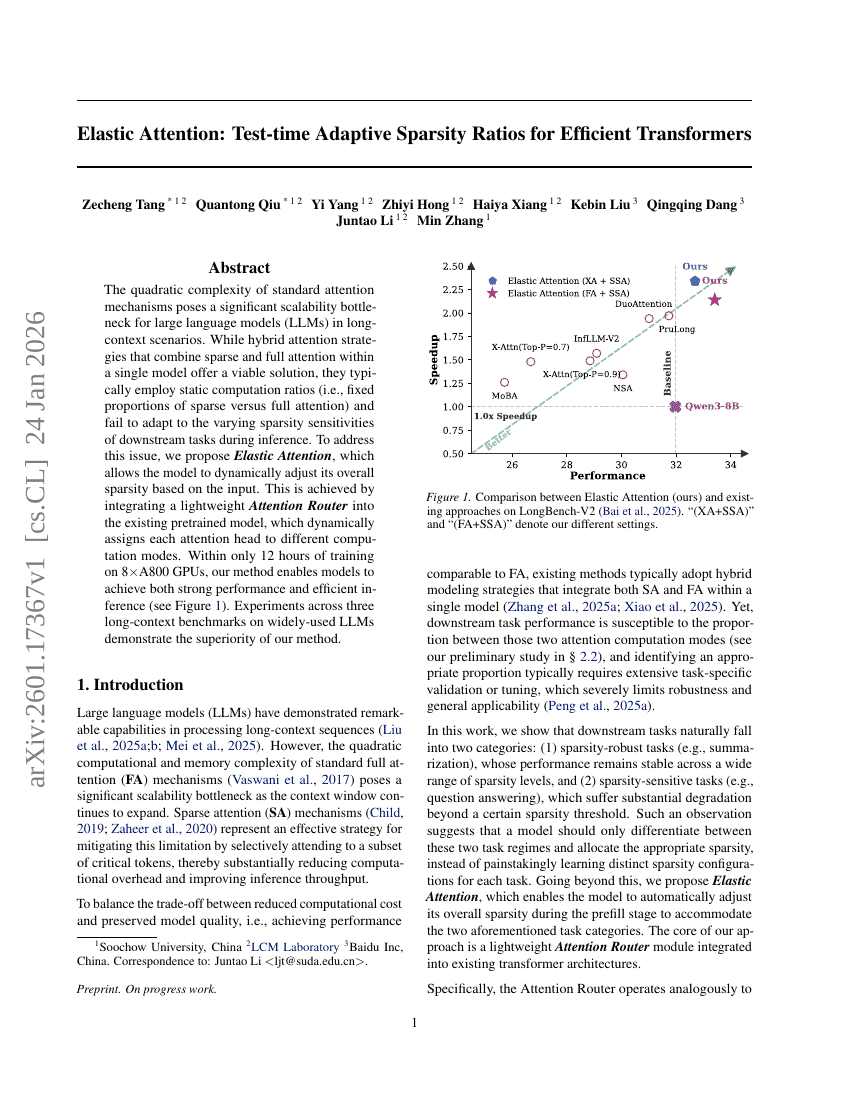




自己蒸留による継続的学習の実現
実行を基盤とする自動AI研究
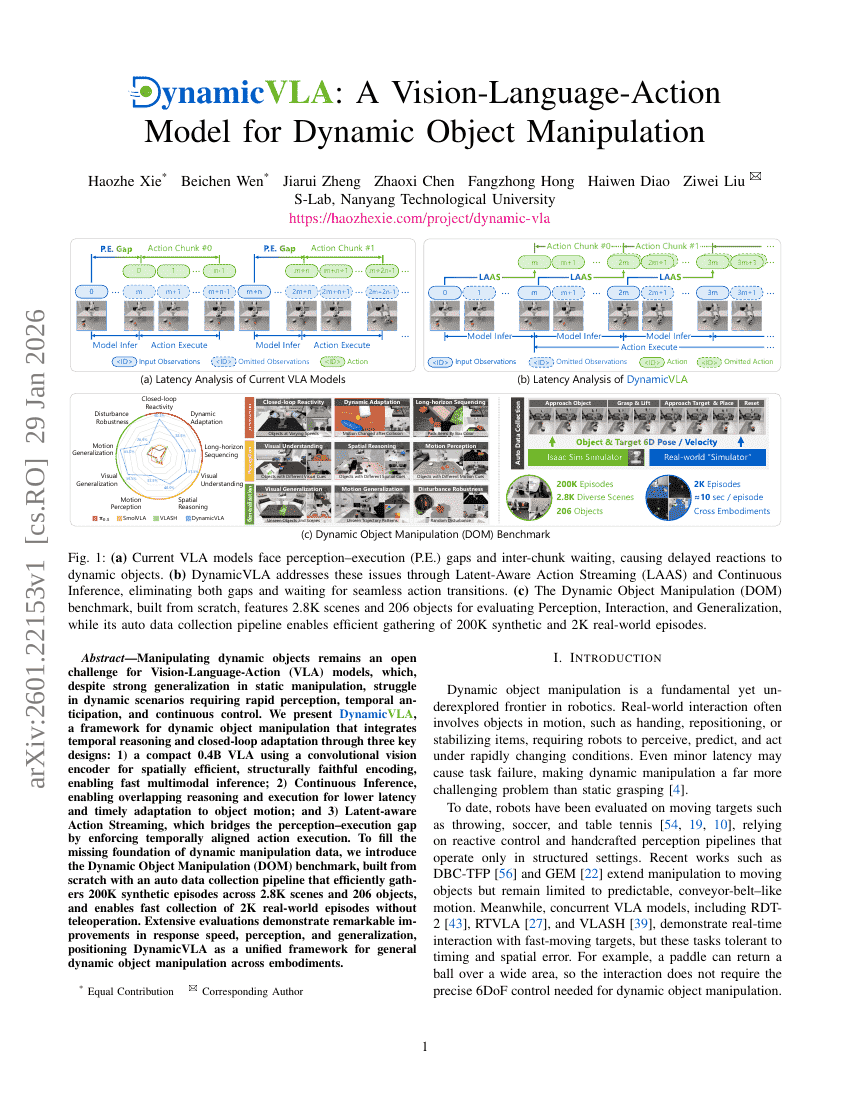
DynamicVLA:動的物体操作を実現する視覚言語行動モデル
MMFineReason:オープンデータ中心主義的手法によるマルチモーダル推論ギャップの解消
OCRVerse:エンドツーエンド視覚言語モデルにおける包括的なOCRへの道標
埋め込みのスケーリングは、言語モデルにおけるエキスパートのスケーリングを上回る
Idea2Story:研究コンセプトを完全な科学的物語に変換する自動化パイプライン
すべてのものがその適切な場所にある:テキストから画像モデルの空間的知能をベンチマークする
Qwen3-ASR 技術報告
インサイトエージェント:データインサイトを実現するLLMベースのマルチエージェントシステム
ピクセルレベルのVLM Perception を実現するためのシンプルなポイント予測
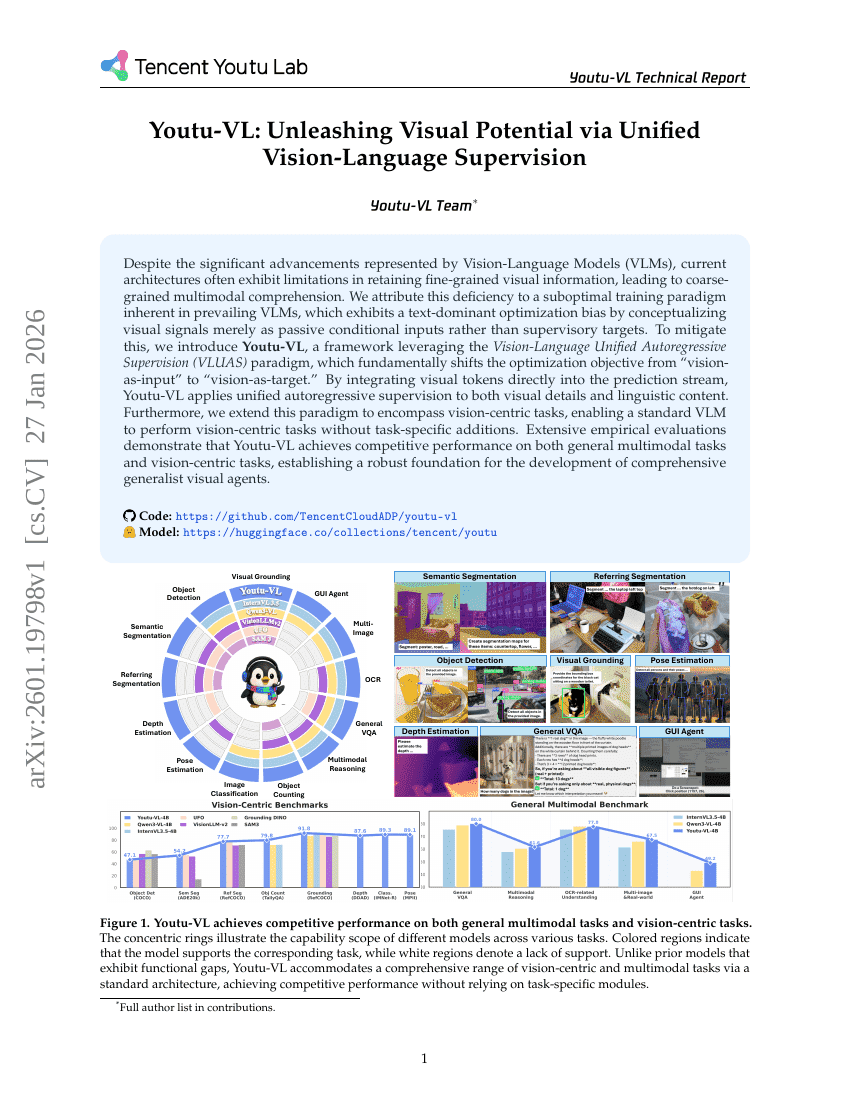
Youtu-VL:統一された視覚言語監督による視覚的潜在能力の解放
Innovator-VL:科学発見を目的としたマルチモーダル大規模言語モデル
オープンソース・ワールドモデルの進展
難易度認識型GRPOと多面的質問再構成を活用した数学的推論の向上
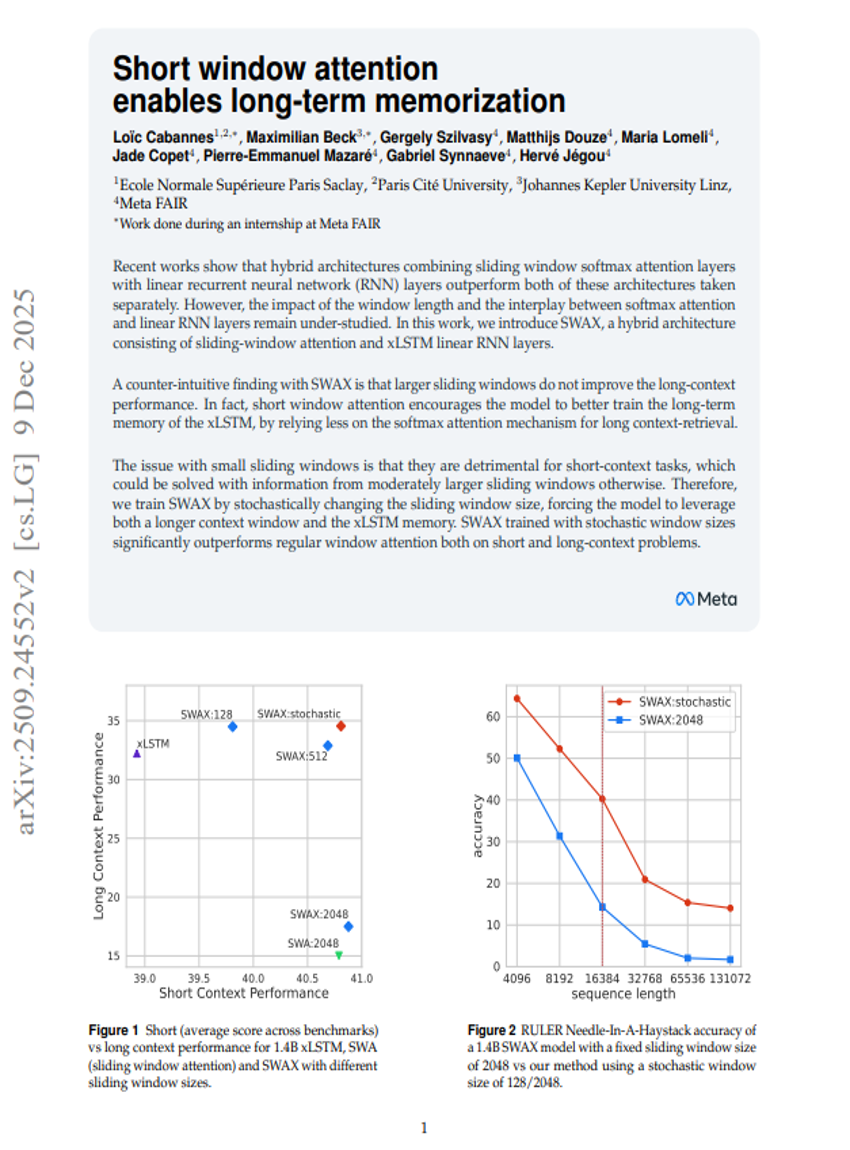
ショートウィンドウアテンションにより長期記憶が可能となる
World Craft:テキストによる可視化可能な世界を創出するエージェントフレームワーク
視覚生成がマルチモーダル・ワールド・モデルを通じて人間のような推論を解き放つ
マスク深度モデリングによる空間認識
実用的なVLA基盤モデル
AdaReasoner:反復的視覚推論のための動的ツールオーケストレーション
AgentDoG:AIエージェントの安全性およびセキュリティを 위한診断ガードレールフレームワーク
ARCEE TRINITY ラージテクニカルレポート
自分自身を学ぶように教える:学習可能性の限界における推論
ATLAS:多言語事前学習、微調整および多言語性の呪いの解読のための適応的転送スケーリング則
iFSQ:1行のコードで画像生成向けFSQを改善する
エラスティックアテンション:効率的なTransformerにおけるテスト時適応型スパース比
科学的画像合成:ベンチマーク、手法論、および下流タスクにおける有用性
スクリプトがすべてである:長期にわたる対話から映像化動画生成を実現するエージェントフレームワーク
daVinci-Dev:ソフトウェアエンジニアリングにおけるエージェントネイティブな中間訓練
LLMはあなたの混乱を整理できるか?LLMを用いたアプリケーション対応データ準備のサーベイ
DeepSeek-OCR 2:視覚的因果フロー
DynamicVLA:動的物体操作を実現する視覚言語行動モデル
MMFineReason:オープンデータ中心主義的手法によるマルチモーダル推論ギャップの解消
OCRVerse:エンドツーエンド視覚言語モデルにおける包括的なOCRへの道標
埋め込みのスケーリングは、言語モデルにおけるエキスパートのスケーリングを上回る
Idea2Story:研究コンセプトを完全な科学的物語に変換する自動化パイプライン
すべてのものがその適切な場所にある:テキストから画像モデルの空間的知能をベンチマークする
Qwen3-ASR 技術報告
インサイトエージェント:データインサイトを実現するLLMベースのマルチエージェントシステム
ピクセルレベルのVLM Perception を実現するためのシンプルなポイント予測
Youtu-VL:統一された視覚言語監督による視覚的潜在能力の解放
Innovator-VL:科学発見を目的としたマルチモーダル大規模言語モデル
オープンソース・ワールドモデルの進展
難易度認識型GRPOと多面的質問再構成を活用した数学的推論の向上
ショートウィンドウアテンションにより長期記憶が可能となる
World Craft:テキストによる可視化可能な世界を創出するエージェントフレームワーク
視覚生成がマルチモーダル・ワールド・モデルを通じて人間のような推論を解き放つ
マスク深度モデリングによる空間認識
実用的なVLA基盤モデル
AdaReasoner:反復的視覚推論のための動的ツールオーケストレーション
AgentDoG:AIエージェントの安全性およびセキュリティを 위한診断ガードレールフレームワーク
ARCEE TRINITY ラージテクニカルレポート
自分自身を学ぶように教える:学習可能性の限界における推論
ATLAS:多言語事前学習、微調整および多言語性の呪いの解読のための適応的転送スケーリング則
iFSQ:1行のコードで画像生成向けFSQを改善する
エラスティックアテンション:効率的なTransformerにおけるテスト時適応型スパース比
科学的画像合成:ベンチマーク、手法論、および下流タスクにおける有用性
スクリプトがすべてである:長期にわたる対話から映像化動画生成を実現するエージェントフレームワーク
daVinci-Dev:ソフトウェアエンジニアリングにおけるエージェントネイティブな中間訓練
LLMはあなたの混乱を整理できるか?LLMを用いたアプリケーション対応データ準備のサーベイ
DeepSeek-OCR 2:視覚的因果フロー