Command Palette
Search for a command to run...
CoDance:ロバストなマルチサブジェクトアニメーションのためのアンバインド・リバインドパラダイム
CoDance:ロバストなマルチサブジェクトアニメーションのためのアンバインド・リバインドパラダイム
Shuai Tan Biao Gong Ke Ma Yutong Feng Qiyuan Zhang Yan Wang Yujun Shen Hengshuang Zhao
概要
キャラクター画像のアニメーションは、多対象レンダリングにおける堅牢性と柔軟性への需要に伴い、さまざまな分野でますます重要な役割を果たしています。既存の手法は単一人物のアニメーションにおいて優れた性能を発揮していますが、任意の対象数や多様なキャラクター種別、また参照画像とドライブポーズとの間の空間的な不整合(spatial misalignment)を適切に処理することができません。これらの制限要因は、ポーズと参照画像の間に過度に厳格な空間的バインディング(spatial binding)が存在し、ピクセル単位での厳密な一致を強制するためであり、また意図した対象に運動を一貫して再バインディングできない点に起因すると考えられます。この課題に対処するため、本研究では、単一の(場合によっては空間的にずれた)ポーズシーケンスを条件として、任意の対象数・種別・空間配置のキャラクターをアニメーション可能にする、新たな「Unbind-Rebind」フレームワークであるCoDanceを提案します。具体的には、Unbindモジュールは、ポーズおよびその潜在特徴に確率的摂動(stochastic perturbations)を導入する独自のポーズシフトエンコーダを採用し、ポーズと参照画像の間の過度な空間的拘束を解消することで、位置に依存しない運動表現(location-agnostic motion representation)の学習を促進します。さらに、正確な制御と対象の関連付けを実現するため、テキストプロンプトからの意味的ガイダンスと、対象マスクからの空間的ガイダンスを活用したRebindモジュールを設計しました。また、包括的な評価を可能にするために、新たな多対象評価ベンチマーク「CoDanceBench」を導入しました。CoDanceBenchおよび既存のデータセットを用いた広範な実験により、CoDanceが最先端(SOTA)の性能を達成し、多様な対象や空間配置において優れた汎化能力を示すことが確認されました。本研究のコードおよび学習済み重みは、公開予定です。
One-sentence Summary
The authors from The University of Hong Kong, Ant Group, Huazhong University of Science and Technology, Tsinghua University, and the University of North Carolina at Chapel Hill propose CoDance, a novel Unbind-Rebind framework that enables pose-controllable multi-subject animation from a single misaligned pose sequence by learning location-agnostic motion representations through stochastic pose perturbations and re-binding motion via text and mask guidance, achieving state-of-the-art results on diverse subject counts and spatial configurations.
Key Contributions
- Existing character animation methods fail in multi-subject scenarios due to rigid spatial binding between reference images and driving poses, leading to misaligned or entangled outputs when handling arbitrary subject counts, types, or spatial configurations.
- CoDance introduces an Unbind-Rebind framework: the Unbind module uses stochastic pose and feature perturbations via a novel pose shift encoder to learn location-agnostic motion representations, while the Rebind module leverages text prompts and subject masks for precise, controllable animation of intended characters.
- Extensive evaluations on the new CoDanceBench and existing datasets demonstrate state-of-the-art performance, with strong generalization across diverse subjects, spatial layouts, and misaligned inputs, validated through both quantitative metrics and perceptual quality.
Introduction
Character image animation is increasingly vital for applications like virtual performances, advertising, and educational content, where animating multiple subjects with diverse types and spatial arrangements is common. Prior methods, while effective for single-person animation, fail in multi-subject scenarios due to rigid spatial binding between pose and reference image, which requires precise alignment and limits scalability beyond two subjects. This leads to motion entanglement, poor generalization to non-human characters, and sensitivity to misalignment. The authors introduce CoDance, a novel Unbind-Rebind framework that decouples motion from appearance by applying stochastic perturbations to pose skeletons and their latent features during training, enabling the model to learn location-agnostic motion semantics. To restore precise control, the Rebind module uses text prompts for semantic guidance and subject masks for spatial localization, allowing accurate animation of arbitrary subject counts and configurations even under misalignment. The approach is validated on a new benchmark, CoDanceBench, demonstrating state-of-the-art performance and strong generalization across diverse layouts and character types.
Dataset

- The dataset comprises public TikTok and Fashion datasets, augmented with approximately 1,200 self-collected TikTok-style videos.
- For the Rebind stage, training is enhanced with 10,000 text-to-video samples to strengthen semantic associations and 20 multi-subject videos to guide spatial binding.
- Evaluation includes single-person and multi-subject settings:
- Single-person: 10 videos from TikTok and 100 from Fashion, following prior work [13, 14, 75].
- Multi-subject: Uses the Follow-Your-Pose-V2 benchmark and a new curated benchmark, CoDanceBench, consisting of 20 multi-subject dance videos.
- To ensure fair comparison, quantitative results are reported using a model trained only on solo dance videos, excluding multi-subject data from CoDanceBench.
- The authors use a mixture of training data with specific ratios during training, though exact proportions are not detailed.
- No explicit cropping strategy is described, but videos are processed to align with pose and motion inputs.
- Metadata construction involves aligning video content with pose sequences and textual descriptions, particularly for text-to-video samples and multi-subject coordination.
- Evaluation metrics include frame-level measures (PSNR, SSIM, L1, LPIPS) for perceptual fidelity and distortion, and video-level metrics (FID, FID-VID, FVD) to assess distributional realism.
Method
The authors leverage a diffusion-based framework for multi-character animation, structured around a Diffusion Transformer (DiT) backbone. The overall pipeline, as illustrated in the framework diagram, begins with a reference image Ir, a driving pose sequence I1:Fp, a text prompt T, and a subject mask M. A Variational Autoencoder (VAE) encoder extracts the latent feature fer from the reference image. This latent representation, along with the subject mask, forms the initial input for the generative process. The driving pose sequence is processed by a Pose Shift Encoder, which is composed of stacked 3D convolutional layers to capture both temporal and spatial features. The extracted pose features are then concatenated with the patchified tokens of the noisy latent input, forming the conditioned input for the DiT backbone.
The core innovation of the method lies in the Unbind-Rebind paradigm, which is designed to overcome the limitations of rigid spatial alignment. The Unbind module, implemented as a Pose Shift Encoder, operates at both the input and feature levels to decouple the pose from its original spatial context. At the input level, the Pose Unbind module stochastically disrupts the alignment by randomly translating and scaling the skeleton of the driving pose. At the feature level, the Feature Unbind module further augments the pose features by applying random translations and duplicating the feature region corresponding to the pose, thereby forcing the model to learn a more abstract, semantic understanding of motion. This process ensures the model does not rely on a fixed spatial correspondence between the reference image and the target pose.
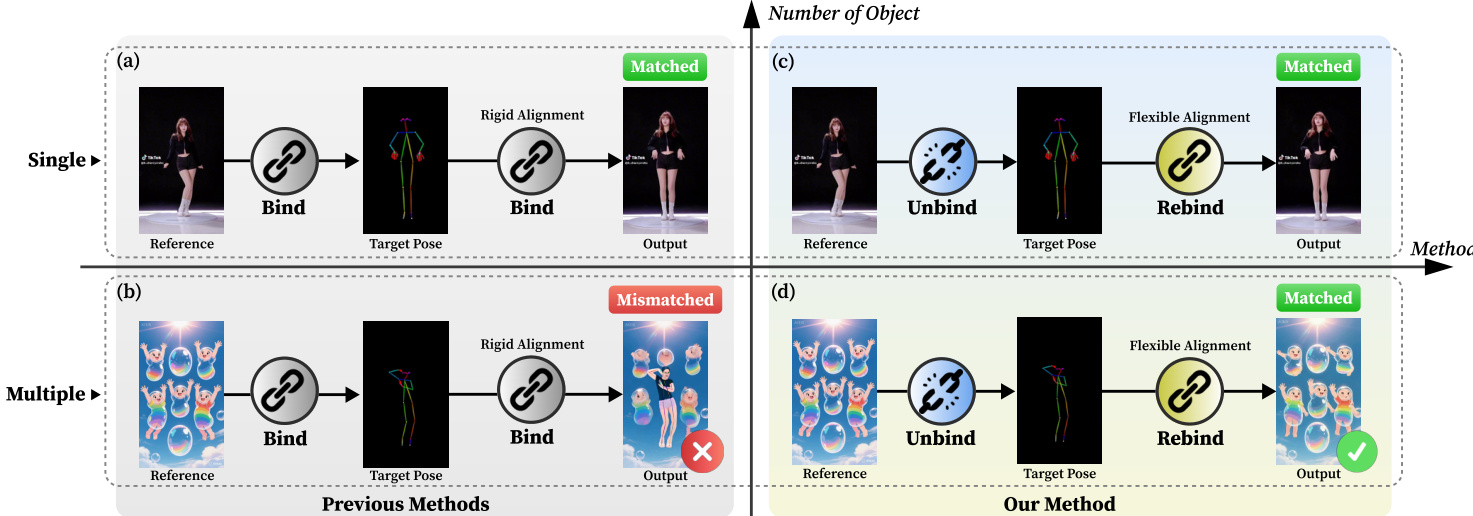
Following the Unbind operation, the Rebind module re-establishes the correct correspondence between the learned motion and the target subjects in the reference image through two complementary mechanisms. From a semantic perspective, a text prompt T is processed by a umT5 text encoder, and the resulting features are injected into the DiT blocks via cross-attention layers. This provides explicit guidance on the identity and number of subjects to be animated. To address figure-ground ambiguity and ensure precise spatial control, a spatial rebind mechanism is employed. A subject mask M, extracted from the reference image using a pretrained segmentation model like SAM, is fed into a Mask Encoder. The resulting mask features are added element-wise to the noisy latent vector, confining the animation to the specified regions. To enhance the model's semantic comprehension and prevent overfitting to animation-specific prompts, the training process alternates between animation data and a diverse text-to-video (TI2V) dataset. The DiT backbone is initialized from a pretrained T2V model and fine-tuned using Low-Rank Adaptation (LoRA) layers. Finally, the denoised latent representation is passed to the VAE decoder to reconstruct the output video I1:Fg. It is important to note that the Unbind modules and the mixed-data training strategy are applied exclusively during the training phase.
Experiment
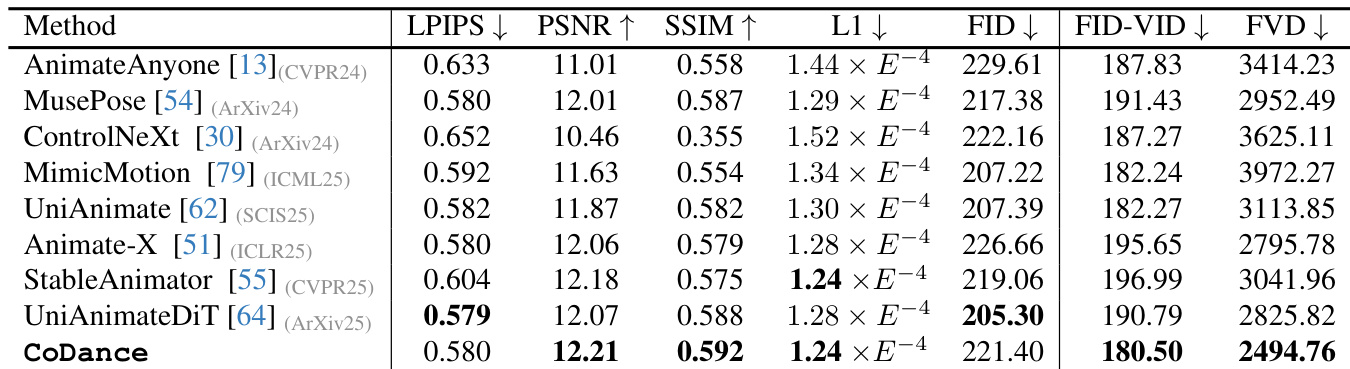
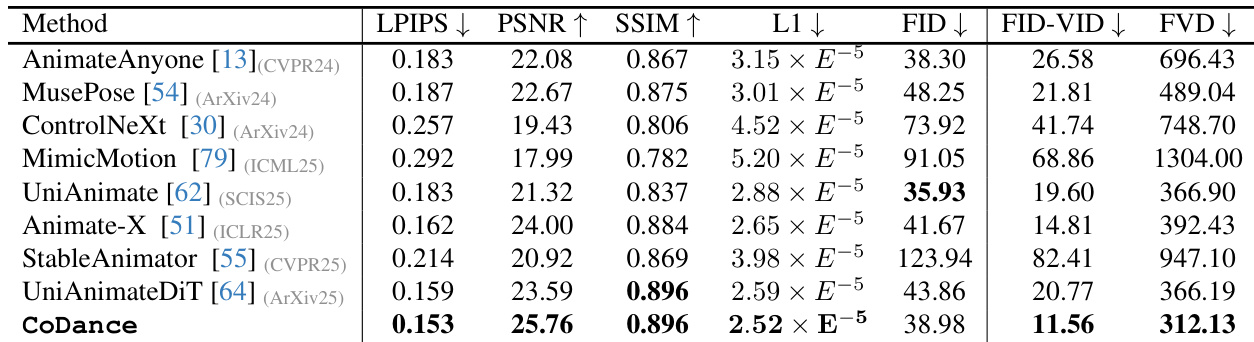
- Evaluated against SOTA methods (AnimateAnyone, MusePose, ControlNeXt, MimicMotion, UniAnimate, Animate-X, StableAnimator, UniAnimate-DiT) on Follow-Your-Pose-V2 and proposed benchmark; our method outperforms all in perceptual similarity (LPIPS), identity consistency (PSNR/SSIM), and motion fidelity (FID-FVD, FVD), demonstrating superiority in multi-subject animation despite training on single-person data.
- In a challenging single-person driving pose to multi-subject reference scenario, our method maintains identity preservation and motion coherence, while baselines fail due to rigid binding and inability to handle cardinality mismatch.
- Qualitative results (Fig. 4, Fig. 5) show our method consistently generates accurate, semantically correct animations across 1–5 subjects, avoiding artifacts like identity confusion and motion distortion, unlike competing methods that suffer from shape distortion and uncoordinated motion.
- User study (Tab. 3) with 10 participants shows our method achieves the highest preference rates across video quality, identity preservation, and temporal consistency, confirming perceptual superiority.
- Ablation study confirms the necessity of both Unbind and Rebind modules: Unbind enables identity preservation by breaking rigid alignment, Spatial Rebind enables motion localization, and the full model achieves coherent, subject-specific animation by combining both components.
Results show that CoDance outperforms all compared methods across key metrics, achieving the lowest LPIPS and FID scores and the highest PSNR, SSIM, and FVD values. The authors use this table to demonstrate that their method significantly improves perceptual similarity, identity consistency, and motion fidelity compared to existing single-person models, which fail in multi-subject scenarios due to rigid alignment constraints.
Results show that CoDance achieves the highest scores across all three evaluation metrics—Video Quality, Identity Preservation, and Temporal Consistency—outperforming all compared methods. This demonstrates the effectiveness of the proposed Unbind-Rebind strategy in maintaining identity and motion coherence in multi-subject animation scenarios.

Results show that CoDance outperforms all compared methods across multiple metrics, achieving the lowest LPIPS and FID-VID scores and the highest PSNR, SSIM, and FVD scores, indicating superior perceptual similarity, identity consistency, and motion fidelity. The authors use a multi-subject animation setup to demonstrate that conventional single-person models fail due to rigid alignment, while CoDance's Unbind-Rebind strategy enables accurate and coherent motion generation for each subject despite being trained under the same single-person data constraint.