Command Palette
Search for a command to run...
都市におけるビジュアル・ランゲージ推論を用いたソーシャル意味セグメンテーション
都市におけるビジュアル・ランゲージ推論を用いたソーシャル意味セグメンテーション
Yu Wang Yi Wang Rui Dai Yujie Wang Kaikui Liu Xiangxiang Chu Yansheng Li
概要
都市は人間活動の拠点であり、多様な意味的エンティティが集積した表面構造を持つ。こうした多様なエンティティを衛星画像からセグメンテーションすることは、さまざまな後続応用において極めて重要である。現在の最先端セグメンテーションモデルは、物理的属性(例:建物、水域)で定義されるエンティティを信頼性高くセグメントできるが、社会的に定義されたカテゴリ(例:学校、公園)については依然として困難を抱えている。本研究では、視覚言語モデルを用いた推論により、社会的意味的セグメンテーションを実現する。これを可能にするために、我々は新しいデータセット「Urban Socio-Semantic Segmentation dataset(SocioSeg)」を提案する。このデータセットは、衛星画像、デジタル地図、および階層構造で整理された社会的意味的エンティティのピクセルレベルラベルを含む。さらに、人間が跨モーダル認識と多段階推論を通じて社会的意味的エンティティを識別・ラベル付けするプロセスを模倣する、新規の視覚言語推論フレームワーク「SocioReasoner」を提案する。この非微分可能な推論プロセスを最適化するために強化学習を活用し、視覚言語モデルの推論能力を引き出す。実験の結果、本手法は最先端モデルを上回る性能を示し、強力なゼロショット一般化能力を有することが確認された。本研究のデータセットおよびコードは、https://github.com/AMAP-ML/SocioReasoner にて公開されている。
One-sentence Summary
Wuhan University and Amap, Alibaba Group propose SocioReasoner, a vision-language reasoning framework that enables socio-semantic segmentation in satellite imagery by simulating human-like cross-modal recognition and multi-stage reasoning, leveraging a new hierarchical dataset (SocioSeg) and reinforcement learning to achieve superior performance and zero-shot generalization beyond traditional physical attribute-based segmentation.
Key Contributions
- Socio-semantic segmentation of urban areas remains challenging because socially defined entities like schools and parks lack distinct visual features and are difficult to identify from satellite imagery alone, unlike physically defined entities such as buildings or water bodies.
- The authors introduce SocioSeg, a new benchmark dataset with hierarchical labeling of social semantic entities and a unified digital map layer that resolves issues of data heterogeneity and alignment, enabling more effective multi-modal learning.
- They propose SocioReasoner, a vision-language framework using a two-stage render-and-refine mechanism with reinforcement learning to simulate human-like reasoning, achieving state-of-the-art performance and strong zero-shot generalization on socio-semantic segmentation tasks.
Introduction
Urban socio-semantic segmentation aims to identify socially defined entities in satellite imagery—such as schools, parks, and residential districts—crucial for applications in urban planning, environmental monitoring, and location-based services. Unlike physical entities (e.g., buildings, roads), these social semantic categories lack distinct visual signatures and are defined by human activity and function, making them difficult to segment using traditional vision-only models. Prior approaches rely on auxiliary geospatial data like Points of Interest, but face challenges including data scarcity, heterogeneous formats, spatial misalignment, and limited generalization to unseen categories. To address these issues, the authors introduce SocioSeg, a new benchmark dataset that unifies multi-modal geospatial data into a spatially aligned digital map layer, enabling a consistent visual reasoning task. They further propose SocioReasoner, a vision-language reasoning framework that mimics human annotation through a two-stage, render-and-refine process: first generating bounding box prompts from satellite and map imagery, then refining segmentation with point prompts via SAM. Since this pipeline is non-differentiable, they employ reinforcement learning with a custom reward function to optimize the entire workflow, effectively unlocking the reasoning capabilities of vision-language models. The approach achieves state-of-the-art performance and strong zero-shot generalization, demonstrating the power of cross-modal reasoning for complex urban understanding.
Dataset

- The SocioSeg dataset is constructed from publicly available satellite imagery and digital maps sourced via the Amap public API, covering all provinces and major cities across China.
- It includes over 13,000 samples organized into three hierarchical socio-semantic segmentation tasks: Socio-names (e.g., "Peking University"), Socio-classes (e.g., "college"), and Socio-functions (e.g., "educational"), with more than 5,000 unique Socio-names, 90 Socio-classes, and 10 Socio-functions.
- Ground-truth labels are derived from Amap’s Area of Interest (AOI) data, which is reformatting from vector-based polygons into rasterized semantic masks through a rigorous quality assurance process.
- The dataset was refined from an initial pool of ~40,000 samples by manually verifying alignment between AOI polygons and physical boundaries, resulting in a final set of 13,000 high-quality samples.
- An inter-annotator agreement study on 500 random samples achieved a Cohen’s Kappa of 0.854, confirming strong label consistency and reliability.
- Each sample consists of a satellite image, a digital map, and a corresponding socio-semantic mask, with the digital map layer integrating roads and points of interest to serve as a unified, co-registered modality.
- The dataset is split into training, validation, and test sets using a 6:1:3 ratio, preserving balanced sample counts and class distributions across all three hierarchical tasks.
- The authors use the dataset for training and evaluation, employing a mixture of the three hierarchical tasks with task-specific training ratios to support progressive learning.
- No explicit cropping strategy is applied; instead, the dataset uses full scene inputs aligned to the original geographic extent of the AOI.
- Metadata is constructed from Amap’s standardized taxonomy and functional zone definitions, ensuring alignment with real-world urban social activities and enabling robust social reasoning.
Method
The SocioReasoner framework employs a two-stage reasoning segmentation process designed to emulate the sequential workflow of a human annotator, enhancing both precision and interpretability. The overall architecture consists of a Vision-Language Model (VLM) that generates structured textual prompts for a frozen segmentation model, SAM, in a render-and-refine mechanism. This process is divided into two distinct stages: localization and refinement.
In the first stage, the VLM takes as input a satellite image, a digital map, and a textual instruction to generate a set of 2D bounding boxes that localize candidate regions of interest. These bounding boxes are then used as prompts for SAM to produce a preliminary coarse mask. The coarse mask and the initial bounding boxes are subsequently rendered onto the original inputs to provide visual feedback for the second stage. As shown in the figure below, this rendering step overlays the bounding boxes and the coarse mask onto both the satellite image and the digital map, producing a pair of augmented images that are re-evaluated by the VLM.
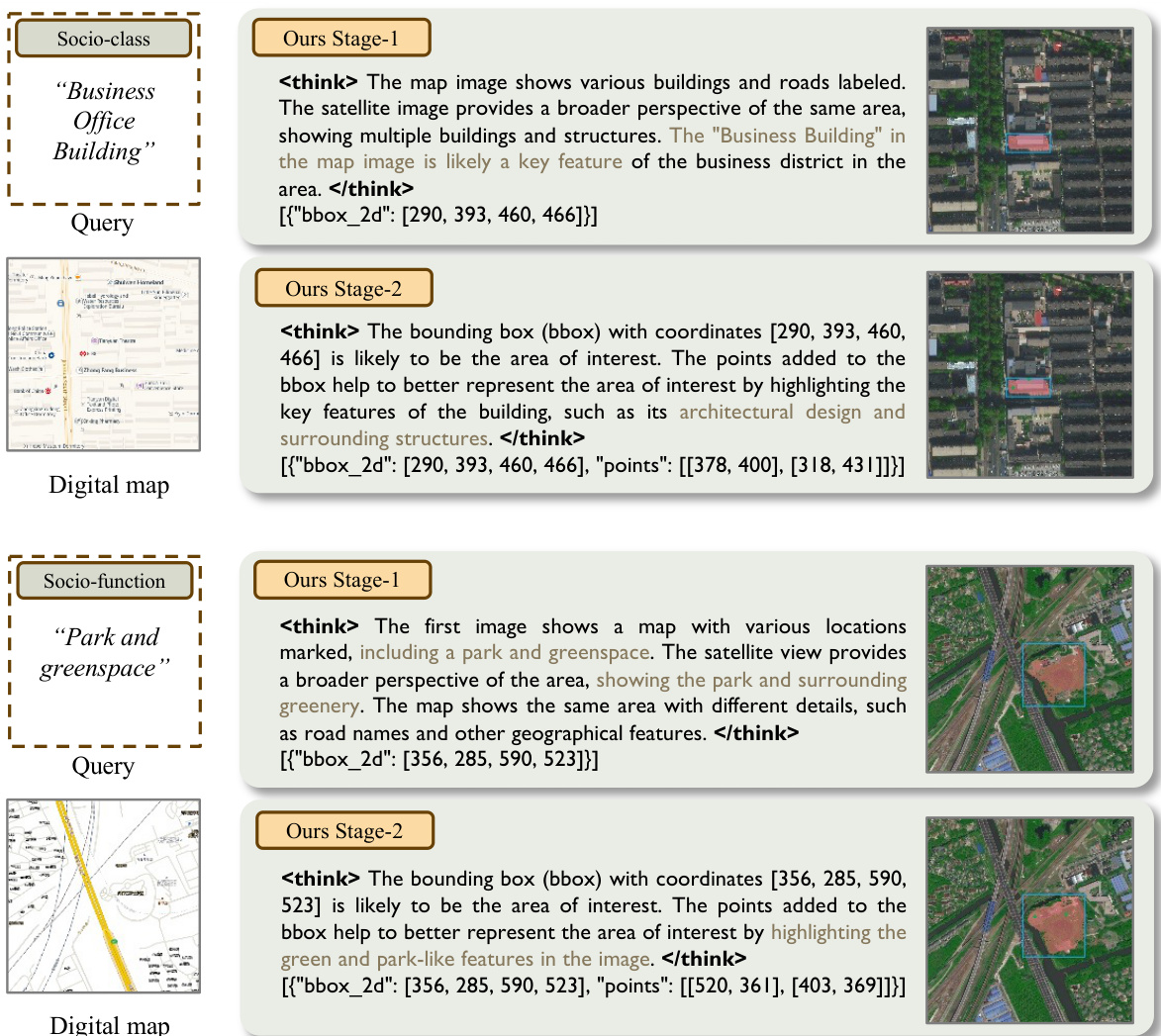
In the second stage, the VLM, conditioned on the rendered images and a new textual instruction, emits a refined set of bounding boxes and points. These combined prompts are fed back into SAM to generate the final segmentation mask. The entire pipeline is non-differentiable due to the discrete nature of the prompt generation and the fixed parameters of SAM, necessitating an optimization strategy that can handle such a structure.
To optimize the VLM's prompting policy across both stages, the authors employ Group Relative Policy Optimization (GRPO), a reinforcement learning method. A single VLM policy is shared between the two stages, generating structured textual outputs that encode the prompts. The environment parses these outputs, executes SAM with the parsed prompts, and returns a scalar reward. The optimization process is conducted in two phases corresponding to the two stages. For the first stage, the policy generates bounding boxes based on the initial inputs, and the environment evaluates the generated boxes by computing a reward that includes a binary syntax check, localization accuracy, and object count matching. The second stage refines the prompts based on the rendered visual feedback and the coarse mask, with the reward incorporating a pixel-level IoU measure and a term for the length of the point set.
The training schedule executes both stages sequentially within a single reinforcement learning step: first, the stage-1 rollouts are sampled, evaluated, and used to update the policy with the stage-1 objective; then, the stage-2 inputs are constructed from the stage-1 outputs, and the process is repeated for the second stage. This two-stage procedure ensures that the optimization aligns with the sequential localization–refinement workflow. The overall training algorithm is summarized in Algorithm 1, which details the end-to-end reinforcement learning process.
Experiment
- Compared against three families of methods: standard semantic segmentation (UNet, SegFormer), natural image reasoning segmentation (VisionReasoner, Seg-R1, SAM-R1), and satellite image segmentation (SegEarth-OV, RSRefSeg, SegEarth-R1, RemoteReasoner). All baselines re-trained on SocioSeg training split; dual-image inputs adapted where necessary.
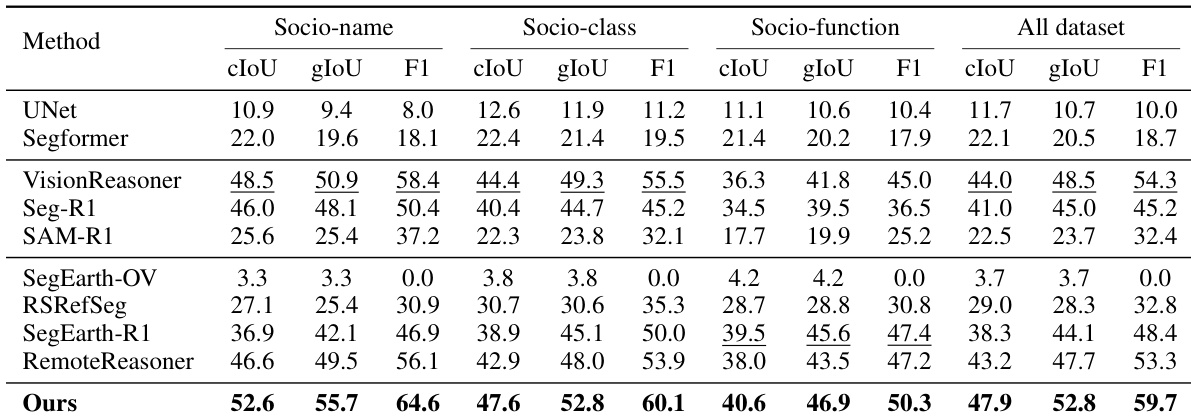
- On the SocioSeg test set, SocioReasoner achieves state-of-the-art performance across all three hierarchical tasks, with significant gains over baselines in cIoU and gIoU, demonstrating the effectiveness of its two-stage human-like reasoning process and integration of satellite and map context.
- Outperforms standard models (UNet, SegFormer) by a large margin, which fail to handle multimodal inputs and social semantics, reducing the task to binary classification.
- Surpasses natural image reasoning methods (VisionReasoner, Seg-R1, SAM-R1) due to its multi-stage refinement, enabling self-correction and improved geometric accuracy despite longer inference time.
- Exceeds satellite-specific methods: SegEarth-OV fails due to frozen CLIP encoder; RSRefSeg and SegEarth-R1 underperform due to single-image input and limited social semantics; RemoteReasoner is outperformed by SocioReasoner’s two-stage localization and refinement.
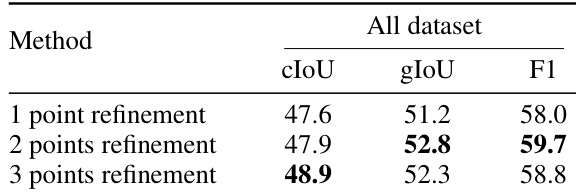
- Ablation studies confirm the superiority of the two-stage design: "w/o reflection" (single-stage) performs worst due to lack of self-correction; "w/o refinement" (Stage-1 only) underperforms; optimal performance achieved with two-point refinement in Stage-2.
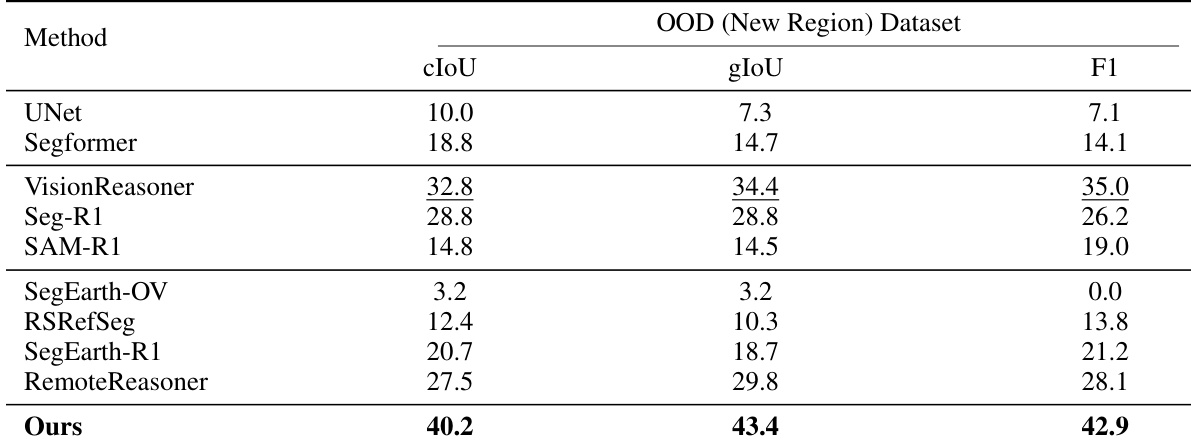
- Reinforcement learning (RL) training significantly enhances generalization: SocioReasoner with RL outperforms SFT baseline on both in-domain (Amap) and out-of-domain (OOD) datasets, including OOD (Map Style) and OOD (New Region) with 24 novel classes across five global cities.
- On the OOD (New Region) dataset, SocioReasoner achieves the highest performance across all metrics, demonstrating strong robustness to geographic and cartographic variations.
- Inference time is higher than baselines due to iterative reasoning, but the trade-off is justified by superior accuracy and generalization.
- Per-class analysis shows strong performance on top-20 most frequent classes; lower accuracy on specific classes (e.g., Training Institution, Badminton Court) due to error propagation from initial localization failures.
- Failure cases reveal two main issues: localization failure in cluttered urban areas and boundary imprecision, highlighting challenges in mapping abstract social semantics to precise spatial boundaries.
The authors compare the impact of the number of points used in the refinement stage of SocioReasoner, showing that using three points achieves the highest cIoU and F1 scores, while two points yield the best gIoU. This indicates that increasing the number of points improves overall segmentation accuracy, but the optimal choice depends on the evaluation metric.
The authors compare their SocioReasoner framework against large multimodal models, including GPT-5, GPT-o3, and Qwen2.5-VL variants, on the SocioSeg benchmark. Results show that while GPT-5 and GPT-o3 achieve moderate performance, the Qwen2.5-VL-72b model outperforms all others, achieving the highest cIoU and gIoU scores across all tasks, particularly in Socio-name and Socio-function segmentation.

The authors compare their SocioReasoner framework against several state-of-the-art methods on the OOD (New Region) dataset, which evaluates performance across diverse geographic regions and includes novel categories. Results show that SocioReasoner achieves the highest scores across all metrics—cIoU, gIoU, and F1—demonstrating its superior generalization and robustness compared to baselines.
The authors use a multi-stage reasoning framework to outperform all baselines across all tasks in the SocioSeg benchmark, achieving the highest scores in cIoU, gIoU, and F1 on both socio-name and socio-function segmentation. The results show that the proposed method significantly surpasses standard segmentation models and state-of-the-art reasoning methods, particularly in capturing complex social semantics through iterative refinement and dual-image input processing.
The authors compare SocioReasoner with several state-of-the-art methods on the SocioSeg benchmark, with results showing that their approach achieves the highest performance across all metrics. Specifically, SocioReasoner (rl) outperforms all baselines, including VisionReasoner, SAM-R1, and RemoteReasoner, with a cIoU of 2.71, significantly higher than the second-best method, VisionReasoner, at 1.33.
