Command Palette
Search for a command to run...
STEM:埋め込みモジュールを用いたTransformerのスケーリング
STEM:埋め込みモジュールを用いたTransformerのスケーリング
Ranajoy Sadhukhan Sheng Cao Harry Dong Changsheng Zhao Attiano Purpura-Pontoniere Yuandong Tian Zechun Liu Beidi Chen
概要
細粒度スパース性は、トークン当たりの計算量に比例せずにパラメータ容量を向上させる可能性を秘めているが、しばしば訓練の不安定性、負荷バランスの悪化、通信オーバーヘッドといった課題に直面する。本研究では、埋め込みモジュール(Embedding Modules)を用いたスケーリング手法であるSTEM(Scaling Transformers with Embedding Modules)を提案する。STEMは静的かつトークンインデックスに基づくアプローチであり、FFNのアッププロジェクション部分をレイヤー内局所的な埋め込み検索に置き換える一方で、ゲート部およびダウンプロジェクション部は密行列(dense)のまま維持する。この設計により、実行時におけるルーティング処理を排除し、非同期プリフェッチを活用したCPUオフロードが可能となり、パラメータ容量をトークン当たりのFLOPsおよびデバイス間通信から独立させる。実証実験では、極めて高いスパース性下でもSTEMは安定した訓練を実現した。密なベースラインと比較して、ダウンストリーム性能を向上させつつ、トークン当たりのFLOPsおよびパラメータアクセス数を削減(FFNパラメータの約1/3を削減)した。STEMは、大きな角度間隔を持つ埋め込み空間を学習する能力を有しており、これにより知識の保存容量が向上する。さらに興味深い点として、この強化された知識容量は解釈可能性の向上にも寄与する。STEMの埋め込みはトークンインデックスに基づく性質を有しており、入力テキストへの介入や追加計算を一切行わずに、単純な手法で知識の編集や注入を解釈可能な形で実現できる。また、STEMは長文処理性能を強化する:シーケンス長が増加するにつれて、より多くの異なるパラメータが活性化され、実際のテスト時における容量スケーリングが可能となる。3.5億パラメータおよび10億パラメータ規模のモデルにおいて、STEMは全体で最大約3~4%の精度向上を達成し、特に知識・推論に依存するベンチマーク(ARC-Challenge、OpenBookQA、GSM8K、MMLU)で顕著な改善を示した。総合的にみて、STEMはパラメトリックメモリを効果的にスケーリングしつつ、解釈可能性の向上、訓練の安定性の強化、効率性の改善を同時に実現する有効な手法である。
One-sentence Summary
Carnegie Mellon University and Meta AI introduce STEM, a static, token-indexed sparse architecture that replaces the FFN up-projection with layer-local embedding lookup, enabling stable training, reduced per-token FLOPs and parameter access by ~one-third, and improved long-context performance through scalable parameter activation. By decoupling capacity from compute and communication, STEM supports CPU offload with asynchronous prefetching and achieves higher knowledge storage capacity via embeddings with large angular spread, while offering interpretable, edit-friendly knowledge injection without modifying input text—outperforming dense baselines by up to ~3–4% on knowledge and reasoning benchmarks.
Key Contributions
-
STEM addresses the challenge of scaling parametric capacity in Transformers without increasing per-token compute by replacing the FFN up-projection with a static, token-indexed embedding lookup, eliminating runtime routing and enabling efficient CPU offload with asynchronous prefetching while maintaining dense gate and down-projection layers.
-
The method achieves stable training under extreme sparsity and improves downstream performance on knowledge and reasoning benchmarks (e.g., ARC-Challenge, GSM8K, MMLU) by up to ~3-4% over dense baselines, while reducing per-token FLOPs and parameter accesses by roughly one-third through a learned embedding space with large angular spread that enhances knowledge storage.
-
STEM’s token-indexed embedding design enables interpretable knowledge editing and injection without modifying input text or adding computation, and its capacity scales practically with sequence length as more distinct parameters are activated, offering improved long-context performance and system efficiency compared to MoE and PKM approaches.
Introduction
The authors leverage a static, token-indexed embedding module to scale Transformers efficiently, replacing the feed-forward network's up-projection with a layer-local lookup while keeping the gate and down-projection dense. This design enables significant reductions in per-token FLOPs and parameter accesses—eliminating roughly one-third of FFN parameters—without increasing cross-device communication or runtime routing overhead. Unlike prior sparse methods such as MoE, which rely on dynamic routing and suffer from training instability and load imbalance, or PKM models that face high inference lookup costs and under-training issues, STEM achieves stable training at extreme sparsity levels. Its key innovation lies in decoupling parametric capacity from compute and communication, enabling CPU offload with asynchronous prefetching and scalable long-context performance. The learned embedding spaces exhibit large angular spread, enhancing knowledge storage and interpretability, allowing direct knowledge editing and injection without modifying input text or adding computation. STEM delivers up to 3–4% accuracy gains on knowledge and reasoning benchmarks across 350M and 1B models, offering a robust, efficient, and interpretable path to scaling parametric memory in large language models.
Dataset

- The dataset is composed of multiple sources: OLMo-MIX-1124 (3.9T tokens), a mixture of DCLM and Dolma 1.7; NEMOTRON-CC-MATH-v1 (math-focused); and NEMOTRON-PRETRAINING-CODE-v1 (code-focused).
- For pretraining, the authors subsample 1T tokens from OLMo-MIX-1124.
- During mid-training, the data mix consists of 65% OLMo-MIX-1124, 5% NEMOTRON-CC-MATH-v1, and 30% NEMOTRON-PRETRAINING-CODE-v1.
- For context-length extension, the authors use PROLONG-DATA-64K, which is 63% long-context and 37% short-context, with sequences packed up to 32,768 tokens using cross-document attention masking.
- The data is processed with no explicit cropping, but sequences are packed to fit the model’s maximum context length.
- Metadata for long-context evaluation is constructed to support the Needle-in-a-Haystack benchmark, which tests retrieval in extended contexts.
- The authors use the pretraining data to train 350M models on 100 billion tokens and 1B models on 1 trillion tokens, with mid-training using 100 billion tokens and context extension using 20 billion tokens.
- Training employs AdamW with a cosine learning rate schedule, 10% warmup, and a minimum LR of 0.1 times the peak.
- The model architecture uses separate input embeddings and language model heads, with one-third of FFN layers replaced by sparse alternatives (STEM or Hash layer MoE), maintaining comparable activated FLOPs to the dense baseline.
Method
The authors leverage a modified feed-forward network (FFN) architecture within a decoder-only transformer, building upon the SwiGLU activation function and the key-value memory perspective of FFNs to introduce the STEM (Static Token-Embedded Mixture) model. The standard SwiGLU FFN, as shown in Figure (a), processes an input hidden state xℓ through a gate projection Wℓg, an up projection Wℓu, and a down projection Wℓd. The transformation is defined as yℓ=Wℓd(SiLU(Wℓgxℓ)⊙(Wℓuxℓ)), where the up projection generates an address vector for retrieving information from the down projection, and the gate projection provides context-dependent modulation.
The STEM design, illustrated in Figure (c), fundamentally rethinks this process by replacing the up projection with a token-indexed embedding lookup. For a given layer ℓ and input token t, the model accesses a per-layer embedding table Uℓ∈RV×dff to retrieve the vector Uℓ[t]. The output is then computed as yℓ=Wℓ(d)(SiLU(Wℓ(g)xℓ)⊙Uℓ[t]). This design choice is motivated by the key-value memory view of FFNs, where the up projection acts as a key for content retrieval, and the gate projection acts as a context-dependent modulator. By replacing the up projection with a static, token-specific embedding, STEM decouples the parametric capacity from the per-token computation, enabling a more efficient and interpretable architecture.
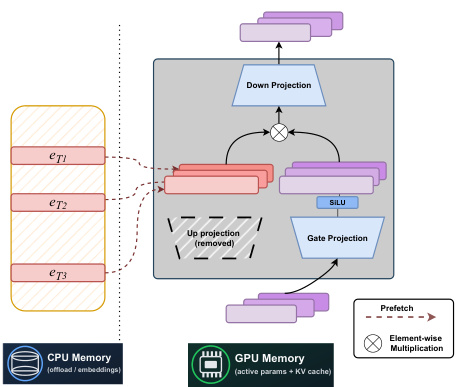
The system architecture, as depicted in the figure, highlights the key components of the STEM model. The model's forward pass begins with the input hidden state xℓ, which is processed by the gate projection Wℓg and passed through the SiLU activation function. Simultaneously, the token t is used to index the CPU memory, where the corresponding STEM embedding Uℓ[t] is prefetched. This embedding is then elementwise multiplied with the output of the SiLU function. The result is passed to the down projection Wℓd to produce the final output yℓ. The figure also shows that the STEM embeddings are stored in CPU memory, which allows for offloading and asynchronous prefetching, reducing the GPU memory footprint and communication overhead. The down projection and gate projection remain in GPU memory as active parameters, while the STEM embeddings are stored in CPU memory, enabling efficient memory management.
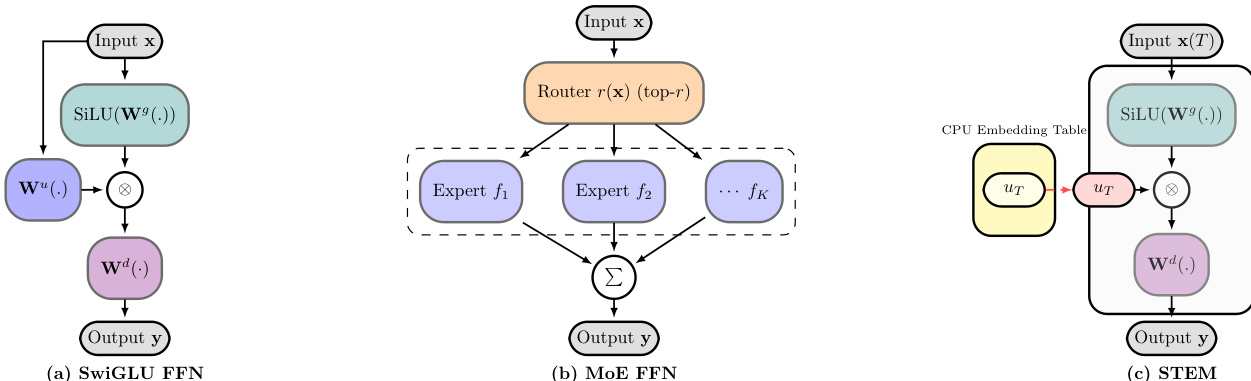
The comparison of architectures in Figure (a), (b), and (c) illustrates the evolution from a standard SwiGLU FFN to a Mixture-of-Experts (MoE) FFN and finally to the STEM FFN. The standard SwiGLU FFN (a) uses a single, dense up projection. The MoE FFN (b) replaces this with multiple expert FFNs and a router that selects a subset of experts based on the input. In contrast, the STEM FFN (c) replaces the up projection with a token-indexed embedding lookup, which is stored in CPU memory. This design avoids the need for a trainable router and the associated communication overhead of expert parallelism, making it more efficient and scalable. The STEM architecture also allows for better interpretability, as the embeddings are directly tied to specific tokens and can be used for knowledge editing.
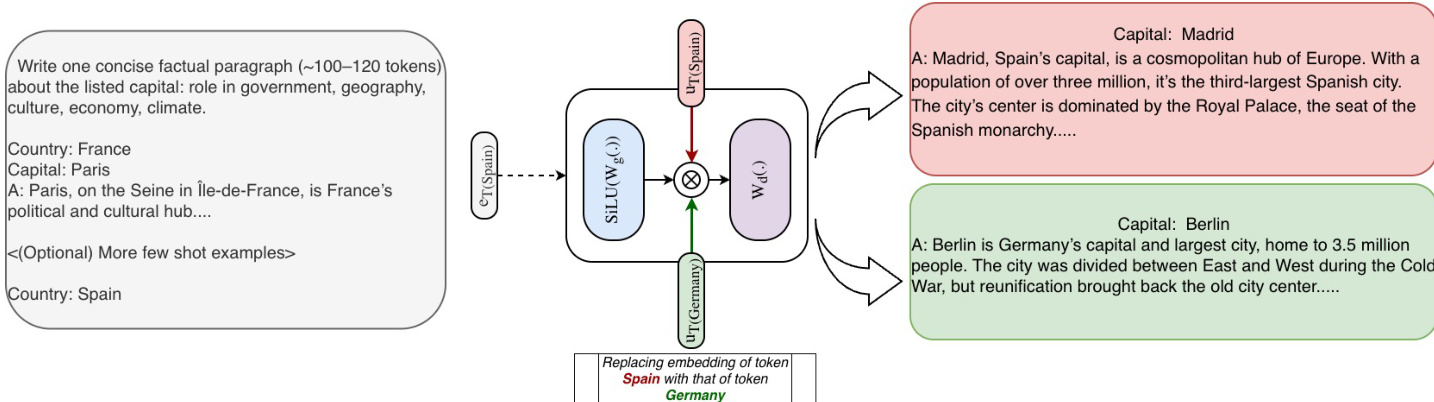
The knowledge editing demonstration in the figure shows how STEM embeddings can be used to modify the model's output by changing the embeddings for specific tokens. The prompt "Country: Spain" is used to generate a paragraph about Madrid. By replacing the STEM embedding for the token "Spain" with the embedding for "Germany", the model generates a paragraph about Berlin instead. This demonstrates the ability of STEM to perform precise, token-indexed knowledge editing, which is a direct consequence of the clear mapping between the embeddings and the tokens. The figure also shows that this editing can be done even when the source and target entities have different tokenization lengths, using strategies such as padding, copying, or subset selection. This ability to manipulate the model's knowledge in a targeted and interpretable way is a key advantage of the STEM architecture.
Experiment
- STEM replaces the up-projection in gated FFNs with token-indexed embeddings, achieving stable training without loss spikes, unlike fine-grained MoE models.
- On ARC-Challenge and OpenBookQA, STEM outperforms the dense baseline by ~9–10% and shows improved performance with more STEM layers.
- STEM improves long-context inference: on Needle-in-a-Haystack, it achieves 13% higher accuracy than the dense baseline at 32k context length.
- STEM reduces per-token FLOPs and parameter accesses by up to one-third, with training ROI improvements of 1.08x (1/3 layers), 1.20x (1/2 layers), and 1.33x (full layers) over the dense baseline.
- STEM exhibits large angular spread in embedding space (low pairwise cosine similarity), enhancing information storage capacity and reducing representational interference.
- STEM enables interpretable, reversible knowledge editing: swapping token-specific embeddings shifts factual predictions (e.g., Madrid → Berlin) without changing input.
- STEM outperforms the dense baseline on GSM8K, MMLU, BBH, MuSR, and LongBench multi-hop/code-understanding tasks, demonstrating superior reasoning and knowledge retrieval.
- STEM maintains efficiency across batch sizes, with sustained FLOPs and memory access savings due to static, token-indexed sparsity and reduced parameter traffic.
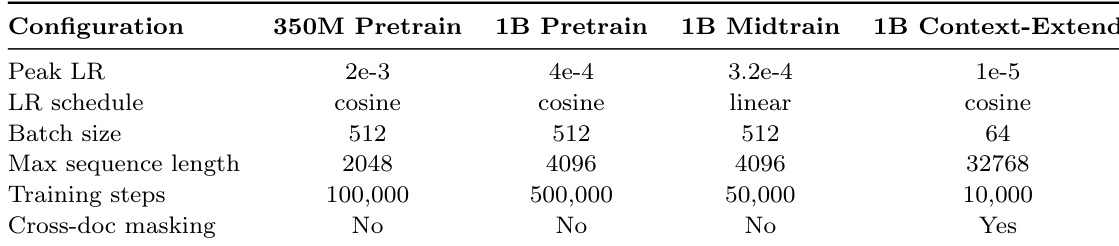
The authors use a consistent learning rate schedule across all configurations, with cosine decay for pretraining and linear decay for midtraining, while adjusting the peak learning rate and batch size to match the computational demands of each setting. Training steps are reduced for midtraining and context-extension tasks, and cross-document masking is enabled only for the context-extension experiment.
Results show that the STEM model achieves higher performance than the dense baseline across all context lengths, with the largest improvement observed in the 0–2k range, where STEM scores 27.6 compared to the baseline's 24.0. The performance gap narrows at longer contexts, but STEM maintains a consistent advantage, indicating improved long-context capabilities.

The authors compare the computational and communication costs of standard FFN and STEM architectures during prefill and decoding. For prefill and training, STEM reduces FLOPs by replacing the up-projection with token-indexed embeddings, resulting in a saving of B(dffL) FLOPs. During decoding, STEM reduces parameter loading cost by half and eliminates communication, achieving a saving of ddff per step.

The authors use STEM to replace the up-projection in gated FFNs with token-indexed embeddings, achieving better training stability and improved performance on knowledge-intensive tasks compared to dense and MoE baselines. Results show that STEM consistently outperforms the dense baseline on benchmarks like ARC-Challenge and OpenBookQA, with gains increasing as more FFN layers are replaced, while also reducing per-token FLOPs and parameter accesses.

The authors compare the STEM model with a dense baseline on a 1B-scale mid-trained model across multiple downstream tasks. Results show that STEM consistently outperforms the baseline on knowledge-intensive tasks such as ARC-E, PIQA, and OBQA, with improvements of 2.1 to 4.1 points, while achieving comparable or slightly better performance on other tasks. The average score across all evaluated tasks increases from 57.50 to 58.49, indicating a general improvement in model performance.
