Command Palette
Search for a command to run...
LLMを活用したソフトウェア工学における問題解決の進展と先端的研究:包括的サーベイ
LLMを活用したソフトウェア工学における問題解決の進展と先端的研究:包括的サーベイ
概要
イシュー解決は、実世界のソフトウェア開発において不可欠な複雑なソフトウェア工学(SWE)タスクであり、人工知能(AI)にとって魅力的な挑戦として浮上している。SWE-bench といったベンチマークの構築により、大規模言語モデル(LLM)にとってこのタスクが極めて困難であることが明らかとなり、自律型コード生成エージェントの発展を著しく加速した。本論文では、この急速に進展している分野について体系的な調査を行う。まず、自動収集および合成アプローチを含むデータ構築パイプラインについて検討する。次に、モジュール構成を有するトレーニング不要なフレームワークから、教師あり微調整や強化学習を含むトレーニングに基づく手法まで、多様なアプローチを包括的に分析する。その後、データ品質およびエージェント行動に関する重要な分析、および実用的応用の状況について考察する。最後に、現在の主要な課題を特定し、今後の研究における有望な方向性を提示する。本分野における動的なリソースとして機能するオープンソースリポジトリは、https://github.com/DeepSoftwareAnalytics/Awesome-Issue-Resolution にて維持されている。
One-sentence Summary
Researchers from Sun Yat-sen University, Huawei, and collaborating institutions survey autonomous issue resolution in software engineering, analyzing data pipelines, agent architectures, and training methods, while identifying key challenges and maintaining an open repository to advance this emerging AI-driven domain.
Key Contributions
- This paper delivers the first systematic survey of AI-driven issue resolution in software engineering, structuring the field around data pipelines, agent methodologies (single/multi-agent and workflow-based), and behavioral analysis, addressing a critical gap left by prior surveys focused only on code generation.
- It introduces a tailored taxonomy and analyzes 175+ works, highlighting innovations such as SWE-agent’s tool-based repository interaction, Darwin Gödel Machine’s self-evolution, and DEIBase’s multi-agent orchestration, while also examining memory architectures that enable context-aware, policy-driven decision-making.
- The survey identifies persistent challenges—including reasoning imprecision, collaboration modeling, and scalability—and provides an open-source repository to track progress, serving as a foundational resource for advancing autonomous coding agents beyond SWE-bench’s benchmark limitations.
Introduction
The authors leverage the rise of large language models to tackle issue resolution in software engineering—a complex, repository-level task that goes beyond function generation and demands environment interaction, tool use, and multi-step reasoning. Prior work, largely focused on code completion or isolated generation, fails to address the dynamic, collaborative, and maintenance-heavy nature of real-world development, as exposed by benchmarks like SWE-bench. Their main contribution is a systematic survey of 175 papers that organizes the field into three pillars: data construction, agent frameworks (single/multi-agent, workflow-based), and empirical analysis—while identifying key gaps in efficiency, safety, multimodal reasoning, and evaluation rigor, and providing an open-source repository to track progress.
Dataset

-
The authors use a mix of evaluation and training datasets, sourced from real-world GitHub repositories and augmented via automated synthesis, to benchmark and train models on software issue resolution.
-
Evaluation datasets include SWE-bench (2,294 Python issues with repo snapshots) and its verified subset SWE-bench Verified, which filters out invalid tests and underspecified descriptions. Multilingual extensions (SWE-bench Multilingual, Multi-SWE-bench) cover 10+ languages including Java, Go, and Rust. Multimodal datasets (e.g., SWE-bench Multimodal, CodeV) integrate UI screenshots and diagrams to support frontend tasks. Enterprise-scale datasets (e.g., from Miserendino et al., Deng et al.) add domain complexity and long-horizon evolution scenarios.
-
Training datasets fall into three categories: (1) Textual data—static issue-PR pairs from SWE-bench; (2) Environment data—interactive Docker/Conda setups (e.g., Multi-SWE-RL, R2E-Gym) that let models receive execution feedback; and (3) Trajectory data—recorded agent-environment interactions (e.g., from Nebius, Jain et al.), filtered via verifiers after generating multiple candidates.
-
Data construction relies on automated pipelines: automated collection scrapes GitHub PRs, extracts CI/CD configs (e.g., GitHub Actions) to build Docker environments, and filters tasks via execution-based checks (e.g., ensuring at least one test transitions from fail to pass). Automated synthesis tools like SWE-Synth, SWE-Smith, and SWE-Mirror generate new tasks by rewriting code, paraphrasing issues, or transplanting bugs into new repos—all validated under shared environments to reduce overhead.
-
Each task is structured as a triple: (D) issue description, (C) codebase at pre-fix commit, and (T) test suite split into F2P (fail-to-pass) and P2P (pass-to-pass) tests. Models generate patches without seeing tests; evaluation applies the patch, runs tests, and scores success if all tests pass. Metadata includes repo owner/name, commit hash, and test specs. Cropping isn’t used; instead, tasks are isolated via git checkout and Dockerized environments to ensure reproducibility.
Method
The authors leverage a comprehensive framework for issue resolution that integrates both training-free and training-based methodologies to synthesize valid code patches. The overall process begins with an input consisting of an issue description, a codebase, and associated tests, which are processed within an environment to generate a patch. The framework is structured to support diverse approaches, including those that operate without model retraining and those that employ supervised or reinforcement learning to enhance model capabilities.
Refer to the framework diagram 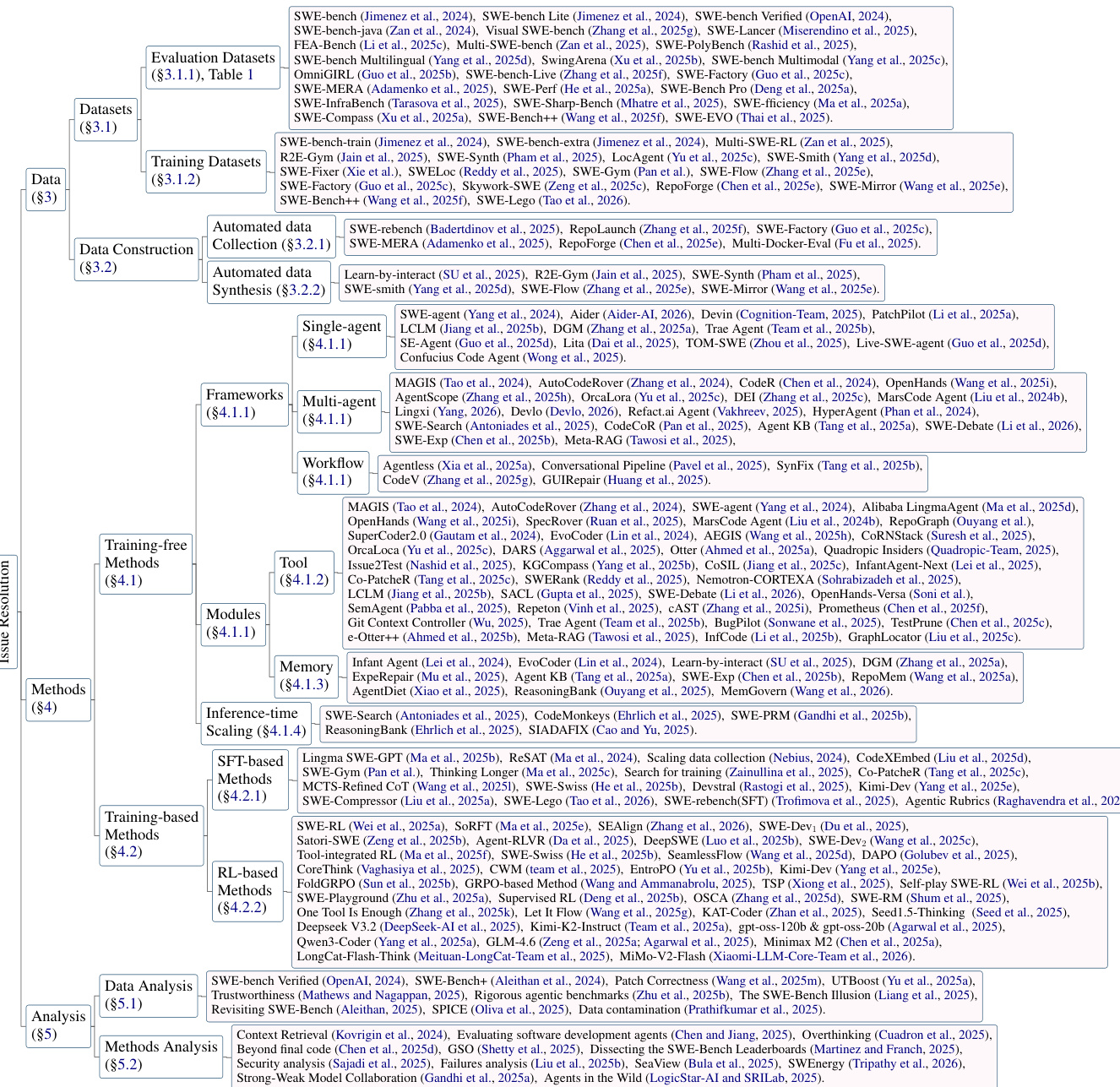 to understand the high-level architecture. This diagram illustrates the core components: the input stage, where the problem statement and codebase are provided; the issue resolution methods, which generate a patch; and the evaluation stage, where the patch is applied and tested. The process is iterative, with the generated patch being evaluated against the test suite to determine resolution success.
to understand the high-level architecture. This diagram illustrates the core components: the input stage, where the problem statement and codebase are provided; the issue resolution methods, which generate a patch; and the evaluation stage, where the patch is applied and tested. The process is iterative, with the generated patch being evaluated against the test suite to determine resolution success.
Training-free methods, as detailed in the taxonomy, rely on external tools and sophisticated prompting to augment the LLM's reasoning without modifying its parameters. These methods are categorized into frameworks, modules, and inference-time scaling strategies. The framework diagram 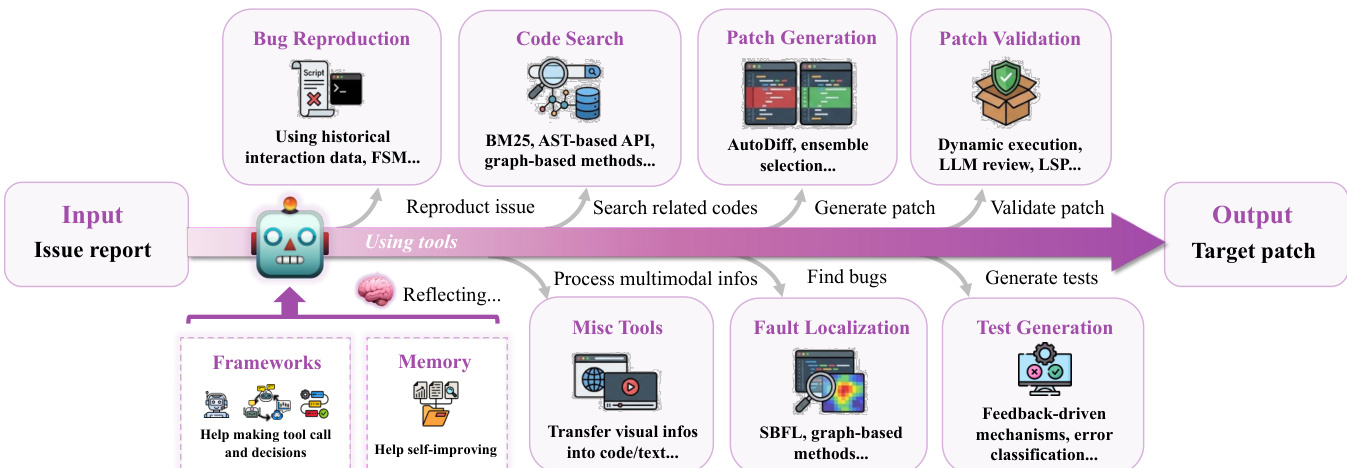 provides a detailed breakdown of the tool modules. These tools are organized according to the standard repair pipeline, starting with bug reproduction, which automates the generation of executable scripts to trigger defects. This is followed by fault localization, where methods like Spectrum-Based Fault Localization (SBFL) and graph-based techniques are used to identify suspicious code regions. Code search tools then retrieve relevant context, employing strategies such as interactive retrieval, graph-based understanding, and dynamic management. Patch generation tools enhance output quality through structured methodologies, including specification inference and robust editing formats. Patch validation tools confirm correctness via dynamic execution or static analysis, while test generation tools create reproduction test cases to validate the resolution.
provides a detailed breakdown of the tool modules. These tools are organized according to the standard repair pipeline, starting with bug reproduction, which automates the generation of executable scripts to trigger defects. This is followed by fault localization, where methods like Spectrum-Based Fault Localization (SBFL) and graph-based techniques are used to identify suspicious code regions. Code search tools then retrieve relevant context, employing strategies such as interactive retrieval, graph-based understanding, and dynamic management. Patch generation tools enhance output quality through structured methodologies, including specification inference and robust editing formats. Patch validation tools confirm correctness via dynamic execution or static analysis, while test generation tools create reproduction test cases to validate the resolution.
Training-based methods, in contrast, enhance the LLM's fundamental programming capabilities through supervised fine-tuning (SFT) and reinforcement learning (RL). SFT-based methods focus on data scaling, curriculum learning, and rejection sampling to adapt the model to software engineering protocols. The SFT process is depicted in the framework diagram 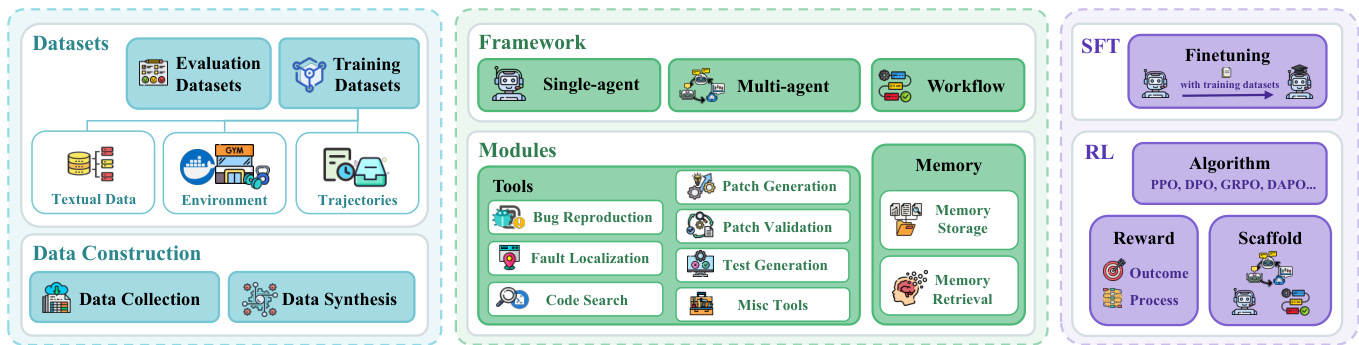 as a finetuning step that uses training datasets. RL-based methods optimize issue resolution strategies through iterative interaction, relying on three core components: the algorithm for policy updates, reward design for guiding exploration, and the scaffold for managing environment rollouts. The algorithm component includes methods like Group Relative Policy Optimization (GRPO), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Reward design incorporates both sparse outcome-based rewards and dense process-oriented signals to provide feedback throughout the reasoning process. The scaffold serves as the inference framework for rollouts, with OpenHands being the most prevalent choice.
as a finetuning step that uses training datasets. RL-based methods optimize issue resolution strategies through iterative interaction, relying on three core components: the algorithm for policy updates, reward design for guiding exploration, and the scaffold for managing environment rollouts. The algorithm component includes methods like Group Relative Policy Optimization (GRPO), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Reward design incorporates both sparse outcome-based rewards and dense process-oriented signals to provide feedback throughout the reasoning process. The scaffold serves as the inference framework for rollouts, with OpenHands being the most prevalent choice.
Experiment
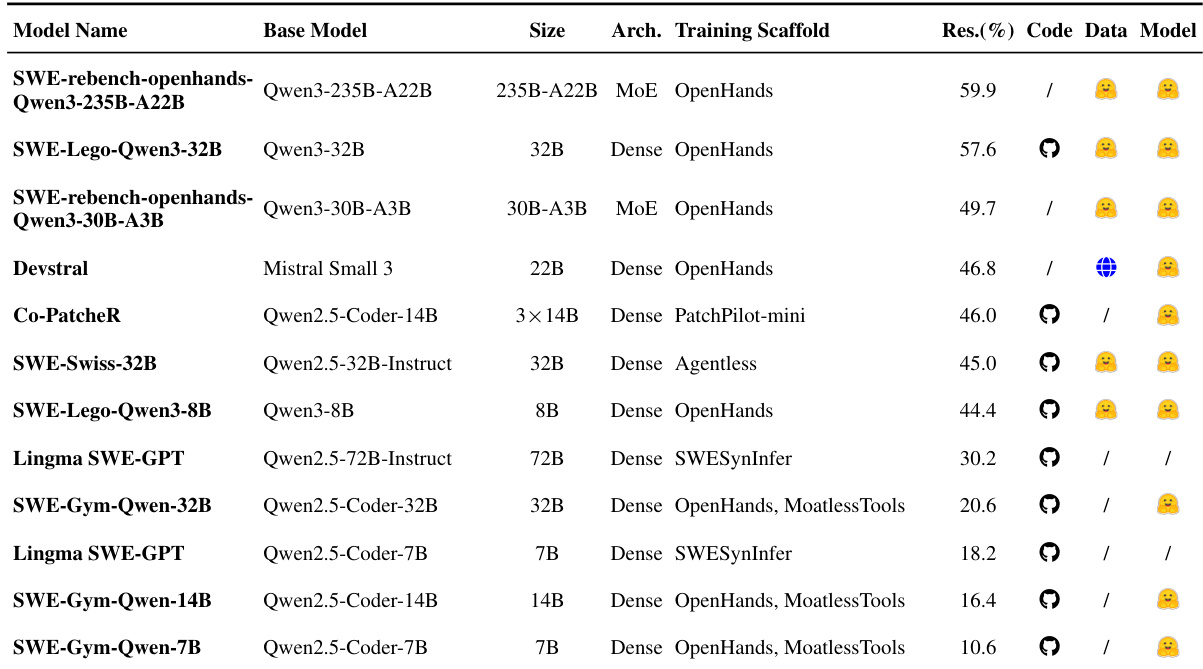
- Table 3 summarizes SFT-based methods for issue resolution, categorizing models by architecture and training scaffold, sorted by performance.
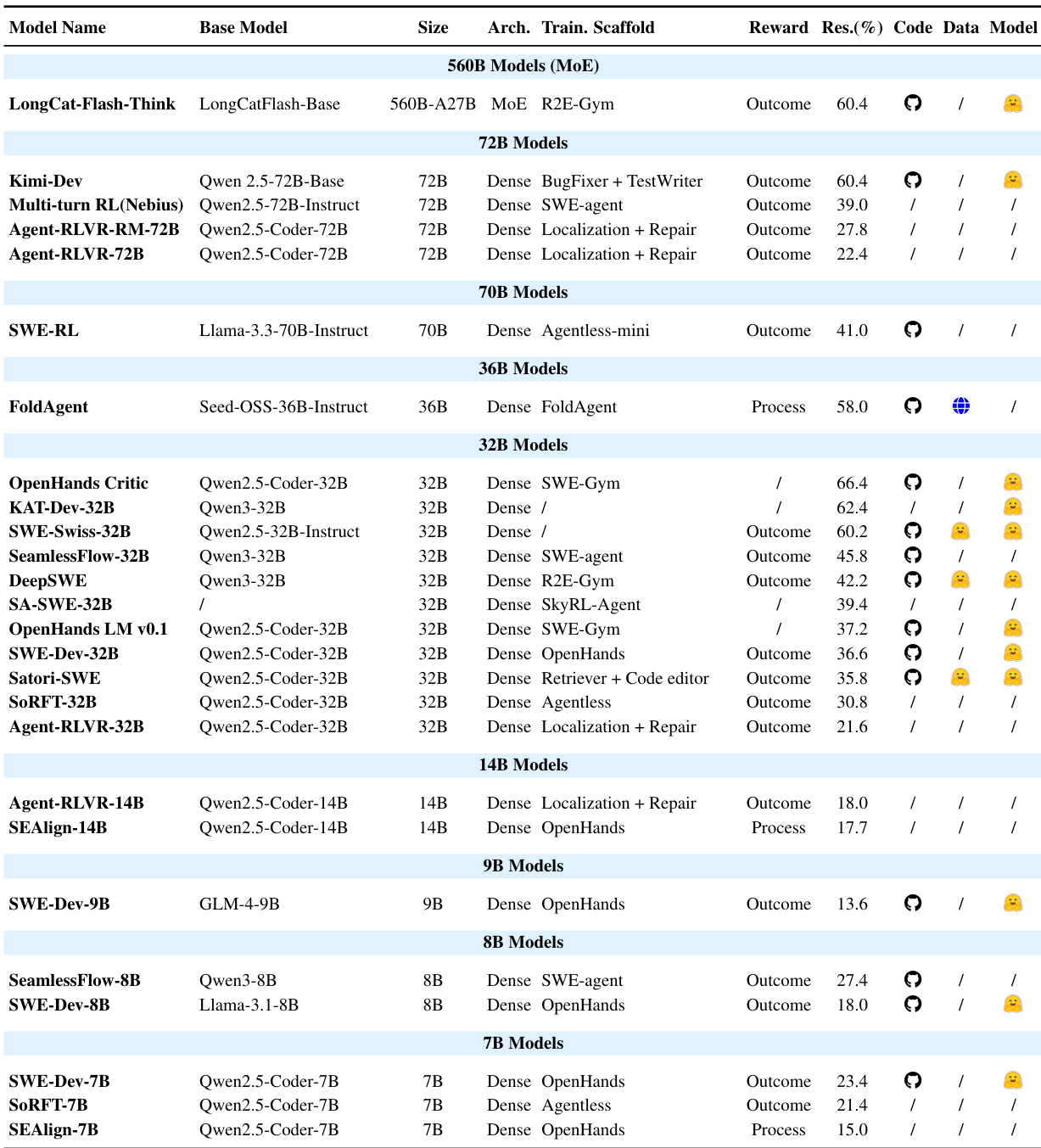
- Table 4 shows specialized models fine-tuned via RL, revealing that smaller dense models (7B–32B) can match larger baselines when using domain-specific rewards; process rewards increasingly supplement sparse outcome rewards to stabilize training on long-horizon tasks.
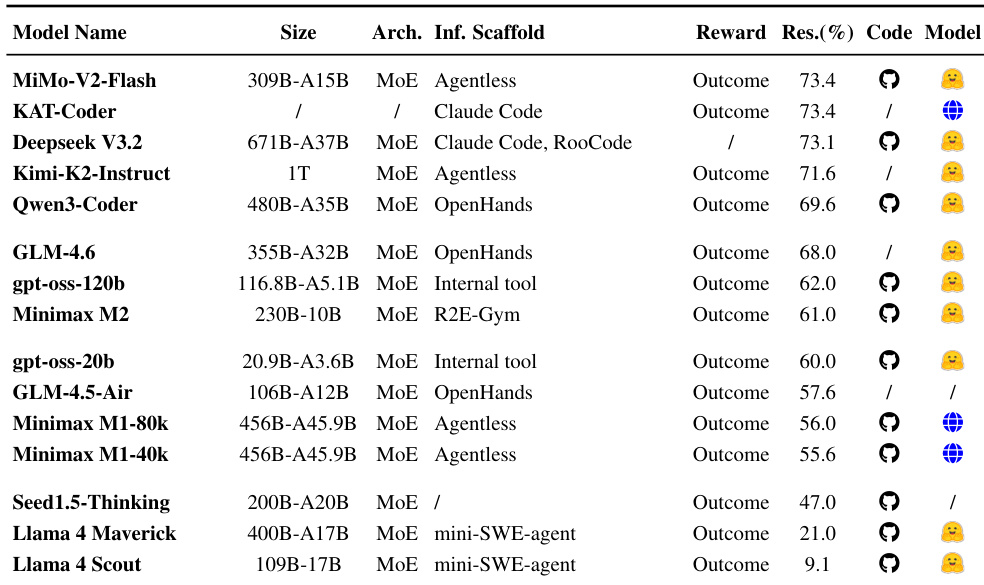
- Table 5 evaluates general-purpose foundation models relying on external inference scaffolds, serving as a control group to highlight performance gains from SFT and RL pipelines in Section 4.2.
The authors use a table to compare various models trained for issue resolution, categorizing them by size and training method. Results show that smaller models like 32B and 7B can achieve competitive performance when optimized with domain-specific rewards, particularly when using dense feedback signals such as process rewards, which help stabilize training for complex tasks.
The authors use a table to compare SFT-based models for issue resolution, categorizing them by architecture, inference scaffold, and reward type. Results show that models using outcome-based rewards and specialized scaffolds achieve higher resolution rates, with MiMo-V2-Flash and KAT-Coder leading at 73.4%, while models relying on general-purpose scaffolds or lacking structured rewards perform significantly worse.
The authors use a variety of SFT-based models to evaluate issue resolution performance, with results showing that larger models like SWE-rebench-openhands-Qwen3-235B-A22B achieve the highest accuracy at 59.9%. The data indicates that model size and training scaffold significantly influence performance, with OpenHands and MoE architectures generally outperforming others, while smaller models like SWE-Gym-Qwen-7B achieve lower results around 10.6%.