Command Palette
Search for a command to run...
ACoT-VLA:視覚言語行動モデルにおけるアクション・チェーン・オブ・シンキング
ACoT-VLA:視覚言語行動モデルにおけるアクション・チェーン・オブ・シンキング
Linqing Zhong Yi Liu Yifei Wei Ziyu Xiong Maoqing Yao Si Liu Guanghui Ren
概要
視覚-言語-行動(Vision-Language-Action; VLA)モデルは、多様な操作タスクに応用可能な汎用的なロボット方策として注目されており、従来は視覚・言語モデル(VLM)の埋め込みを介してマルチモーダル入力を直接行動に変換するアプローチに依存していた。近年では、行動生成をガイドするための明示的な中間的推論が導入され、例えばサブタスク予測(言語)や目標画像の合成(視覚)などが挙げられる。しかしながら、これらの中間推論はしばしば間接的であり、正確な行動実行に必要な細部までを十分に表現する能力に限界がある。そこで本研究では、最も効果的な推論形式は、行動空間そのものにおいて直接的・段階的に検討を行うものであると主張する。これに基づき、行動空間内で構造化された粗い行動意図の系列として推論プロセスを定式化する「Action Chain-of-Thought(ACoT)」という新規パラダイムを提案する。本論文では、このACoTパラダイムを実現する新規アーキテクチャであるACoT-VLAを提案する。具体的には、互いに補完的な2つのモジュールを導入する:明示的行動推論器(Explicit Action Reasoner; EAR)と暗黙的行動推論器(Implicit Action Reasoner; IAR)。EARは明示的な行動レベルの推論ステップとして粗い参照軌道を提案するのに対し、IARはマルチモーダル入力の内部表現から潜在的な行動事前知識を抽出し、両者が協調してACoTを構成することで、下流の行動ヘッドを適切に条件づけ、根拠のある方策学習を可能にする。実環境およびシミュレーション環境における広範な実験の結果、本手法が優れた性能を発揮することが示された。特に、LIBERO、LIBERO-Plus、VLABenchにおいて、それぞれ98.5%、84.1%、47.4%の成功率を達成した。
One-sentence Summary
The authors from Beihang University and AgiBot propose ACoT-VLA, a novel VLA architecture that advances robot policy learning by introducing Action Chain-of-Thought reasoning, where explicit coarse action intents and implicit latent action priors jointly guide precise action generation, outperforming prior methods on LIBERO, LIBERO-Plus, and VLABench benchmarks.
Key Contributions
-
The paper addresses the semantic-kinematic gap in vision-language-action models by introducing Action Chain-of-Thought (ACoT), a novel paradigm that formulates reasoning as a sequence of coarse action intents directly in the action space, enabling more grounded and precise robot policy learning compared to prior language- or vision-based intermediate reasoning.
-
To realize ACoT, the authors propose ACoT-VLA, which integrates two complementary components: an Explicit Action Reasoner (EAR) that generates coarse reference trajectories from multimodal inputs, and an Implicit Action Reasoner (IAR) that infers latent action priors via cross-attention, together providing rich, action-space guidance for policy execution.
-
Extensive experiments across real-world and simulation environments demonstrate the method's effectiveness, achieving state-of-the-art success rates of 98.5%, 84.1%, and 47.4% on LIBERO, LIBERO-Plus, and VLABench benchmarks, respectively.
Introduction
The authors address the challenge of bridging the semantic-kinematic gap in vision-language-action (VLA) models, where high-level, abstract inputs from vision and language fail to provide precise, low-level action guidance for robotic control. Prior approaches rely on reasoning in language or visual spaces—either generating sub-tasks via language chains or simulating future states with world models—both of which offer indirect, suboptimal guidance for action execution. This limits generalization and physical grounding in real-world robotic tasks. To overcome this, the authors introduce Action Chain-of-Thought (ACoT), a novel paradigm that redefines reasoning as a sequence of explicit, kinematically grounded action intents directly in the action space. They propose ACoT-VLA, a unified framework featuring two complementary modules: the Explicit Action Reasoner (EAR), which synthesizes coarse motion trajectories from multimodal inputs, and the Implicit Action Reasoner (IAR), which infers latent action priors via cross-attention between downsampled inputs and learnable queries. This dual mechanism enables direct, rich action-space guidance, significantly improving policy performance. Experiments across simulation and real-world benchmarks demonstrate state-of-the-art results, with success rates of 98.5%, 84.1%, and 47.4% on LIBERO, LIBERO-Plus, and VLABench, respectively.
Dataset

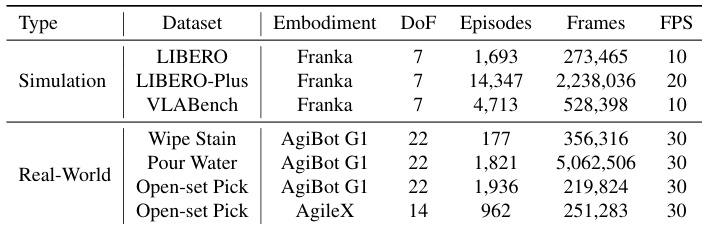
- The dataset comprises three public simulation benchmarks—LIBERO, LIBERO-Plus, and VLABench—and custom-collected real-world data from three tasks: Wipe Stain, Pour Water, and Open-set Pick.
- LIBERO includes 1,693 episodes and 273,465 frames at 10 Hz, featuring uniform trajectory lengths and smooth motion patterns, widely used as a standard benchmark.
- LIBERO-Plus contains 14,347 episodes and 2,238,036 frames at 20 Hz, designed with perturbation-oriented variations in motion magnitude and camera–robot viewpoints to challenge policy generalization under structured distribution shifts.
- VLABench’s training set consists of 4,713 episodes and 528,398 frames at 10 Hz, requiring advanced visual and physical reasoning due to complex task dynamics.
- Real-world data includes 177 episodes (356,316 frames) for Wipe Stain, characterized by dense tool-surface contact and fine-grained force control; 1,821 episodes (5,062,506 frames) for Pour Water, with long-horizon, multi-stage execution; and Open-set Pick with 1,936 episodes (219,824 frames) from AgiBot G1 and 962 episodes (251,283 frames) from AgileX, both featuring diverse tabletop layouts and natural-language instructions.
- The authors use a mixture of these datasets for training, with training splits derived from the full episode collections and mixture ratios adjusted to balance task complexity and scale.
- Data is processed with consistent frame sampling and temporal alignment; for real-world tasks, episodes are filtered to ensure task completion and valid demonstrations.
- No explicit cropping is applied, but visual inputs are standardized to a fixed resolution during training.
- Metadata such as task type, platform, and instruction modality are constructed to support multi-task learning and evaluation.
Method
The authors introduce ACoT-VLA, a novel architecture that implements the Action Chain-of-Thought (ACoT) paradigm by formulating reasoning as a structured sequence of coarse action intents within the action space. The framework is built upon a shared pre-trained Vision-Language Model (VLM) backbone, which processes the natural language instruction and current visual observation to generate a contextual key-value cache. This cache serves as the foundation for two complementary action reasoners: the Explicit Action Reasoner (EAR) and the Implicit Action Reasoner (IAR), which provide distinct forms of action-space guidance. The overall architecture is designed to synergistically integrate these explicit and implicit cues to condition the final action prediction.

As shown in the figure below, the framework consists of three main components operating on features from a shared VLM backbone. The first component, the Explicit Action Reasoner (EAR), is a light-weight transformer module that synthesizes a coarse reference trajectory to provide explicit action-space guidance. The second component, the Implicit Action Reasoner (IAR), employs a cross-attention mechanism with learnable queries to extract latent action priors from the VLM's internal representations. The final component, the Action-Guided Prediction (AGP) head, synergistically integrates both explicit and implicit guidances via cross-attention to condition the final denoising process, producing the executable action sequence.
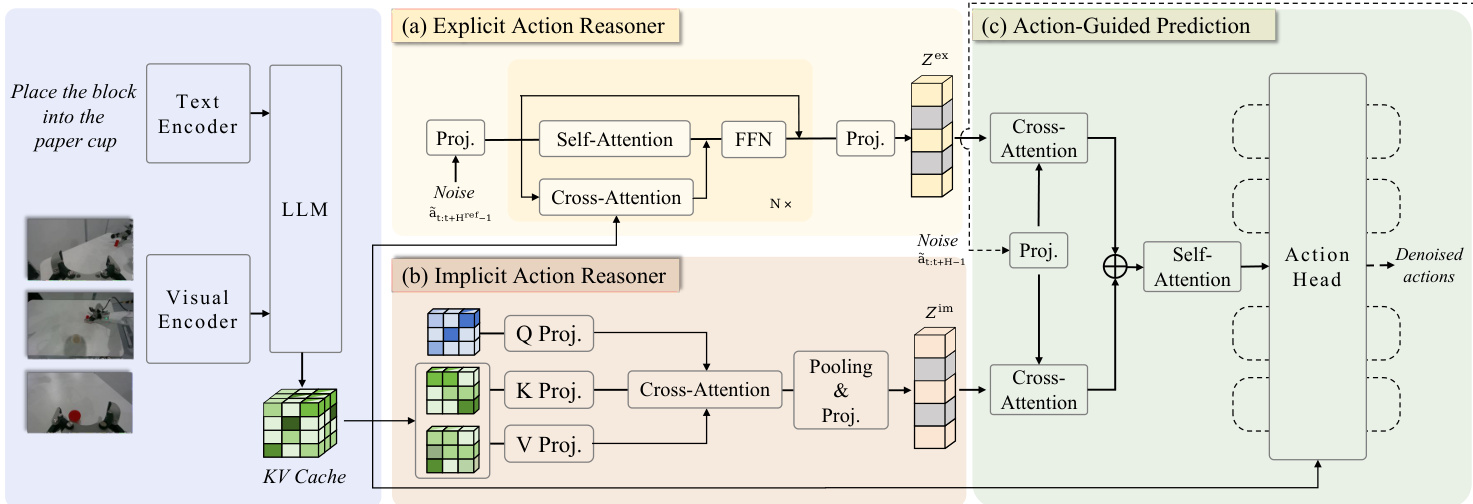
The Explicit Action Reasoner (EAR) operates by taking a noisy action sequence as input and generating a denoised reference action sequence. This process begins with the VLM encoding the instruction and observation into a contextual key-value cache. The EAR, denoted as πθref, then processes the noisy action sequence through a series of transformer layers. At each layer, self-attention captures temporal dependencies within the action sequence, while cross-attention with the VLM's key-value cache injects multimodal contextual priors. The intermediate representation is updated by a feed-forward network in a residual-parallel manner. Through training via flow matching, the EAR learns a distribution over action trajectories, producing a denoised action sequence that is then encoded into an action embedding Zex, serving as explicit action-space guidance.
The Implicit Action Reasoner (IAR) directly operates on the VLM's key-value cache to extract latent action priors. For each VLM layer, a learnable query matrix is initialized, and the corresponding key-value pairs are downsampled into a lower-dimensional space using learnable linear projectors. Cross-attention is then applied to extract action-relevant information from each layer's downsampled key-value pairs. The resulting features are integrated via average pooling and transformed through a MLP projector to produce a compact representation ziim that captures implicit action semantics. By aggregating these representations across all layers, the IAR obtains an implicit action-related feature Zim, which complements the explicit motion priors.
The Action-Guided Prediction (AGP) strategy incorporates both the explicit and implicit action guidances into policy learning. Given a noisy action segment, it is first encoded into a noisy action embedding, which serves as an action query. This query interacts with both Zex and Zim through dual cross-attention operations to retrieve complementary priors. The attended representations, Sex and Sim, are then concatenated and processed through a self-attention fusion block to integrate the priors into a unified representation hˉ. This aggregated representation is finally fed into the action head, which predicts the denoised action sequence. The entire framework is optimized under a standard flow-matching mean-squared error objective, with separate losses for the EAR and the action head.
Experiment
- Evaluated on LIBERO, LIBERO-Plus, and VLABench simulation benchmarks: Achieved state-of-the-art performance, with a 1.6% absolute improvement in average success rate over π₀.₅ on LIBERO, and significant gains under perturbations (e.g., +16.3% on robot initial-state shifts in LIBERO-Plus), demonstrating enhanced robustness and generalization.
- On VLABench, achieved the best results in both Intention Score (IS) and Progress Score (PS), with +12.6% IS and +7.2% PS on the unseen-texture track, highlighting strong resistance to distributional shifts.
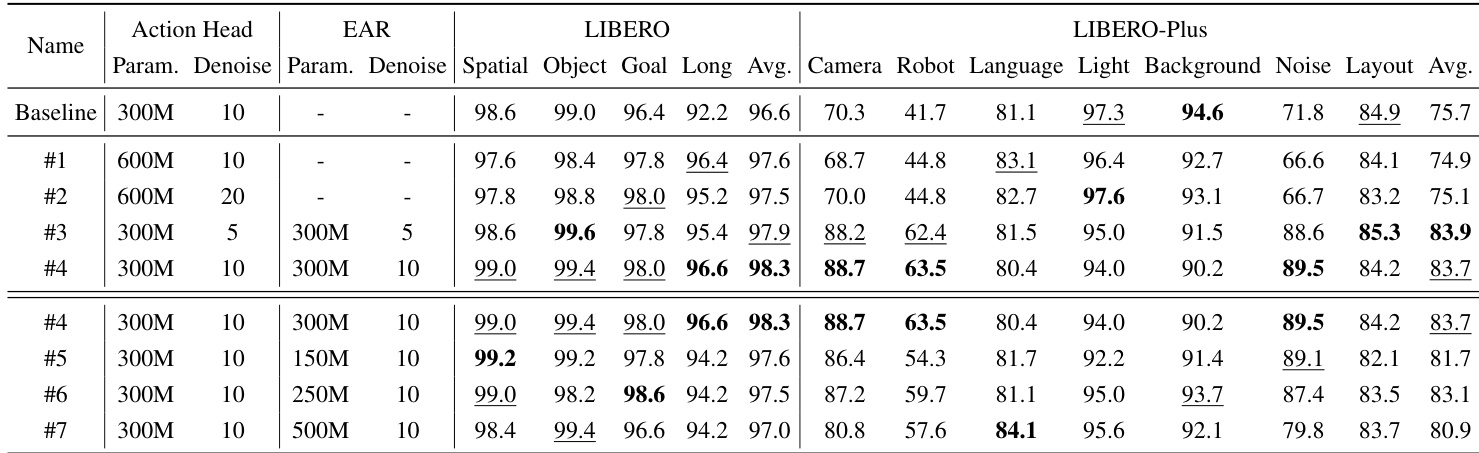
- Ablation studies on LIBERO and LIBERO-Plus confirmed that both Explicit Action Reasoner (EAR) and Implicit Action Reasoner (IAR) modules contribute significantly, with EAR + IAR achieving 98.5% success rate—showing complementary benefits from explicit action guidance and implicit action cues from VLM’s key-value cache.
- Real-world deployment on AgiBot G1 and AgileX robots achieved 66.7% success rate across three tasks (Wipe Stain, Pour Water, Open-set Pick), outperforming π₀.₅ (61.0%) and π₀ (33.8%), validating effectiveness and cross-embodiment adaptability under real sensing and actuation noise.
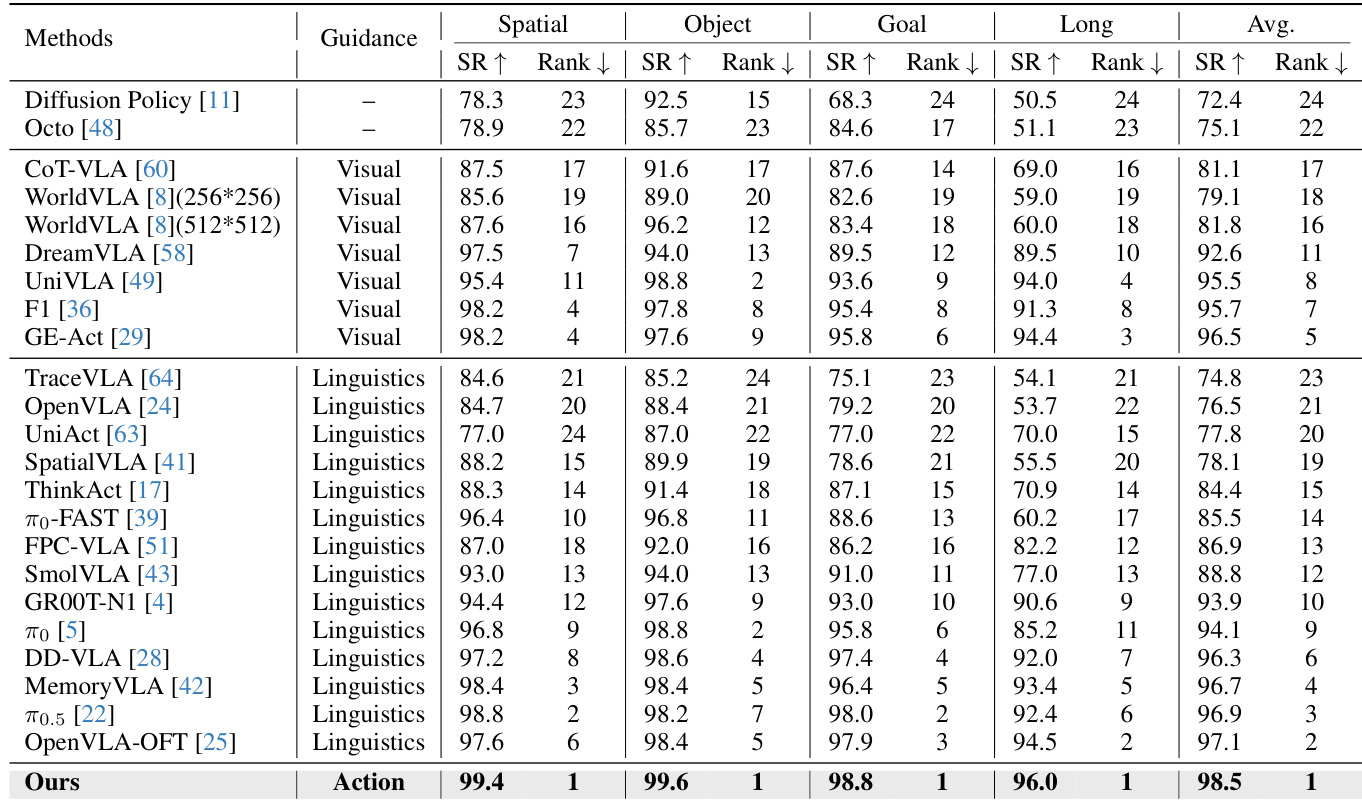
The authors use the LIBERO benchmark to evaluate their approach, comparing it against various state-of-the-art methods across four task suites. Results show that their method achieves the highest average success rate of 98.5%, outperforming all baselines, particularly in the Long-horizon manipulation tasks, where it achieves a 96.0% success rate, demonstrating the effectiveness of action-space guidance.
Results show that the proposed method outperforms the baseline approaches across all evaluation tracks on the VLABench benchmark. The authors achieve the highest average success rate of 63.5% and 47.4% in Intention Score and Progress Score, respectively, demonstrating significant improvements in both in-distribution and out-of-distribution settings.

The authors use a unified training setup across simulation and real-world benchmarks, with varying action horizons and control types depending on the environment. Results show that their approach achieves higher average success rates in real-world tasks compared to baseline methods, demonstrating effectiveness under real-world sensing conditions and adaptability across different robotic embodiments.
The authors use the LIBERO benchmark to evaluate the impact of their proposed modules, showing that adding the Explicit Action Reasoner (EAR) and Implicit Action Reasoner (IAR) improves performance across all task suites. Results show that combining both modules achieves the highest average success rate of 98.5%, with significant gains in the Long-horizon suite, indicating that explicit and implicit action guidance are complementary for robust policy learning.
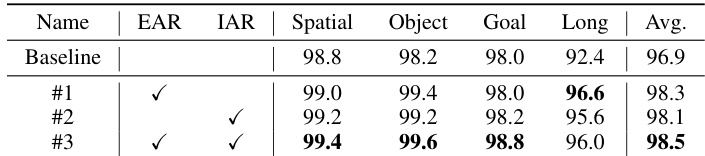
The authors use the LIBERO and LIBERO-Plus benchmarks to evaluate their approach, with results showing that their method consistently outperforms the baseline across all task suites and perturbation conditions. The proposed approach achieves the highest success rates on both benchmarks, particularly excelling in long-horizon tasks and under challenging perturbations such as camera-viewpoint shifts and sensor noise, demonstrating the effectiveness of action-space guidance.