Command Palette
Search for a command to run...
Being-H0.5:クロスエムボディメント一般化のためのヒューマンセントリックロボット学習のスケーリング
Being-H0.5:クロスエムボディメント一般化のためのヒューマンセントリックロボット学習のスケーリング
概要
本稿では、多様なロボットプラットフォームにわたる強固なクロスエムボディメント一般化を実現するための基礎的ビジョン・言語・アクション(VLA)モデル「Being-H0.5」を紹介する。既存のVLAモデルは、形状の多様性(モルフォロジーの異質性)やデータ不足という課題に直面しがちであるが、本研究では人間のインタラクション痕跡を物理的相互作用における普遍的な「母語」として捉える人間中心の学習パラダイムを提案する。これにより、現在までで最大規模のエムボディド事前学習レシピである「UniHand-2.0」を構築した。UniHand-2.0は、30種類の異なるロボットエムボディメントにわたる35,000時間以上のマルチモーダルデータを含む。本アプローチでは、異種のロボット制御を意味的に整合されたスロットにマッピングする「統一アクション空間」を導入し、リソースが限られたロボットが人間のデータからスキルを初期化し、リソース豊富なプラットフォームと協調して学習可能となる。この人間中心の基盤の上に、人間のデモンストレーションとロボットの実行を橋渡しする統一的かつ逐次的なモデリングおよびマルチタスク事前学習パラダイムを設計した。アーキテクチャ的には、共通の運動プリミティブとエムボディメント固有の専門的エキスパートを分離するため、新規の「Mixture-of-Flow(MoF)」フレームワークを備えたMixture-of-Transformers構造を採用している。さらに、現実世界におけるクロスエムボディメントポリシーの安定性を確保するため、感覚的シフトに耐性のある「多様体保存ゲーティング(Manifold-Preserving Gating)」と、異なる遅延および制御特性を持つエムボディメント間でチャンク制御を普遍化する「ユニバーサル非同期チャンキング(Universal Async Chunking)」を導入した。実証実験の結果、Being-H0.5はLIBERO(98.9%)やRoboCasa(53.9%)といったシミュレーションベンチマークにおいて最先端の性能を達成するとともに、5種類の異なるロボットプラットフォームにおいても強力なクロスエムボディメント能力を示した。
One-sentence Summary
The BeingBeyond Team introduces Being-H0.5, a VLA foundation model leveraging UniHand-2.0’s 35,000+ hours of cross-embodiment data and a Unified Action Space to enable robust generalization across diverse robots via human-centric learning, MoF architecture, and real-world stabilization techniques.
Key Contributions
- Being-H0.5 introduces a human-centric learning paradigm that treats human interaction traces as a universal “mother tongue” for physical interaction, enabling cross-embodiment generalization by grounding robotic learning in shared physical priors across 30 diverse robotic platforms via the UniHand-2.0 dataset of 35,000+ hours.
- The model employs a Unified Action Space and Mixture-of-Flow architecture to map heterogeneous robot controls into semantically aligned slots and decouple shared motor primitives from embodiment-specific experts, allowing low-resource robots to bootstrap skills from human and high-resource robot data under a single sequential modeling framework.
- Empirically, Being-H0.5 achieves state-of-the-art performance on simulated benchmarks (LIBERO: 98.9%, RoboCasa: 53.9%) and demonstrates robust real-world cross-embodiment deployment across five distinct robotic platforms, stabilized by Manifold-Preserving Gating and Universal Async Chunking to handle sensory shifts and latency variations.
Introduction
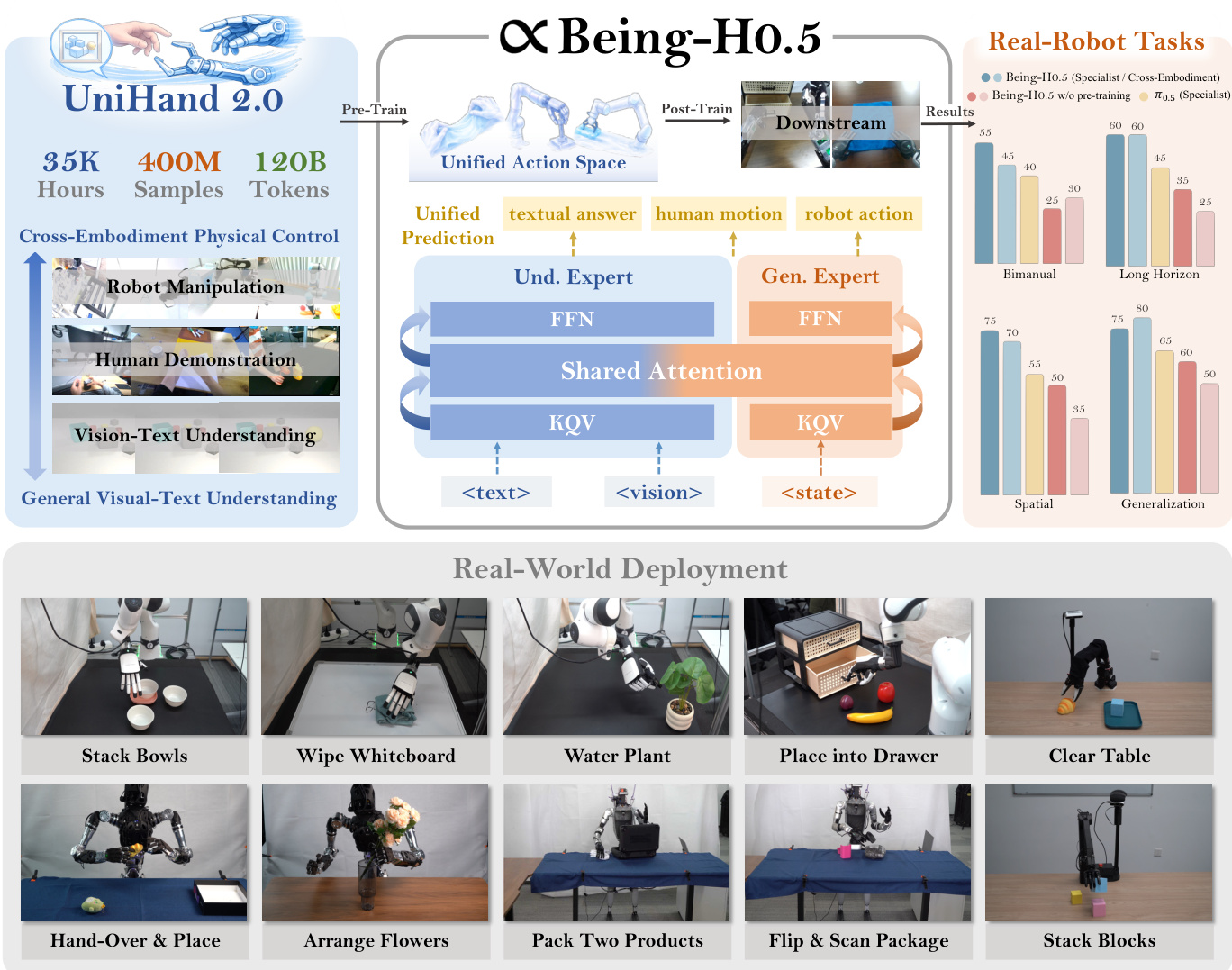
The authors leverage human motion as a universal “mother tongue” to train a single Vision-Language-Action model—Being-H0.5—that generalizes across wildly different robot embodiments, from dexterous hands to humanoid legs. Prior VLAs struggle with embodiment heterogeneity and data scarcity, often failing to transfer skills between platforms or requiring platform-specific heads that ignore shared physical priors. Being-H0.5 overcomes this by introducing UniHand-2.0, a 35,000-hour multimodal corpus spanning 30 robots and human video, unified under a shared action space that maps disparate controls into semantically aligned tokens. Architecturally, it uses a Mixture-of-Flow design with Manifold-Preserving Gating and Universal Async Chunking to stabilize real-time control across varying hardware latencies. The result is a single checkpoint that achieves state-of-the-art performance on simulated benchmarks and successfully deploys on five real robots without retraining.
Dataset

The authors use UniHand-2.0, a large-scale, human-centric pre-training dataset for Vision-Language-Action (VLA) models, composed of 35,000 hours of multimodal data spanning three core domains:
-
Human Demonstration Data (16,000 hours): Sourced from egocentric videos including Ego4D, EPIC-KITCHENS, and Egocentric-10K, plus in-house recordings. Hand poses are estimated using HaWoR with MANO parameters and enriched with Gemini-2.5 for dual-level semantic annotations (per-second instructions and 10-second intent summaries). Data is filtered via a four-stage pipeline: language augmentation via LLMs, motion-quality filtering by confidence and DBA error, manipulation relevance screening, and handedness debiasing via spatial mirroring. This yields 134M samples—100× more than UniHand-1.0.
-
Robot Manipulation Data (14,000 hours): Aggregates 30+ robot embodiments (e.g., Franka, AgiBot G1, Unitree G1) from datasets like OpenX-Embodiment, AgiBot-World, and RoboCOIN. Frames are downsampled to 30% to reduce redundancy. Simulated data is capped at 26% to preserve real-world dominance. Novel demos from platforms like PND Adam-U and BeingBeyond D1 are added for balance. Data includes diverse camera views and control signals, unified into a shared state-action space for training stability.
-
Visual-Text Understanding Data (5,000 equivalent hours): Balances the modality gap by integrating 50.2B textual tokens. Comprises three pillars: (1) general VQA (LLaVA-v1.5, LLaVA-Video), (2) 2D spatial grounding & affordance (RefCOCO, RoboPoint, PixMo-Points), and (3) task planning & reasoning (ShareRobot, EO1.5M-QA). This counters the 1,000:1 visual-to-text token imbalance in robot-only data.
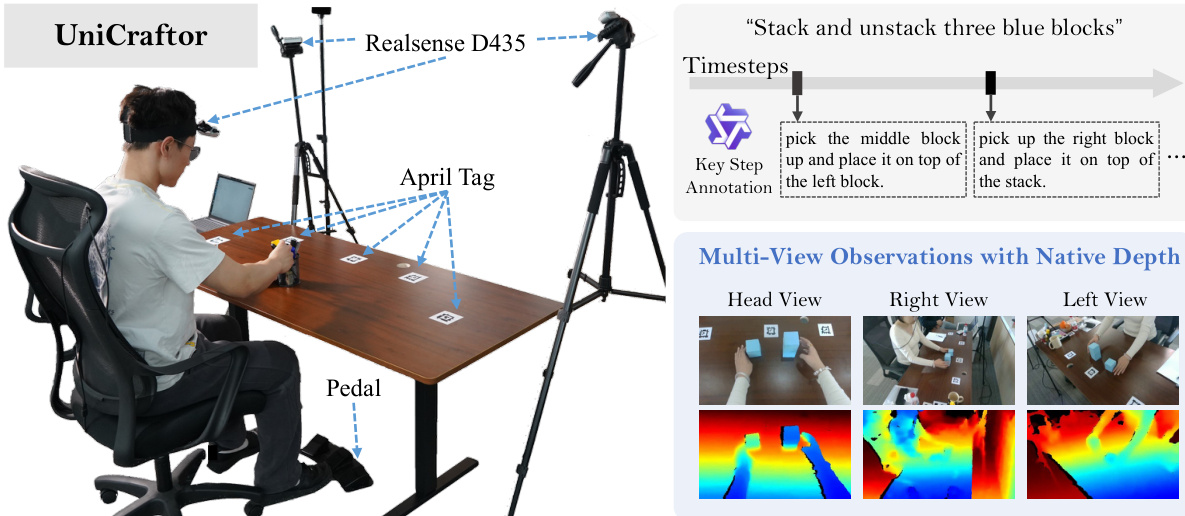
The authors train their model using a balanced mixture: 25.6B tokens from human data, 45.7B from robot data, and 50.2B from VLM data. They employ UniCraftor—a modular data collection system—for high-fidelity in-house recordings, featuring native depth (Intel RealSense), precise camera extrinsics (AprilTags + PnP), and hardware-synced interaction events (foot pedal). Post-processing includes AprilTag inpainting, multi-view motion refinement, and Qwen2.5-VL for event-conditioned descriptions, verified by humans. This ensures clean, synchronized, and semantically grounded supervision for fine-grained policy learning.
Method
The authors leverage a specialized Mixture-of-Transformers (MoT) architecture for Being-H0.5, designed to disentangle high-level semantic reasoning from low-level motor control. This framework integrates two distinct expert modules: a Multimodal Understanding Expert, responsible for interpreting high-dimensional perceptual inputs and generating intermediate subgoals for long-horizon planning, and an Action Generation Expert, which functions as a dedicated policy network translating high-level plans into precise kinematic execution. Both experts operate within a unified MoT backbone, processing a common token sequence and sharing self-attention mechanisms across each transformer layer, which facilitates seamless information flow and ensures action generation is deeply conditioned on visual-semantic context. The model's backbone is initialized from InternVL-3.5, a decoder-only transformer, chosen for its proven performance on complex visual reasoning tasks. The overall architecture is designed to balance semantic comprehension with continuous control, aligning with recent state-of-the-art models.
The model employs a hybrid generation paradigm tailored to the modalities of its output. For textual outputs, such as high-level reasoning and motion descriptions, it uses the standard next-token-prediction paradigm, which leverages the established effectiveness of vision-language models to produce coherent, logically structured instructional chains. For discrete hand motion, a masked token prediction criterion is adopted. For action prediction, the model departs from discrete tokenization and instead uses the Rectified Flow method, which generates smooth, high-fidelity multimodal distributions over the continuous action space, aligning with cutting-edge diffusion-based VLA approaches.
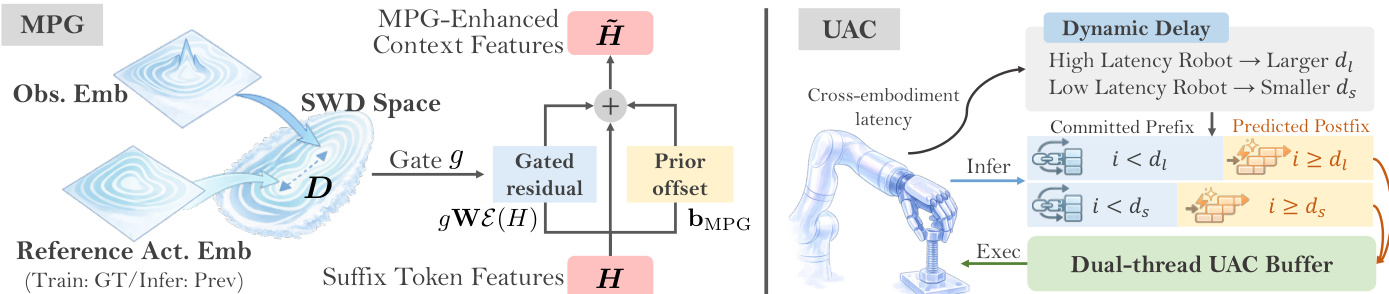
To address the heterogeneity of multi-source embodiment data, the authors introduce a physically interpretable unified state-action space. This space formalizes both state and action as fixed-length, high-dimensional vectors structured by physical semantic alignment. The vector space is partitioned into semantically isolated subspaces, where each dimension corresponds to a grounded physical quantity such as bimanual end-effector poses, joint positions, gripper width, or mobile base velocity. A critical innovation is the treatment of human hand motion as a generalized embodiment, where parameters from the MANO hand model are mapped directly into this unified space. The global wrist pose of the human hand is aligned with the robotic end-effector subspace, while finger articulations are mapped to reserved "fine-manipulation" slots. This ensures that distinct degrees of freedom do not conflict, allowing the model to learn a shared, embodiment-agnostic latent representation of manipulation logic. To guarantee transferability, the space enforces strict standardization: Cartesian control actions are expressed as relative delta displacements in a unified world coordinate frame, rotations are uniformly parameterized using Axis-Angle notation, and joint positions are standardized as absolute radian values. The model preserves raw physical magnitudes rather than applying statistical normalization, forcing it to learn the true physical scale of actions.

To overcome the limited capacity of conventional action experts, the authors introduce a Mixture of Flow (MoF) framework. This scalable architecture decouples distinct embodiments and skills while leveraging a shared foundational representation. The action expert is structured into a two-tiered hierarchy: Foundation Experts (Shared Dynamics) and Specialized Experts (Embodiment & Task Routing). The initial layers of the action expert consist of standard transformer blocks shared across all inputs, encoding fundamental, transferable motor primitives like reaching and grasping. The upper layers utilize a suite of parallel, specialized experts managed by a learnable gating network, inspired by Mixture-of-Experts (MoE) architectures. For a given input state and instruction, the router dynamically activates a sparse subset of experts, facilitating efficient specialization without a linear increase in computational overhead. This architectural sparsity is fundamental to the efficiency and robustness of Being-H0.5, allowing it to synthesize refined foundation primitives into complex, task-specific behaviors without cross-task interference.
The learning framework is built around a unified sequence modeling problem, where all supervision is cast into a single multimodal sequence. Each embodiment is projected into the unified space via sparse slot assignments, allowing human hand motion and robot trajectories to co-exist with vision and language. Each training sample is serialized into a token stream composed of modality segments, with the modality set defined as {vision, text, state, action}. The data is organized into a Query-Answer format, where the model is conditioned on the context and optimized via a generative loss exclusively on the response. The pre-training is fundamentally human-centric, using the UniHand-2.0 dataset as its cornerstone, which provides large-scale egocentric human data for behavioral intent and high-fidelity robot trajectories for kinematic supervision. This integration of VQA signals injects broad vision-language context, enhancing scene understanding and enabling the model to perceive with the nuance of a VLM while executing with precise action.
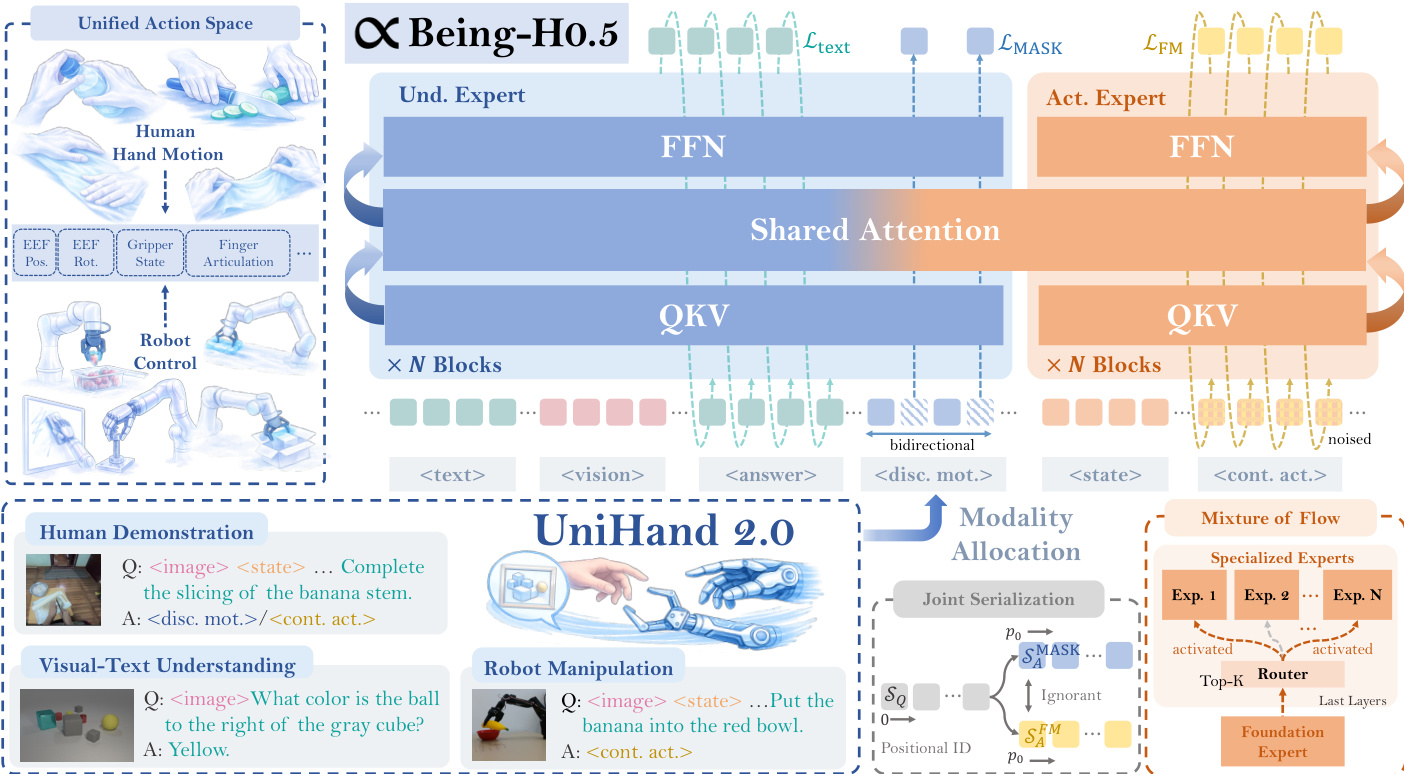
The human-centric multi-task objective includes motion generation as the primary objective, where the model predicts an action chunk conditioned on vision, text, and state. This is complemented by motion description and continuation as alignment objectives to strengthen vision-language-motion grounding and temporal coherence. The joint loss function combines a text loss and an action loss, with token-level index sets identifying segments subject to each loss term. For motion generation and continuation, the action tokens are supervised using a dedicated action loss, which is formulated as a weighted combination of Continuous Flow-Matching and discrete Masked Motion Prediction. Continuous Flow-Matching models the continuous motion distribution using a time-conditioned velocity field, minimizing the mean squared error between the predicted velocity and the ideal vector field. Masked Motion Token Prediction supervises the discrete channel to instill a stable abstraction of motion primitives, where the model reconstructs original codebook indices from a masked token sequence. To achieve seamless integration, the model serializes the context and hybrid targets into a unified sequence, with a modified attention mask ensuring mutual invisibility between the continuous and discrete target segments and aligned positional indices to ground both representations to an identical contextual origin.
Experiment
- Evaluated Being-H0.5 across five real robots with diverse morphologies and 10 tasks; validated spatial, long-horizon, bimanual, and cross-embodiment generalization capabilities.
- Being-H0.5-generalist (single checkpoint) matched specialist performance closely on most categories, notably outperforming specialist in overlap-heavy settings; achieved embodiment-level zero-shot transfer on Adam-U for unseen tasks.
- Outperformed π₀.₅ significantly, especially on long-horizon and bimanual tasks, due to unified state-action space and cross-embodiment design.
- UniHand-2.0 pretraining proved essential for generalist performance; scratch ablation failed to generalize across embodiments.
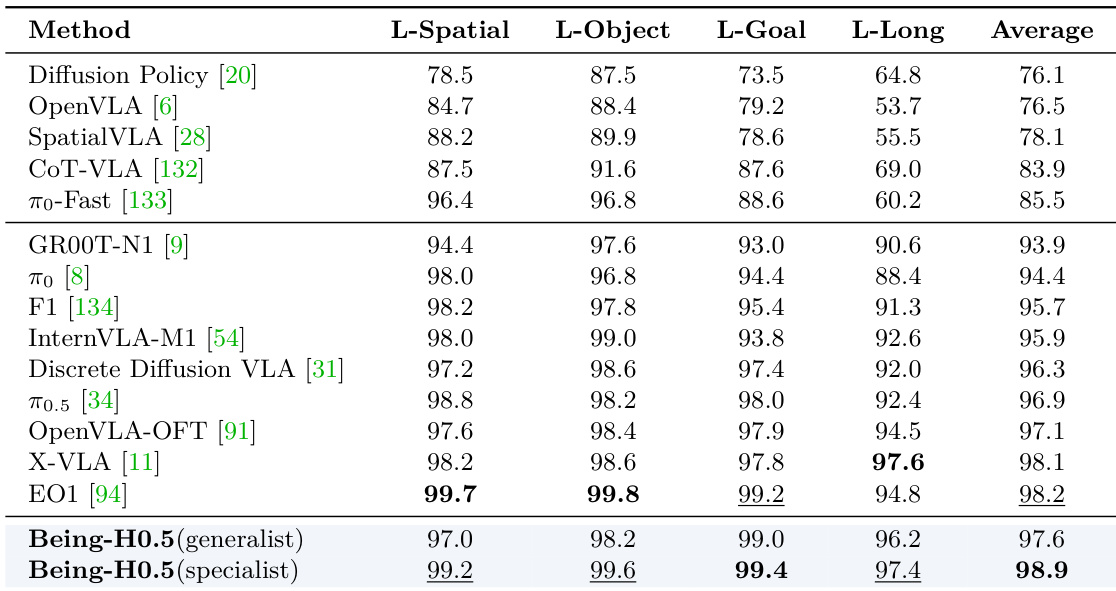
- On LIBERO, Being-H0.5-specialist achieved 98.9% average success (97.4% on LIBERO-Long); generalist (joint LIBERO+RoboCasa) reached 97.6%, showing minimal performance drop.
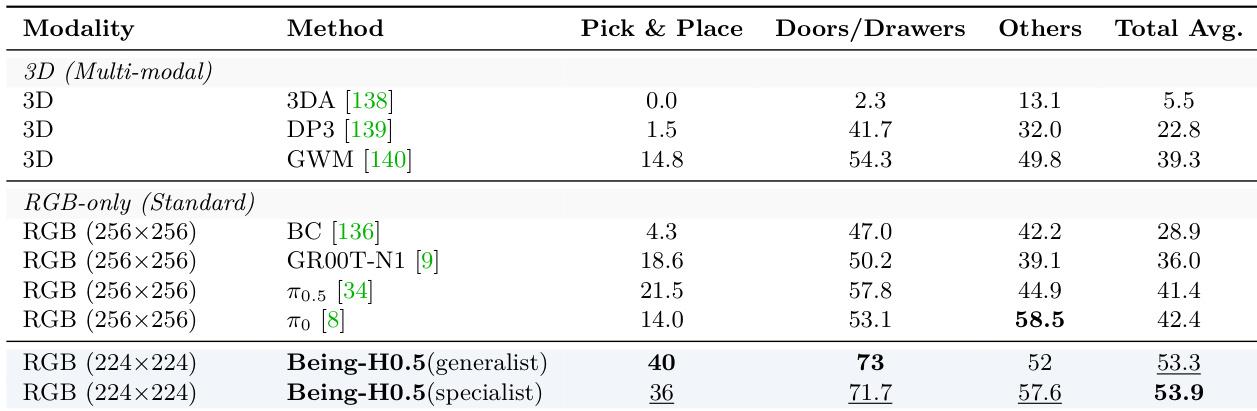
- On RoboCasa, Being-H0.5 set new SOTA: 53.9% (specialist) and 53.3% (generalist), surpassing 3D-based and multi-modal baselines despite using only RGB inputs.
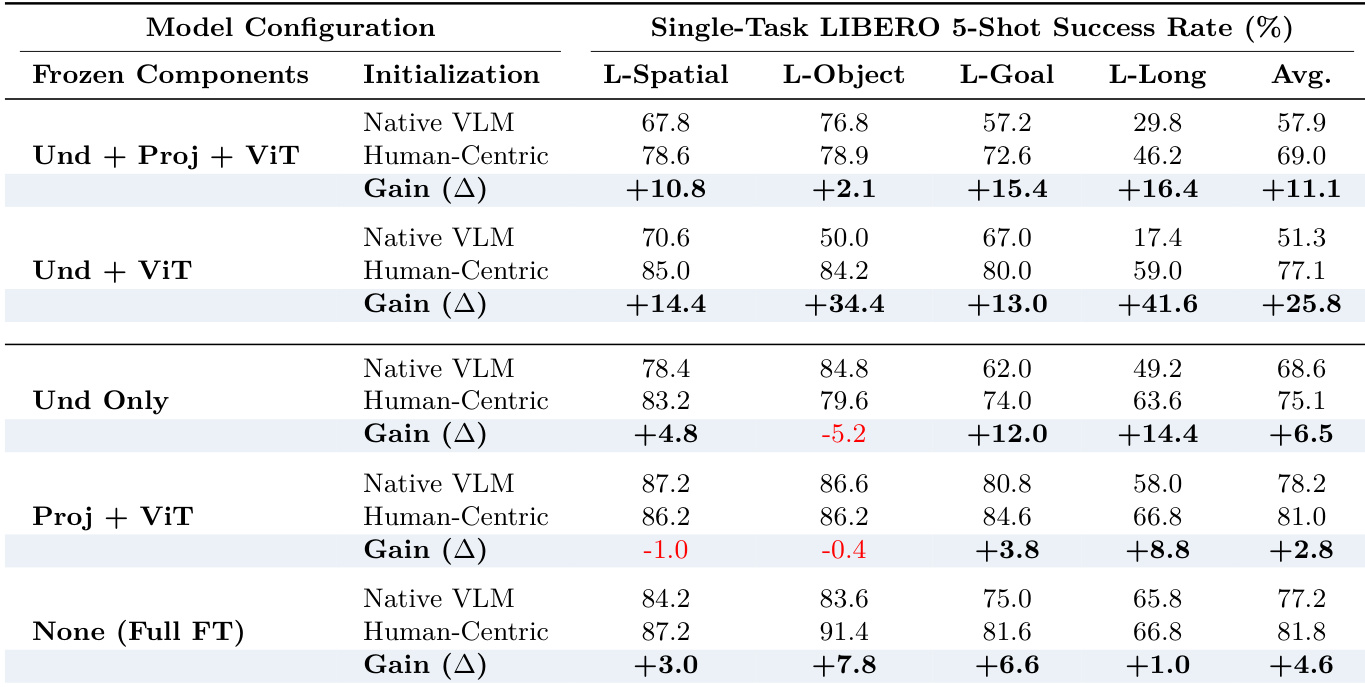
- Human-centric pretraining boosted few-shot adaptation: +25.8% avg gain when freezing backbone; +41.6% on LIBERO-Long, confirming its role in grounding long-horizon intent.
- Masked Motion Token Prediction improved motion intent alignment (MWDS ↑), especially on noisy, in-the-wild data.
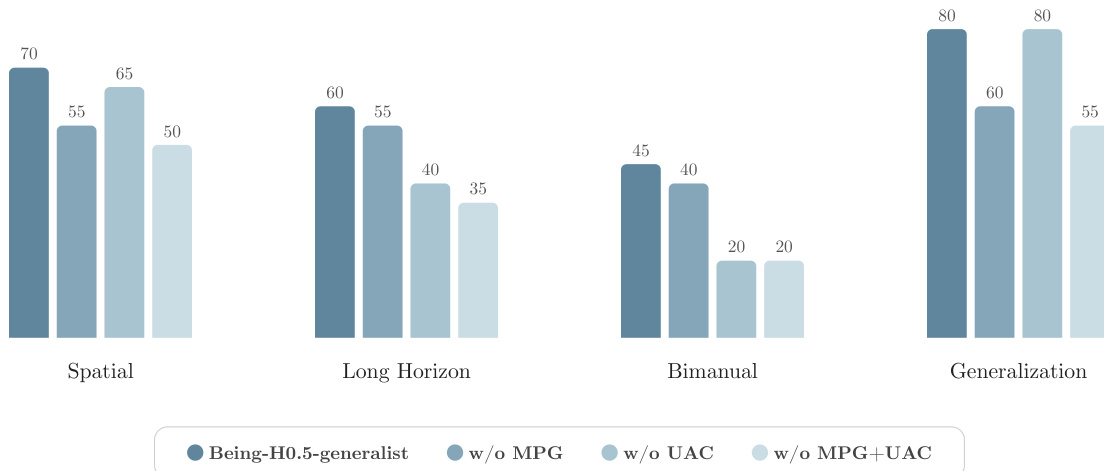
- Disabling MPG+UAC degraded real-time performance most severely on long-horizon and bimanual tasks due to error accumulation and loss of temporal stability.
Results show that Being-H0.5 specialist achieves the highest average success rate of 98.9%, outperforming all other methods across all task categories, particularly excelling in long-horizon tasks with a 97.4% success rate. Being-H0.5 generalist also performs strongly, achieving a 97.6% average, demonstrating that a single checkpoint can maintain high performance across diverse tasks while enabling cross-embodiment generalization.
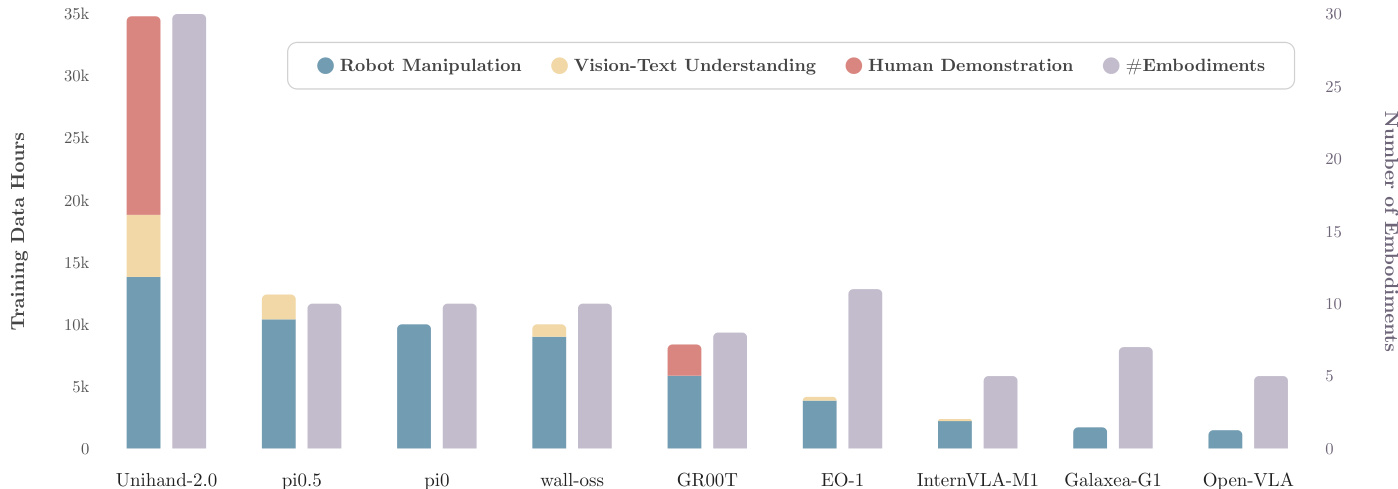
The authors use a bar chart to compare the scale of training data across different models, showing that UniHand-2.0 has the largest training data volume, with over 35,000 robot manipulation hours and 20,000 human demonstration hours, while also supporting the most embodiments. In contrast, models like pi0.5 and pi0 have significantly less robot manipulation data and fewer supported embodiments, indicating a trade-off between data scale and embodiment coverage.
The authors compare Being-H0.5 against various methods on the RoboCasa benchmark, evaluating both specialist and generalist training regimes. Results show that Being-H0.5 achieves state-of-the-art performance, with the generalist variant reaching 53.3% success and the specialist variant achieving 53.9%, outperforming prior methods that use 3D inputs or are based on RGB-only observations.
The authors analyze the impact of human-centric pretraining on downstream adaptation in a single-task 5-shot setting, showing that initializing with human-centric weights leads to significant gains across all task categories, particularly in long-horizon tasks. When the core reasoning components (Und + ViT) are frozen, the pretrained model achieves a +25.8% average improvement over the baseline, indicating that pretraining provides strong foundational priors that reduce overfitting and enhance generalization under limited data.
The authors use a real-robot evaluation to assess the performance of Being-H0.5 across four task categories: Spatial, Long Horizon, Bimanual, and Generalization. Results show that the Being-H0.5-generalist model achieves high success rates in all categories, with the highest performance in Generalization (80%), followed by Spatial (70%), Long Horizon (60%), and Bimanual (45%). Removing the MPG and UAC components significantly degrades performance, especially in Long Horizon and Bimanual tasks, indicating their critical role in maintaining robustness during complex, asynchronous, and coordinated manipulations.