Command Palette
Search for a command to run...
LumosX: 個別化ビデオ生成のための、任意のアイデンティティとその属性との関連付け
LumosX: 個別化ビデオ生成のための、任意のアイデンティティとその属性との関連付け
Jiazheng Xing Fei Du Hangjie Yuan Pengwei Liu Hongbin Xu Hai Ci Ruigang Niu Weihua Chen Fan Wang Yong Liu
概要
拡散モデルの最近の進展により、テキストから動画への生成が大幅に向上し、前景および背景要素に対する微細な制御を備えたパーソナライズされたコンテンツ作成が可能となりました。しかし、複数の被写体間における顔属性の正確な整合性確保は依然として課題であり、既存手法には群内一貫性を保証する明示的なメカニズムが欠如しています。このギャップを埋めるためには、明示的なモデリング戦略と顔属性を考慮したデータ資源の両方が必要です。そこで我々は、データとモデル設計の両面を進展させるフレームワーク「LumosX」を提案します。データ面では、独立した動画からキャプションと視覚的手がかりを調整する専用収集パイプラインを構築し、マルチモーダル大規模言語モデル(MLLMs)を用いて被写体固有の依存関係を推論・割り当てます。これにより抽出された関係性事前知識が、より微細な構造を付与し、パーソナライズされた動画生成の表現制御を強化するとともに、包括的なベンチマークの構築を可能にします。モデリング面では、関係性自己注意(Relational Self-Attention)と関係性交叉注意(Relational Cross-Attention)を組み合わせ、位置情報を意識した埋め込みと洗練された注意動力学を統合することで、被写体と属性の明示的な依存関係をモデル化します。これにより、群内の統制された結束を強制し、異なる被写体クラスター間の分離を強化します。本ベンチマークにおける包括的な評価により、LumosX が微細で、同一性を維持し、意味的に整合したパーソナライズされた複数被写体動画生成において最先端(state-of-the-art)のパフォーマンスを達成することを示しました。コードおよびモデルは https://jiazheng-xing.github.io/lumosx-home/ で公開されています。
One-sentence Summary
Researchers from Zhejiang University, DAMO Academy, and the National University of Singapore propose LumosX, a framework that employs Relational Self-Attention and Cross-Attention to explicitly bind faces with attributes, overcoming prior misalignment issues in personalized multi-subject video generation.
Key Contributions
- The paper introduces a data collection pipeline that leverages multimodal large language models to infer and assign subject-specific dependencies, creating a comprehensive benchmark with explicit face-attribute correspondences for personalized video generation.
- A novel framework named LumosX is presented, which integrates Relational Self-Attention and Relational Cross-Attention modules to explicitly bind identities with their attributes through position-aware embeddings and refined attention dynamics.
- Extensive evaluations on the constructed benchmark demonstrate that the method achieves state-of-the-art performance in fine-grained, identity-consistent, and semantically aligned multi-subject video generation.
Introduction
Diffusion models have revolutionized text-to-video generation, enabling applications like virtual production and e-commerce that require fine-grained control over multiple interacting subjects. However, existing methods struggle to maintain precise alignment between specific faces and their attributes across different characters, often resulting in attribute entanglement or identity confusion when handling complex multi-subject prompts. To address this, the authors introduce LumosX, a framework that combines a new data pipeline using Multimodal Large Language Models to infer explicit subject-attribute dependencies with a novel architecture featuring Relational Self-Attention and Relational Cross-Attention modules. These components explicitly bind identities to their attributes, enforcing intra-group consistency while suppressing interference between distinct subjects to achieve state-of-the-art personalized video generation.
Dataset
-
Dataset Composition and Sources: The authors construct the training dataset and inference benchmark from the Panda70M repository, applying rigorous cleaning and processing to yield 1.57M high-quality video samples. The final collection includes 1.31M single-subject, 0.23M two-subject, and 0.03M three-subject videos, while the benchmark consists of 500 curated YouTube videos split across similar subject counts.
-
Key Filtering and Cleaning Rules: To ensure visual and semantic quality, the pipeline removes videos with subtitles, black-and-white borders, or grayscale content. The authors retain only samples with a QAlign quality score above 3.5, an aesthetic score exceeding 2.0, and motion flow strength between 0.05 and 2.0. Videos containing more than three detected individuals are excluded, and duplicates are removed via VideoCLIP embedding clustering.
-
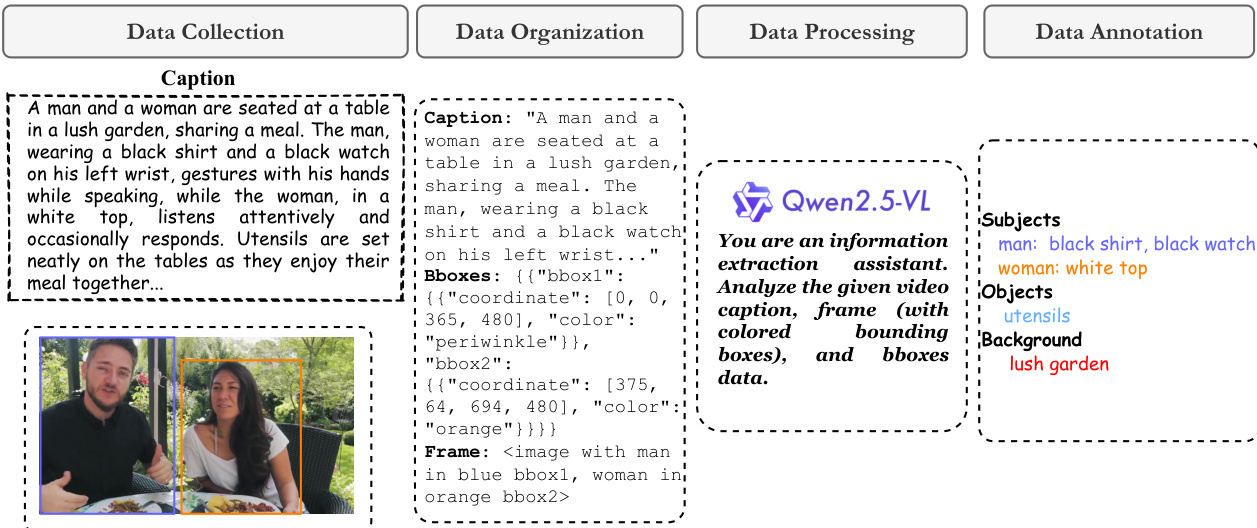
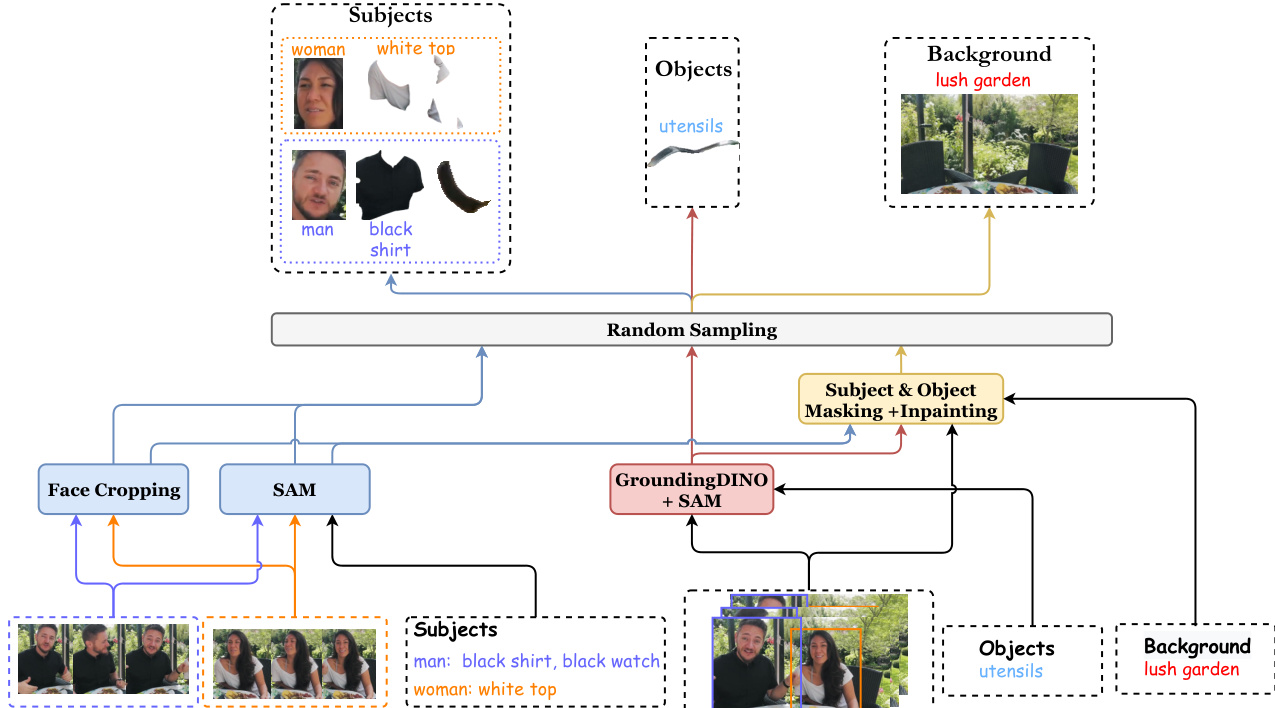
Data Processing and Condition Image Construction: The authors replace original captions with richer descriptions generated by the VILA model and sample three key frames at 5%, 50%, and 95% positions. They employ Qwen2.5-VL to retrieve entity words and match face attributes, using human detection to distinguish multiple subjects. Condition images are derived by cropping faces, segmenting attributes with SAM, isolating objects via GroundingDINO and SAM, and generating clean backgrounds using FLUX inpainting. One valid condition image per entity is randomly selected from the three key frames to ensure diversity and align with the single-reference inference setup.
-
Training Strategy and Mixture: The model is fine-tuned from the Wan2.1 T2V architecture in two phases: 15k iterations on single-subject data followed by 16k iterations on mixed multi-subject data. Each training clip contains 81 frames at 480p resolution. The authors apply numerical and geometric augmentations to subject and object reference images, while background images receive only numerical transformations. During inference, the system supports up to three attributes per subject to maintain consistency with the training distribution.
Method
The authors propose LumosX, a novel framework designed for personalized multi-subject video generation that explicitly models face-attribute dependencies. The system enables the creation of fine-grained, identity-consistent videos from text and image conditions. Refer to the framework diagram for an overview of the generation capabilities.

To address the lack of annotated data tailored for multi-subject generation, the authors develop a data collection pipeline that supports open-set entities with subject-specific dependencies. This pipeline extracts captions and foreground-background condition images with explicit face-attribute dependencies from independent videos. As shown in the figure below, the process involves video frame extraction, caption generation, human detection, and entity matching.
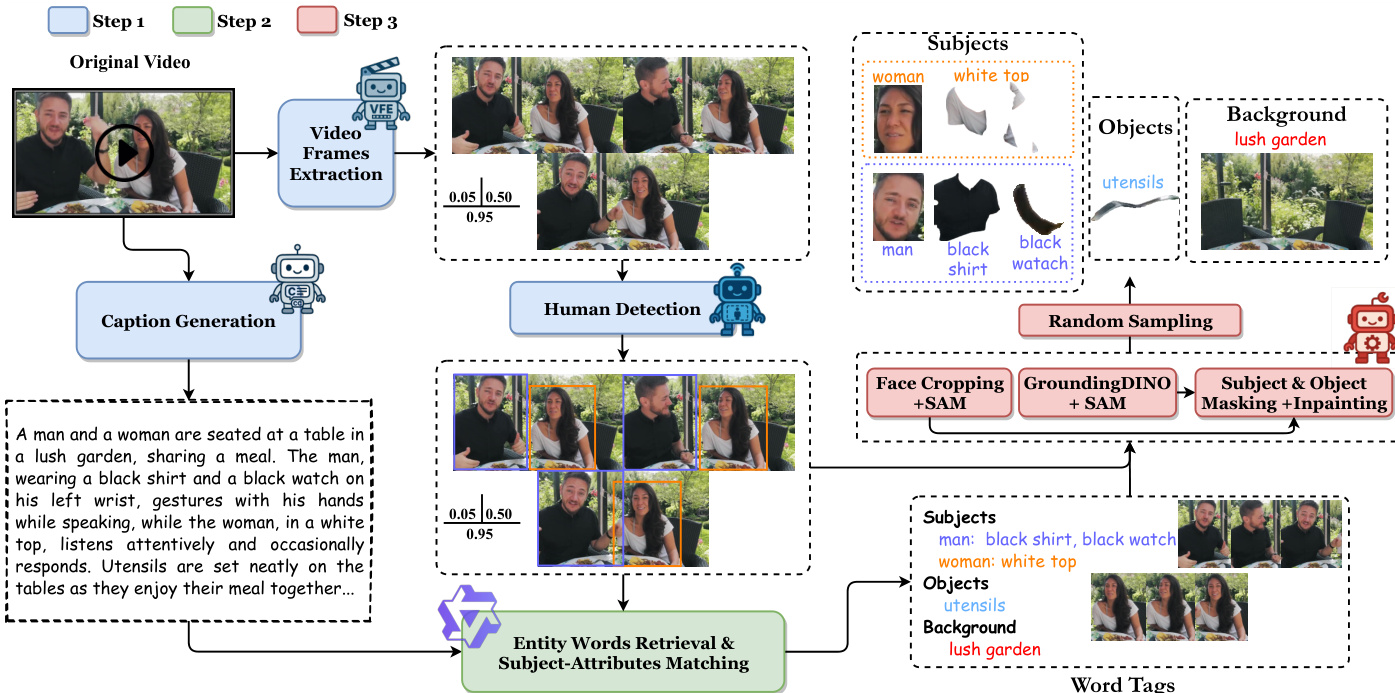
For entity words retrieval and subject-attribute matching, the system utilizes Qwen2.5-VL. The model analyzes the video caption, frame with bounding boxes, and bbox data to extract key entity words and categorize them into subjects, objects, and background.
Subsequently, the system acquires condition images for subjects, objects, and the background. This involves face cropping, grounding, and masking to produce clean background images.
The framework builds on the text-to-video model Wan2.1. All condition images are encoded into image tokens via a VAE encoder, concatenated with denoising video tokens, and fed into DiT blocks. Within each block, the authors introduce Relational Self-Attention and Relational Cross-Attention. Refer to the framework diagram for the detailed architecture.
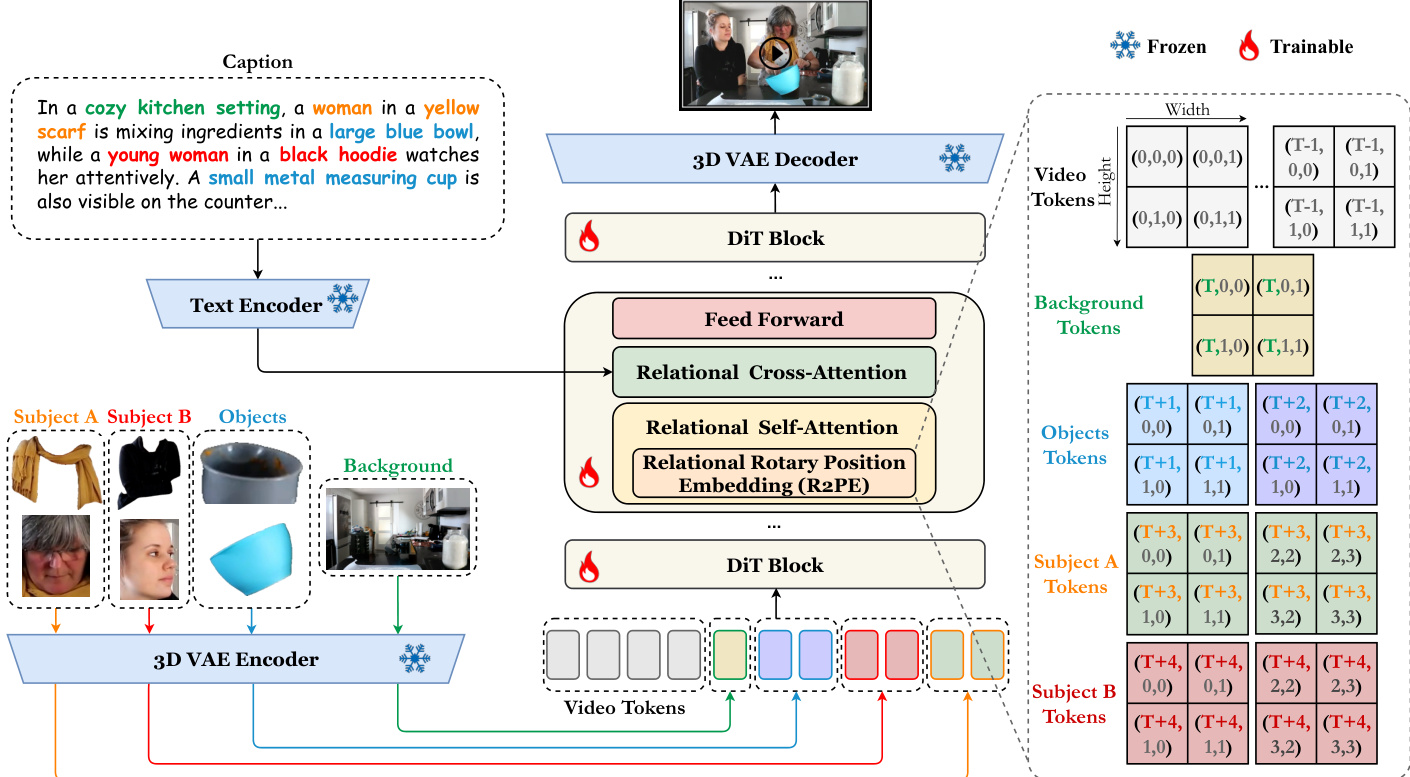
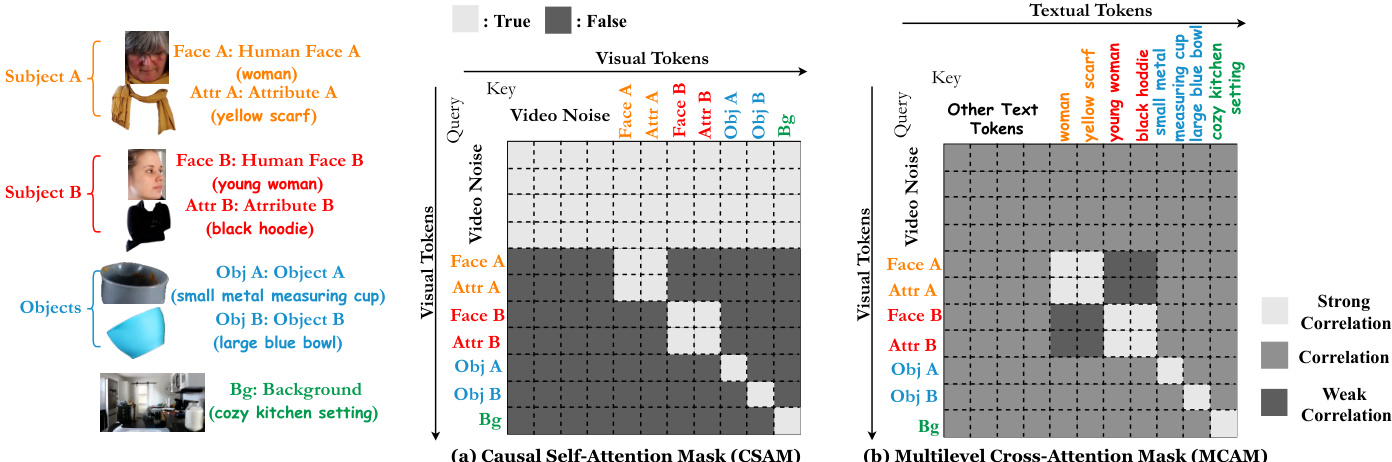
To support spatio-temporal and causal conditional modeling, the authors introduce Relational Self-Attention with Relational Rotary Position Embedding (R2PE) and a Causal Self-Attention Mask (CSAM). Additionally, Relational Cross-Attention with a Multilevel Cross-Attention Mask (MCAM) incorporates textual conditions and aligns face-attribute relationships. As shown in the figure below, the attention mask design includes CSAM and MCAM.
The model is trained using Flow Matching. The objective is to estimate the velocity field between a random noise and the video latent representation. The training objective is defined as the Mean Squared Error between the predicted velocity and the ground-truth velocity.
Experiment
- Main experiments compare LumosX against baselines like ConsisID, SkyReels-A2, and Phantom for identity-consistent and subject-consistent video generation, validating that LumosX achieves superior state-of-the-art performance in preserving facial identity and accurately matching faces with specific attributes across single and multi-subject scenarios.
- Ablation studies confirm that the R2PE, CSAM, and MCAM modules are critical for binding faces to attributes and preventing character confusion, with MCAM showing optimal balance between identity consistency and video quality at a specific hyperparameter setting.
- Extended evaluations demonstrate that LumosX maintains robust performance even when handling four or more subjects without retraining, outperforms image-personalization-based pipelines in facial consistency, and relies on high-quality background inpainting to ensure realistic video generation.
- Human studies and temporal coherence assessments further verify that the method produces more natural videos with better face-attribute alignment and motion smoothness compared to competing approaches, while introducing minimal computational overhead.