Command Palette
Search for a command to run...
行動に先立ち視察せよ:ビジョン・ランゲージ・アクションモデルのためのビジョン基盤表現の強化
行動に先立ち視察せよ:ビジョン・ランゲージ・アクションモデルのためのビジョン基盤表現の強化
概要
Vision-Language-Action(VLA)モデルは、ロボットマニピュレーションにおける有望なパラダイムとして近年登場しており、その信頼性の高い動作予測は、言語指示に条件付けられた視覚的観測を正確に解釈・統合することに大きく依存する。近年の研究では VLA モデルの視覚能力の向上が図られてきたが、多くのアプローチは LLM バックボーンをブラックボックスとして扱い、視覚情報がどのように動作生成にグラウンディングされるかについての洞察が限定的であった。そこで本研究では、異なる動作生成パラダイムに基づく複数の VLA モデルを体系的に分析し、動作生成過程中の深い層において視覚トークンに対する感度が漸減することを観察した。この知見に着想を得て、Vision-Language Mixture-of-Transformers(VL-MoT)フレームワークを基盤とした DeepVision-VLA を提案する。本フレームワークは、視覚基盤モデルと VLA バックボーン間で共有アテンションを可能にし、視覚エキスパートから得られたマルチレベルの視覚特徴を VLA バックボーンの深い層へ注入することで、精密かつ複雑なマニピュレーションを実現するための視覚表現を強化する。さらに、タスクに関連する視覚トークンを保持しつつ、浅層のアテンションを活用して無関係な視覚トークンを剪定する Action-Guided Visual Pruning(AGVP)を導入し、計算オーバーヘッドを最小限に抑えながらマニピュレーションに不可欠な視覚的手がかりを強化する。DeepVision-VLA は、シミュレーション環境および実世界タスクにおいて、それぞれ先行する最先端手法を 9.0% および 7.5% 上回る性能を示し、視覚強化型 VLA モデルの設計に関する新たな示唆を提供する。
One-sentence Summary
Researchers from Peking University, Simplexity Robotics, and The Chinese University of Hong Kong propose DeepVision-VLA, a Vision-Language Mixture-of-Transformers framework that injects multi-level visual features into deeper layers and employs Action-Guided Visual Pruning to significantly outperform prior methods in complex robotic manipulation tasks.
Key Contributions
- The paper introduces DeepVision-VLA, a framework built on a Vision-Language Mixture-of-Transformers architecture that injects multi-level visual features from a dedicated vision expert into deeper layers of the VLA backbone to counteract the progressive loss of visual sensitivity during action generation.
- An Action-Guided Visual Pruning strategy is presented to refine information flow by leveraging shallow-layer attention to identify and preserve task-relevant visual tokens while removing irrelevant background data with minimal computational overhead.
- Experimental results demonstrate that the proposed method outperforms prior state-of-the-art approaches by 9.0% on simulated tasks and 7.5% on real-world manipulation benchmarks, validating the effectiveness of enhanced visual grounding in complex robotic control.
Introduction
Vision-Language-Action (VLA) models are critical for robotic manipulation as they translate visual observations and language instructions into precise physical actions. However, prior approaches often treat the underlying Large Language Model backbone as a black box, failing to address a key limitation where the model's sensitivity to task-relevant visual tokens progressively degrades in deeper layers. To solve this, the authors introduce DeepVision-VLA, which leverages a Vision-Language Mixture-of-Transformers framework to inject multi-level visual features from a dedicated vision expert directly into the deeper layers of the VLA backbone. They further enhance this architecture with Action-Guided Visual Pruning, a technique that filters irrelevant visual tokens using shallow-layer attention to ensure only critical cues influence action generation.
Method
The authors build upon the QwenVLA-OFT baseline, which utilizes a visual encoder (SigLIP2-Large) and an LLM backbone (Qwen3-VL) to map observations and instructions to actions. However, standard VLA models often suffer from sensitivity attenuation in deep layers, where visual grounding becomes diffuse and less effective for precise manipulation. To address this, the authors propose the DeepVision-VLA framework, which enhances visual grounding by injecting multi-level knowledge from a Vision Expert into the deep layers of the VLA.
Refer to the framework diagram for a high-level comparison of the vanilla architecture against the proposed DeepVision-VLA. While the vanilla model relies solely on the LLM backbone, the proposed method introduces a Vision Expert branch that processes high-resolution inputs to capture fine-grained spatial details. This design aims to counteract the loss of visual sensitivity in deeper network layers.
The detailed architecture is depicted in the figure below. The model consists of a Vision Expert branch (using DINOv3) and the standard LLM Backbone. The Vision Expert is connected only to the deepest n layers of the VLA, where visual grounding is typically weakest. To integrate these features, the authors employ a Vision-Language Mixture-of-Transformers (VL-MoT) design. Instead of simple concatenation, the intermediate Query, Key, and Value (QKV) representations from the Vision Expert are exposed and integrated with the corresponding QKV of the deep VLA layers via a shared-attention mechanism.
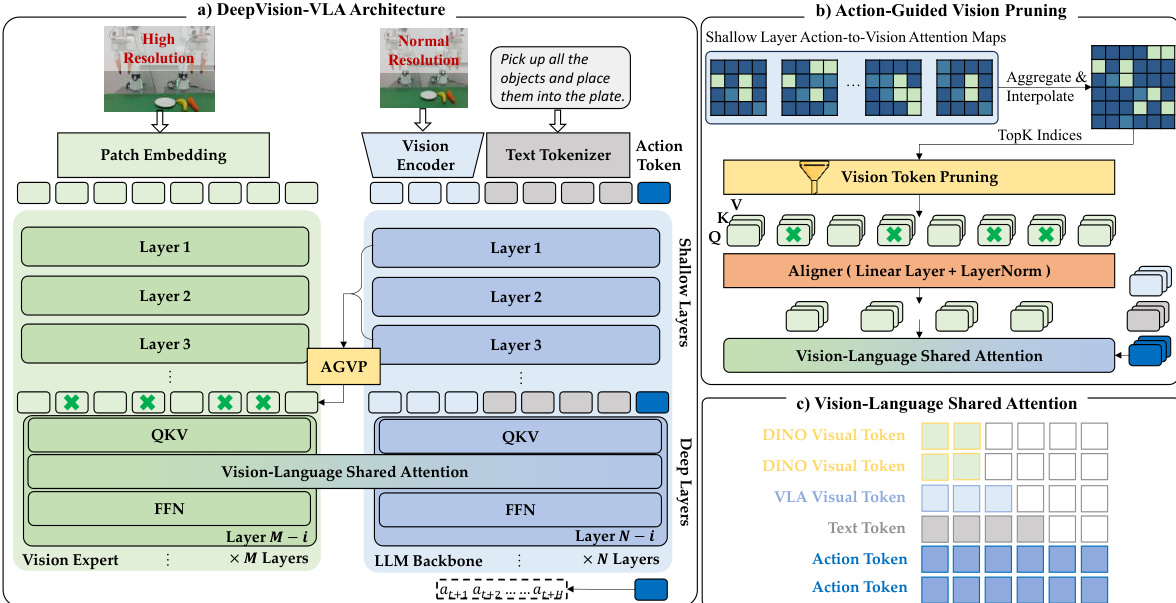
To ensure the model focuses on task-relevant regions, the authors introduce Action-Guided Vision Pruning (AGVP). This strategy leverages attention maps from the shallow layers of the VLA, where visual grounding is most reliable, to identify Regions of Interest (ROIs). These attention cues are aggregated over shallow layers and interpolated to match the Vision Expert's resolution. The model then retains only the top-K most relevant visual tokens, effectively filtering out redundant background features before they are integrated into the deep layers.
The integration of these pruned visual tokens is handled via the Vision-Language Shared Attention mechanism. In this module, the QKV projections from both the Vision Expert and the LLM backbone are concatenated. The attention is computed over this combined set, enabling cross-branch information exchange while preserving separate processing pathways. This allows the deep layers to access high-level, object-centric representations from the Vision Expert, significantly enhancing action prediction precision. The model is trained end-to-end on a large-scale cross-embodiment dataset, and during inference, the pipeline remains fully executable without additional external supervision.
Experiment
- Layer-wise analysis of existing VLA models reveals that while shallow layers effectively ground actions in task-relevant visual regions, deeper layers increasingly rely on diffuse and less relevant features, leading to reduced action reliability.
- Simulation experiments demonstrate that the proposed DeepVision-VLA significantly outperforms multiple baselines across diverse manipulation tasks by integrating a Vision-Language Mixture-of-Transformers framework and an Action-Guided Visual Pruning strategy.
- Ablation studies confirm that coupling a high-resolution Vision Expert with deeper LLM layers and utilizing action-to-vision attention for token pruning are critical for maintaining strong visual grounding and achieving superior performance.
- Real-world evaluations on complex single-arm tasks show that the model achieves high success rates in precise manipulation scenarios, such as writing and pouring, where it maintains stability and accuracy even in multi-stage sequences.
- Generalization tests under unseen backgrounds and varying lighting conditions indicate that the model effectively decouples task-relevant objects from environmental noise and maintains robust performance where baseline methods fail.