Command Palette
Search for a command to run...
Astrolabe: 蒸留された自己回帰型動画モデルのための前進プロセス強化学習の制御
Astrolabe: 蒸留された自己回帰型動画モデルのための前進プロセス強化学習の制御
Songchun Zhang Zeyue Xue Siming Fu Jie Huang Xianghao Kong Y Ma Haoyang Huang Nan Duan Anyi Rao
概要
蒸留された自己回帰(AR)型動画モデルは、効率的なストリーミング生成を可能にする一方、人間の視覚的嗜好と頻繁に乖離する傾向がある。既存の強化学習(RL)フレームワークは、これらのアーキテクチャに本質的に適合しておらず、通常、高コストな再蒸留や、大きなメモリおよび計算オーバーヘッドをもたらすソルバー結合型の逆過程最適化を必要とする。本研究では、蒸留済み AR モデル向けに特化した効率的なオンライン RL フレームワーク「Astrolabe」を提案する。既存のボトルネックを克服するため、ネガティブ事例を認識した微調整に基づく前方過程 RL 定式化を導入する。推論の終端において正例と負例を直接対比させる本アプローチは、逆過程のアンローリングを必要とせずに、暗黙的な方策改善方向を確立する。このアライメントを長尺動画に拡張するため、ローリング KV キャッシュを用いて逐次的にシーケンスを生成するストリーミング学習スキームを提案し、RL 更新をローカルクリップウィンドウに限定適用するとともに、長距離の整合性を確保するために先行コンテキストを条件付ける。さらに、報酬ハッキングを緩和するため、不確実性を認識した選択的正則化と動的な参照更新によって安定化された多報酬目的関数を統合する。広範な実験により、本手法が複数の蒸留済み AR 動画モデルにおいて生成品質を一貫して向上させ、堅牢かつスケーラブルなアライメントソリューションとして機能することが示された。
One-sentence Summary
Researchers from HKUST, JD Explore Academy, and HKU present Astrolabe, an online RL framework that aligns distilled autoregressive video models with human preferences via a forward-process formulation and streaming training scheme, eliminating costly re-distillation while enhancing long-video coherence and mitigating reward hacking.
Key Contributions
- The paper introduces Astrolabe, an online reinforcement learning framework that aligns distilled autoregressive video models with human preferences by contrasting positive and negative samples at inference endpoints to establish policy improvement without reverse-process unrolling.
- A streaming training scheme is proposed to enable scalable alignment for long videos, which generates sequences progressively via a rolling KV-cache and applies reinforcement learning updates exclusively to local clip windows while conditioning on prior context.
- The work integrates a multi-reward objective stabilized by uncertainty-aware selective regularization and dynamic reference updates to mitigate reward hacking, with extensive experiments demonstrating consistent quality improvements across multiple distilled autoregressive video models.
Introduction
Distilled autoregressive video models enable efficient real-time streaming generation by producing frames sequentially, yet they often suffer from artifacts and misalignment with human visual preferences. Prior attempts to align these models using reinforcement learning face significant hurdles, as existing methods either rely on reward-weighted distillation that lacks active exploration or require expensive reverse-process optimization that couples training to specific solvers and incurs high memory overhead. The authors leverage Astrolabe, an efficient online RL framework that introduces a forward-process formulation based on negative-aware fine-tuning to align models without re-distillation or trajectory unrolling. Their approach further scales to long videos through a streaming training scheme that applies updates to local segments while maintaining context, alongside stabilization techniques like multi-reward objectives and uncertainty-aware regularization to prevent reward hacking.
Method
The authors propose Astrolabe, a memory-efficient framework designed to align distilled autoregressive video models with human preferences through online reinforcement learning. The method combines group-wise streaming rollout using a rolling KV cache for efficient group-wise sampling with clip-level forward-process RL for solver-agnostic optimization. To scale to long videos, the framework utilizes Streaming Long Tuning with detached historical gradients. Furthermore, a multi-reward formulation paired with uncertainty-based selective regularization is employed to effectively mitigate reward hacking during training. Refer to the framework diagram for a visual overview of the complete pipeline.
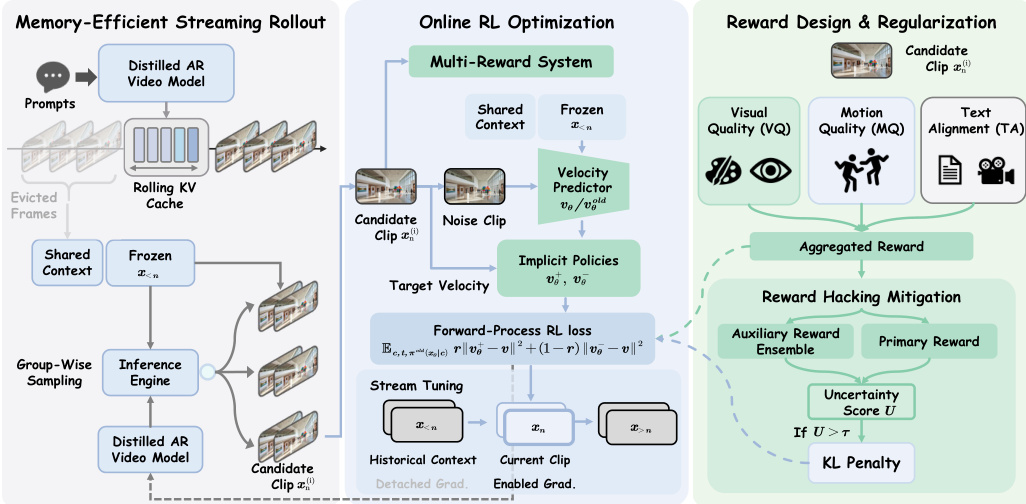
Memory-Efficient Streaming Rollout Standard RL paradigms rely on sequence-level rollouts with global rewards, which introduces temporal credit assignment problems and prohibitive memory overhead. To overcome these limitations, the authors propose a group-wise streaming rollout strategy. They maintain a rolling KV cache to bound memory usage by constructing a restricted visual context window comprising a frame sink of permanently retained frames and a rolling window of the most recent frames. Rather than generating independent long trajectories from scratch, the model autoregressively samples the visual history exactly once and freezes its KV cache as a shared prefix. At each step, the model decodes multiple independent candidate clips in parallel using this shared context, which restricts the generation overhead to the local chunk and substantially reduces rollout time.
Online RL Optimization For each candidate xn(i), the system evaluates a composite reward R(xn(i),c) and computes its advantage A(i) via group-wise mean-centering:
A(i)=R(xn(i),c)−G1j=1∑GR(xn(j),c)This advantage is then normalized as r~i=clip(A(i)/Amax)/2+0.5. Using the current (vθ) and old (vθold) velocity predictors, implicit positive and negative policies are defined via interpolation:
v+=(1−β)vθold+βvθ,v−=(1+β)vθold−βvθThe model is optimized directly via the implicit policy loss Lpolicy by substituting the noised sample to derive vtarget. To further mitigate reward hacking, this objective is complemented by an uncertainty-aware selective KL penalty. Additionally, the framework addresses the train-short/test-long mismatch through Streaming Long Tuning. This paradigm strictly simulates the dynamics of long-sequence inference while decoupling the forward rollout from gradient computation. Specifically, the KV cache of all preceding frames is explicitly detached from the computation graph upon reaching the active training window, allowing gradients to be backpropagated only through the active window.
Reward Design and Regularization To address the issue where scalar reward functions obscure specific quality dimensions, the authors formulate a composite reward integrating three distinct axes: Visual Quality, Motion Quality, and Text-Video Alignment. Visual Quality is computed as the mean HPSv3 score over the top 30% of frames to prevent transient motion blur from disproportionately penalizing the assessment. Motion Quality evaluates temporal consistency using a pre-trained VideoAlign strictly on grayscale inputs to focus on motion dynamics. Text Alignment employs the standard RGB VideoAlign to measure semantic correspondence. To prevent uniform KL regularization from indiscriminately suppressing high-quality generations, an uncertainty-aware selective KL penalty is introduced. For each candidate, sample uncertainty is quantified as the rank discrepancy between the primary reward model and auxiliary models. High positive values indicate likely reward hacking, and these risky samples are masked to apply the KL penalty strictly, preserving optimization flexibility for clean data.
Experiment
- Short-video single-prompt generation: Validates that the Astrolabe framework consistently enhances distilled autoregressive models across various base architectures, yielding sharper textures and superior motion coherence while maintaining inference speed.
- Long-video single-prompt generation: Demonstrates that alignment optimizations performed on short videos effectively extrapolate to extended temporal horizons, improving long-horizon quality and temporal consistency even for models originally trained on short sequences.
- Long-video multi-prompt generation: Confirms the framework's ability to improve human preference alignment in interactive settings, resulting in better visual aesthetics and stable long-range motion consistency during complex narrative transitions.
- Ablation studies: Establish that clip-level group-wise sampling with detached context optimizes the memory-quality trade-off, while a multi-reward formulation prevents single-objective overfitting and selective KL regularization ensures stable convergence without restricting learning freedom.