Command Palette
Search for a command to run...
MetaClaw: Just Talk -- 自然環境下でメタ学習し進化するエージェント
MetaClaw: Just Talk -- 自然環境下でメタ学習し進化するエージェント
概要
大規模言語モデル(LLM)エージェントは複雑なタスクへの適用が拡大する一方、実環境で展開されるエージェントは静的なまま留まり、変化するユーザーニーズに適応できないという課題が存在する。これは、継続的なサービス提供の必要性と、変化するタスク分布に合致させるための能力更新の必要性との間に緊張関係を生じさせている。20 を超えるチャネルで多様なワークロードを処理する OpenClaw などのプラットフォームにおいて、既存の手法は、知識を抽出せずに生データの軌跡を保存する、静的なスキルライブラリを維持する、あるいは再学習のためにシステムダウンタイムを必要とするといった制限を有している。本研究では、基盤となる LLM ポリシーと再利用可能な行動スキルライブラリを共同で進化させる継続的メタ学習フレームワーク「MetaClaw」を提案する。MetaClaw は、2 つの相補的メカニズムを採用している。第一に、スキル駆動型高速適応は、LLM evolver による失敗軌跡の分析を通じて新たなスキルを合成し、ダウンタイムゼロで即座に性能向上を実現する。第二に、機会主義的ポリシー最適化は、クラウド環境における LoRA 微調整とプロセス報酬モデルを用いた強化学習(RL-PRM)による勾配ベースの更新を行う。この更新は、システム非稼働時間とカレンダーデータを監視する「機会主義的メタ学習スケジューラ(OMLS)」によって、ユーザー非アクティブなウィンドウでトリガーされる。これらのメカニズムは相互に強化し合う。洗練されたポリシーはスキル合成のための高品質な軌跡を生成し、豊なスキルはポリシー最適化のための高品質なデータを供給する。データ汚染を防止するため、バージョン管理メカニズムによってサポートデータとクエリデータを分離している。プロキシベースのアーキテクチャ上に構築された MetaClaw は、ローカル GPU を不要としながら、プロダクション規模の LLM へ拡張可能である。MetaClaw-Bench および AutoResearchClaw における実験により、スキル駆動型適応により相対的に最大 32% の精度向上が確認された。さらに、完全なパイプラインは Kimi-K2.5 の精度を 21.4% から 40.6% へ引き上げ、複合的な頑健性を 18.3% 向上させた。コードは https://github.com/aiming-lab/MetaClaw で公開されている。
One-sentence Summary
Researchers from UNC-Chapel Hill, Carnegie Mellon, UC Santa Cruz, and UC Berkeley present MetaClaw, a continual meta-learning framework that uniquely combines zero-downtime skill synthesis with opportunistic policy optimization to enable deployed LLM agents to autonomously evolve and adapt to shifting user needs without service interruption.
Key Contributions
- The paper introduces MetaClaw, a continual meta-learning framework that jointly maintains a base LLM policy and an evolving skill library through two complementary mechanisms: skill-driven fast adaptation for immediate behavioral updates and opportunistic policy optimization for gradient-based weight refinement.
- A novel Opportunistic Meta-Learning Scheduler monitors user inactivity signals such as sleep hours and calendar occupancy to trigger cloud-based LoRA fine-tuning only during idle windows, ensuring zero service downtime while preventing stale reward contamination via strict separation of support and query data.
- Experiments on MetaClaw-Bench and AutoResearchClaw demonstrate that the full pipeline improves task completion rates by 8.25 times and increases accuracy from 21.4% to 40.6%, while skill-driven adaptation alone yields up to a 32% relative accuracy gain.
Introduction
Large language model agents deployed in real-world environments often become misaligned with evolving user needs because they remain static after initial training. Existing adaptation methods struggle with this dynamic context, as memory-based approaches store redundant data without extracting transferable patterns, skill-based systems fail to coordinate behavioral instructions with model weights, and reinforcement learning techniques risk contaminating updates with stale data or require service downtime. The authors present MetaClaw, a continual meta-learning framework that unifies two complementary adaptation mechanisms to enable agents to evolve continuously without interruption. This system combines skill-driven fast adaptation, which instantly synthesizes new behavioral instructions from failures, with opportunistic policy optimization that performs gradient-based weight updates only during user-inactive windows to ensure zero downtime.
Dataset
-
Dataset Composition and Sources The authors construct MetaClaw-Bench, a continual agentic benchmark designed to evaluate adaptation across sequential real-world CLI tasks. It comprises 934 questions distributed over 44 simulated workdays and includes two complementary parts. The benchmark also incorporates AutoResearchClaw, a fully autonomous 23-stage research pipeline used for downstream evaluation to test generalization beyond CLI tasks.
-
Key Details for Each Subset
- Part I (30-workday simulation): Contains 346 questions with 10 to 15 tasks per day. Tasks include file-check operations (structured edits validated by automated checkers) and multi-choice questions on domain rules. Difficulty increases monotonically, with days 25 to 30 requiring sophisticated multi-step reasoning.
- Part II (14-workday simulation): Contains 588 questions with 42 tasks per day, split into 434 multi-choice and 154 file-check tasks. File-check tasks here focus on rule-based transformations where compliance with behavioral heuristics like schema conventions is the primary bottleneck.
- AutoResearchClaw: A long-horizon workload covering literature search, hypothesis generation, code synthesis, and paper drafting, where failures manifest as stage retries or incomplete pipeline runs.
-
Usage in Model Training and Evaluation The authors use MetaClaw-Bench to stress-test continual adaptation under increasing difficulty. Part I measures execution reliability and end-to-end completion, while Part II evaluates how quickly the policy internalizes procedural rules. For training, the system employs a skill-driven fast adaptation mechanism that synthesizes behavioral instructions from failures and an opportunistic policy optimization phase using reinforcement learning during idle windows. The AutoResearchClaw dataset is used to inject accumulated skills into the system prompt of all 18 LLM-driven stages to measure improvements in stage completion and retry rates.
-
Processing and Metadata Construction
- Workspace State: The workspace state, including files and configs, persists across rounds within each day, and each question includes the outcome of the previous round as corrective feedback context.
- Context Injection: Part II initializes sessions with specific workspace context files defining the agent's role, user profile, and behavioral principles.
- Skill Evolution: Failed trajectories are added to a support set to synthesize new skills, while successful trajectories are stored in an RL buffer for policy updates.
- Metrics: Evaluation relies on overall accuracy and file-check completion rates for the benchmark, and pipeline-level metrics like stage retry rate and robustness scores for the research pipeline.
Method
MetaClaw functions as a continual meta-learning system designed to enhance a deployed CLI agent over a non-stationary task stream. The core objective is to continuously improve a meta-model M=(θ,S), where θ denotes the parameters of the base LLM policy and S represents a library of skill instructions. The architecture relies on two complementary mechanisms operating at different timescales: skill-driven fast adaptation and opportunistic policy optimization.
Refer to the framework diagram for a visual representation of the system components and data flow.
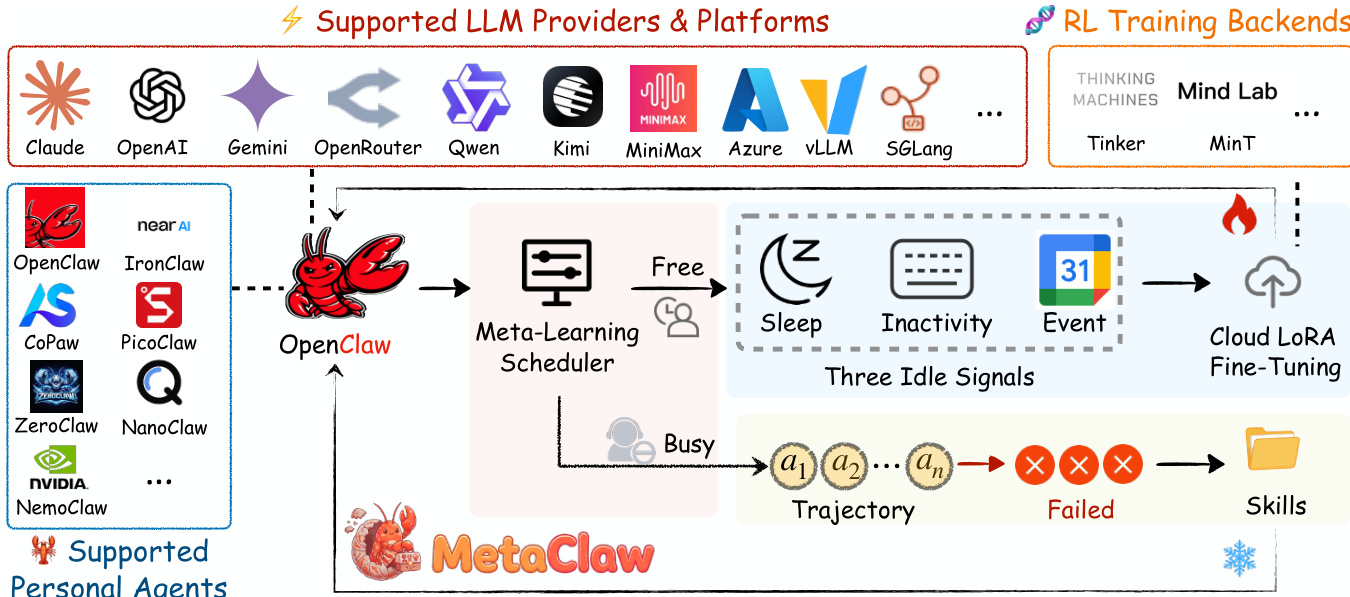
The system integrates various supported personal agents and LLM providers into a unified learning loop orchestrated by a Meta-Learning Scheduler. This scheduler manages the agent's state, distinguishing between "Busy" periods where the agent serves user tasks and "Free" periods where the system is idle.
During the "Busy" state, the system employs Skill-Driven Fast Adaptation. As the agent executes tasks, it collects trajectories. Trajectories that reveal failure modes form a support set Dsup. A skill evolver analyzes these failures to synthesize new behavioral instructions, updating the skill library S via a gradient-free experience distillation process: Sg+1=Sg∪E(Sg,Dasup) This step modifies only the skill library, leaving the policy parameters θ fixed. Because skill injection operates through the prompt, this adaptation incurs zero service downtime and takes effect immediately for subsequent tasks.
Conversely, during the "Free" state, the system performs Opportunistic Policy Optimization. The Meta-Learning Scheduler monitors three idle signals to determine when to initiate training: Sleep windows, System Inactivity, and Calendar-aware scheduling. When an idle window is detected, the scheduler triggers Cloud LoRA Fine-Tuning to update the policy parameters θ. This process utilizes a buffer of query trajectories B collected after adaptation has taken effect. The policy update follows the gradient of the expected reward: θt+1=θt+α∇θE(τ,ξ,a′)∼B[R(πθ(⋅∣τ,Sa′))] Crucially, the system enforces a strict separation between support and query data through a skill generation versioning mechanism. Support data that triggers skill evolution is consumed and discarded, while only query data reflecting post-adaptation behavior is used for policy optimization. This ensures that the policy is optimized for the agent's current capabilities rather than stale reward signals.
Experiment
- Main experiments on MetaClaw-Bench validate that the framework consistently improves performance across different models and adaptation modes, with the full pipeline delivering the largest gains in both partial execution quality and end-to-end task completion.
- Qualitative analysis confirms that skill injection alone enhances reasoning and partial execution but fails to reliably achieve zero-defect outputs, whereas combining skill injection with gradient-based policy optimization is necessary to unlock complete task success.
- Results indicate that weaker models benefit more from skill injection than stronger baselines, suggesting the approach effectively compensates for capability gaps and is particularly valuable for deploying capable but non-state-of-the-art models.
- Experiments on the AutoResearchClaw benchmark demonstrate that skill injection generalizes to open-ended, multi-stage research pipelines without requiring gradient updates, significantly reducing retry rates and refining cycles.
- Temporal and task-type breakdowns reveal that skill-driven adaptation addresses procedural knowledge gaps early in training, while weight-level optimization later shifts policy behavior to handle complex execution demands, validating the complementary nature of the two mechanisms.