Command Palette
Search for a command to run...
LeWorldModel:画素からの安定したエンドツーエンド型結合埋め込み予測アーキテクチャ
LeWorldModel:画素からの安定したエンドツーエンド型結合埋め込み予測アーキテクチャ
Lucas Maes Quentin Le Lidec Damien Scieur Yann LeCun Randall Balestriero
概要
結合埋め込み予測アーキテクチャ(JEPA)は、コンパクトな潜在空間における世界モデルの学習に対する有望な枠組みを提供する。しかし、既存の手法は表現の崩壊を回避するために、複雑な多項損失、指数移動平均、事前学習済みエンコーダ、または補助的教師信号に依存しており、依然として脆弱である。本研究では、LeWorldModel(LeWM)を提案する。これは、2 つの損失項(次の埋め込み予測損失と、ガウス分布に従う潜在埋め込みを強制する正則化項)のみを用いて、生ピクセルから安定してエンドツーエンドで学習する初の JEPA である。これにより、現在存在する唯一のエンドツーエンドの代替手法と比較して、調整可能な損失ハイパーパラメータを 6 から 1 に削減する。LeWM は、単一の GPU で 15M パラメータを数時間で学習可能であり、ファウンデーションモデルベースの世界モデルに比べて最大 48 倍高速なプランニングを実現しつつ、多様な 2D および 3D 制御タスクにおいて競争力のある性能を維持する。制御タスクを超えて、物理量のプロービングを通じて、LeWM の潜在空間が意味のある物理的構造を符号化していることを示す。さらに、驚き評価(surprise evaluation)により、本モデルが物理的に不可能なイベントを確実に検出できることを確認した。
One-sentence Summary
Researchers from Mila, NYU, and Samsung SAIL propose LeWorldModel, a Joint-Embedding Predictive Architecture that trains stably end-to-end from raw pixels using only two loss terms, eliminating the need for complex losses and pretrained encoders while achieving up to 48x faster planning on a single GPU and reliably detecting physically implausible events across diverse control tasks.
Key Contributions
- The paper introduces LeWorldModel (LeWM), a Joint Embedding Predictive Architecture that trains stably end-to-end from raw pixels using only two loss terms. This approach reduces tunable loss hyperparameters from six to one compared to the only existing end-to-end alternative.
- The method plans up to 48 times faster than foundation-model-based world models while remaining competitive across diverse 2D and 3D control tasks. This efficiency is achieved with 15M parameters trainable on a single GPU in a few hours without relying on exponential moving averages or pretrained encoders.
- The latent space encodes meaningful physical structure, as demonstrated by probing of physical quantities within the model. Surprise evaluation confirms that the system reliably detects physically implausible events beyond standard control benchmarks.
Introduction
World Models enable agents to plan using internal simulations learned directly from raw sensory inputs like camera pixels. Although Joint Embedding Predictive Architectures (JEPAs) provide a compact framework for this task, prior methods often suffer from representation collapse and require complex stabilization heuristics or pretrained encoders. The authors introduce LeWorldModel, the first stable JEPA trained end-to-end from pixels using only a prediction loss and a Gaussian regularizer. This approach eliminates heuristic training tricks, reduces hyperparameter tuning, and enables efficient planning on a single GPU while capturing meaningful physical structures.
Dataset
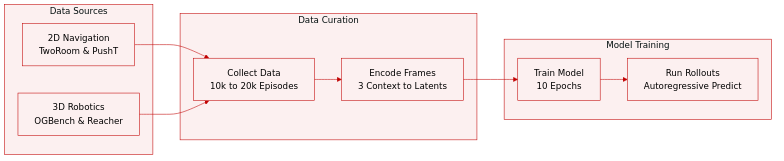
The authors evaluate their world models across four continuous control environments using the following datasets:
-
TwoRoom: A 2D navigation task from Sobal et al. where an agent moves between two rooms. The dataset includes 10,000 episodes averaging 92 steps, generated by a noisy heuristic policy guiding the agent through a door to the target.
-
PushT: A 2D manipulation task from Zhou et al. requiring an agent to push a T-shaped block to a target configuration. This subset contains 20,000 expert episodes with an average length of 196 steps.
-
OGBench-Cube: A 3D robotic manipulation task from Park et al. limited to the single-cube variant for pick-and-place operations. The authors collect 10,000 episodes of 200 steps using the benchmark library heuristic.
-
Reacher: A continuous control environment from the DeepMind Control Suite involving a two-joint arm reaching a target in a 2D plane. The dataset consists of 10,000 episodes of 200 steps collected via a Soft Actor-Critic policy.
-
Training and Processing: Each world model is trained for 10 epochs on these datasets. For predictor rollouts, three context frames are encoded into latent representations to autoregressively generate future states conditioned on actions, with predictions decoded by a separate decoder not used during training.
Method
LeWorldModel (LeWM) operates as a Joint-Embedding Predictive Architecture designed to learn task-agnostic world models from offline, reward-free data. The framework consists of two primary components: an encoder that maps raw pixel observations into a compact latent space, and a predictor that models environment dynamics by forecasting future latent embeddings conditioned on actions.
The training procedure involves processing sequences of observations and actions to update the model parameters end-to-end. The encoder, implemented as a Vision Transformer (ViT), processes an input frame ot to produce a latent embedding zt. This embedding is derived from the [CLS] token of the final layer, passed through a projection MLP with Batch Normalization to facilitate optimization. The predictor, a transformer architecture utilizing Adaptive Layer Normalization (AdaLN) for action conditioning, takes the current latent state zt and action at to predict the next state embedding z^t+1.
To ensure the learned representations are informative and stable, the training objective combines a prediction loss with a regularization term. The prediction loss Lpred minimizes the mean squared error between the predicted embedding and the ground truth embedding of the next time step:
Lpred≜∥z^t+1−zt+1∥22
However, relying solely on prediction can lead to representation collapse. To prevent this, the authors introduce the Sketched-Isotropic-Gaussian Regularizer (SIGReg). As shown in the figure below:
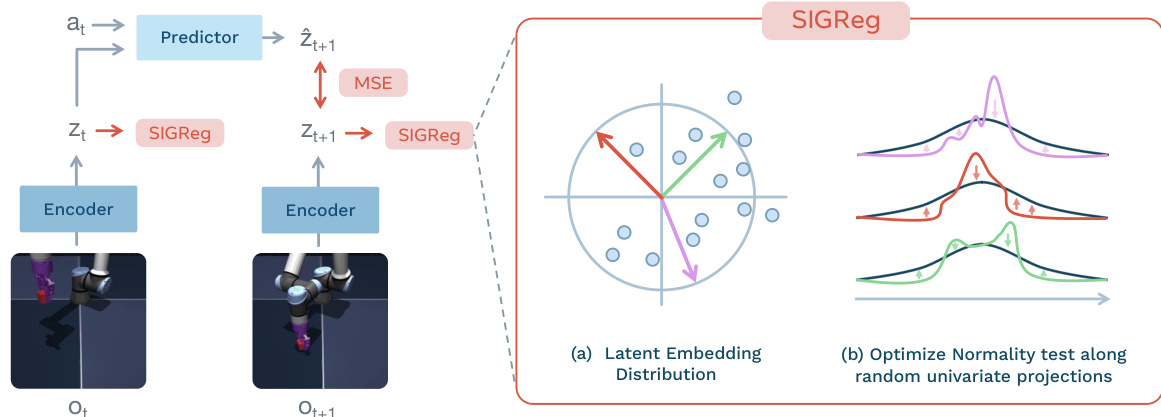 This module encourages the latent embeddings to match an isotropic Gaussian target distribution. Directly testing for normality in high dimensions is difficult, so SIGReg projects the embeddings onto random unit-norm directions and optimizes the univariate Epps-Pulley test statistic along these projections. By the Cramér–Wold theorem, matching these one-dimensional marginals ensures the full joint distribution matches the target. The total loss is defined as:
LLeWM≜Lpred+λSIGReg(Z)
where λ is the regularization weight and Z represents the tensor of latent embeddings.
This module encourages the latent embeddings to match an isotropic Gaussian target distribution. Directly testing for normality in high dimensions is difficult, so SIGReg projects the embeddings onto random unit-norm directions and optimizes the univariate Epps-Pulley test statistic along these projections. By the Cramér–Wold theorem, matching these one-dimensional marginals ensures the full joint distribution matches the target. The total loss is defined as:
LLeWM≜Lpred+λSIGReg(Z)
where λ is the regularization weight and Z represents the tensor of latent embeddings.
At inference time, LeWM leverages the learned dynamics for decision-making through latent planning using Model Predictive Control (MPC). The planning process is illustrated in the figure below:
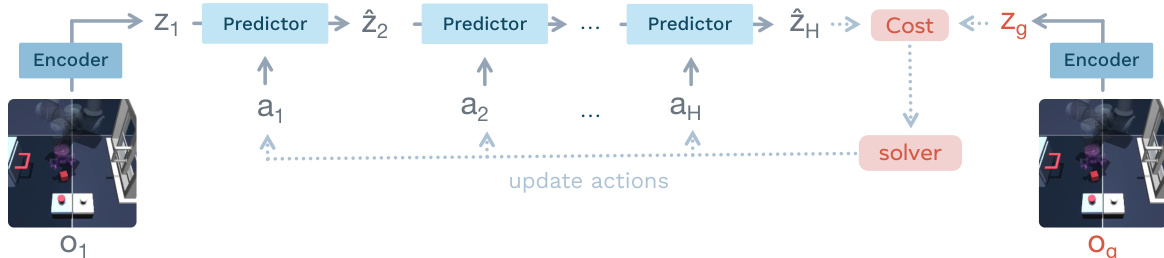 Given an initial observation, the system encodes it into a latent state and iteratively rolls out predicted latent states over a horizon H using the predictor. A cost function is computed based on the distance between the final predicted latent state z^H and the latent embedding of a goal observation zg. An optimization solver, specifically the Cross-Entropy Method (CEM), is used to find the sequence of actions that minimizes this terminal cost. To mitigate error accumulation over long horizons, a receding-horizon strategy is employed where only the first few planned actions are executed before replanning from the updated observation.
Given an initial observation, the system encodes it into a latent state and iteratively rolls out predicted latent states over a horizon H using the predictor. A cost function is computed based on the distance between the final predicted latent state z^H and the latent embedding of a goal observation zg. An optimization solver, specifically the Cross-Entropy Method (CEM), is used to find the sequence of actions that minimizes this terminal cost. To mitigate error accumulation over long horizons, a receding-horizon strategy is employed where only the first few planned actions are executed before replanning from the updated observation.
Experiment
LeWM is evaluated against baselines such as PLDM and DINO-WM across diverse navigation and manipulation tasks in both two and three-dimensional environments. Results indicate that the method achieves significant planning speedups and more stable training convergence compared to complex multi-term objectives, while effectively capturing underlying physical quantities through latent representations. Although performance dips in low-complexity settings due to regularization mismatches, the model demonstrates robust physical understanding by detecting violations of expected dynamics without explicit temporal regularization.
The authors analyze the impact of replacing the default Vision Transformer encoder with a ResNet-18 backbone. Results indicate that while the ViT architecture yields slightly better performance, the ResNet-18 variant remains competitive, suggesting the method is robust to the choice of vision encoder. ViT encoder achieves higher success rates than ResNet-18 ResNet-18 backbone maintains competitive planning performance Method performance is largely agnostic to encoder architecture

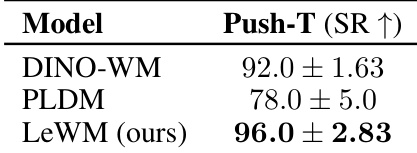
The authors evaluate planning performance on the Push-T task using Success Rate as the metric. LeWM achieves the top performance, surpassing both DINO-WM and PLDM. The results highlight the proposed method's ability to capture task-relevant quantities effectively. LeWM achieves the highest success rate among all tested models PLDM demonstrates lower performance and greater variance compared to others The proposed method outperforms DINO-WM using only pixel observations
The authors analyze the impact of predictor capacity on planning performance within the Push-T environment. The results demonstrate that a small predictor configuration outperforms both smaller and larger model variants. This indicates that the small scale offers the best trade-off between capacity and optimization stability. The small predictor size achieves the highest success rate Smaller model variants result in lower performance scores Larger model configurations do not provide additional gains
The the the table compares the ability of different models to encode agent position information using linear and non-linear probes. LeWM and PLDM demonstrate significantly better linear probing performance compared to DINO-WM, while all models achieve near-perfect results with non-linear probes. LeWM and PLDM achieve similar performance on linear probes Both methods significantly outperform DINO-WM on linear metrics Non-linear probes yield near-perfect results for all models
The authors evaluate the physical understanding of LeWM by probing latent representations for quantities like position and velocity. Results indicate that LeWM generally outperforms the PLDM baseline and remains competitive with the pretrained DINO-WM model, particularly for positional properties. LeWM achieves lower prediction error than PLDM across most physical properties Non-linear MLP probes consistently outperform linear probes in recovering physical quantities Positional properties like block position are recovered with significantly higher accuracy than rotational properties
Experiments evaluate the proposed method's robustness and planning capabilities on the Push-T task, demonstrating that performance remains competitive across different vision encoder architectures. LeWM achieves superior planning success rates compared to baselines, while ablation studies reveal that a small predictor configuration provides the optimal balance between capacity and optimization stability. Furthermore, probing analyses confirm that the model effectively encodes agent position and physical quantities, outperforming competitors on linear probes and recovering positional properties with high accuracy.