Command Palette
Search for a command to run...
アテンション残差
アテンション残差
概要
現代の LLM では、PreNorm を伴う残差接続が標準的に採用されていますが、これらはすべての層の出力を固定された単位重みで累積します。この均一な集約により、層の深さに応じて隠れ状態が制御不能に増大し、各層の寄与が段階的に希薄化するという問題が生じます。本研究では、Attention Residuals(AttnRes)を提案します。これは、固定された累積に代わり、先行する層の出力に対する softmax アテンションを導入し、各層が学習された入力依存の重みを用いて、より早期の表現を選択的に集約できるようにします。大規模モデルの学習において、すべての先行層の出力へのアテンションがもたらすメモリおよび通信オーバーヘッドに対処するため、Block AttnRes を導入しました。これは層をブロックに分割し、ブロックレベルの表現に対してアテンションを適用することで、AttnRes 全体の利点をほぼ維持しつつ、メモリフットプリントを削減します。キャッシュベースのパイプライン通信と二段階計算戦略と組み合わせることで、Block AttnRes は、最小限のオーバーヘッドで標準的な残差接続に実用的に置き換わる代替手段となります。スケーリング則に関する実験により、この改善がモデルサイズにかかわらず一貫して得られることが確認され、アブレーション研究により、コンテンツ依存の深さ方向選択の有用性が検証されました。さらに、AttnRes を Kimi Linear アーキテクチャ(総パラメータ数 48B、アクティブパラメータ数 3B)に統合し、1.4T トークンで事前学習を行いました。その結果、AttnRes は PreNorm による希薄化を緩和し、深さ方向における出力の大きさおよび勾配分布をより均一化するとともに、評価されたすべての下流タスクにおいて性能を向上させることが示されました。
One-sentence Summary
The Kimi Team proposes Attention Residuals, a novel mechanism replacing fixed residual weights with learned softmax attention to mitigate hidden-state dilution in large language models. Their optimized Block AttnRes variant reduces memory overhead while significantly improving training stability and downstream task performance across various model scales.
Key Contributions
- The paper introduces Attention Residuals (AttnRes), a mechanism that replaces fixed unit-weight accumulation with learned softmax attention over preceding layer outputs to enable selective, content-dependent aggregation of representations across depth.
- To address scalability, the work presents Block AttnRes, which partitions layers into blocks and attends over block-level summaries to reduce memory and communication complexity from O(Ld) to O(Nd) while preserving performance gains.
- Comprehensive experiments on a 48B-parameter model pre-trained on 1.4T tokens demonstrate that the method mitigates hidden-state dilution, yields more uniform gradient distributions, and consistently improves downstream task performance compared to standard residual connections.
Introduction
The research addresses the challenge of efficiently scaling large language models while maintaining high performance, a critical need for deploying advanced AI in real-world applications. Prior approaches often struggle with the computational overhead of attention mechanisms or fail to fully utilize residual connections for stable training at scale. To overcome these limitations, the authors introduce a novel framework centered on attention residuals that optimizes information flow and reduces training costs without sacrificing model quality.
Method
The authors propose Attention Residuals (AttnRes) to address the limitations of standard residual connections in deep networks. In standard architectures, the hidden state update follows a fixed recurrence hl=hl−1+fl−1(hl−1), which unrolls to a uniform sum of all preceding layer outputs. This fixed aggregation causes hidden-state magnitudes to grow linearly with depth, diluting the contribution of individual layers. AttnRes replaces this fixed accumulation with a learned, input-dependent attention mechanism over depth.
Refer to the framework diagram for a visual comparison of the residual connection variants.
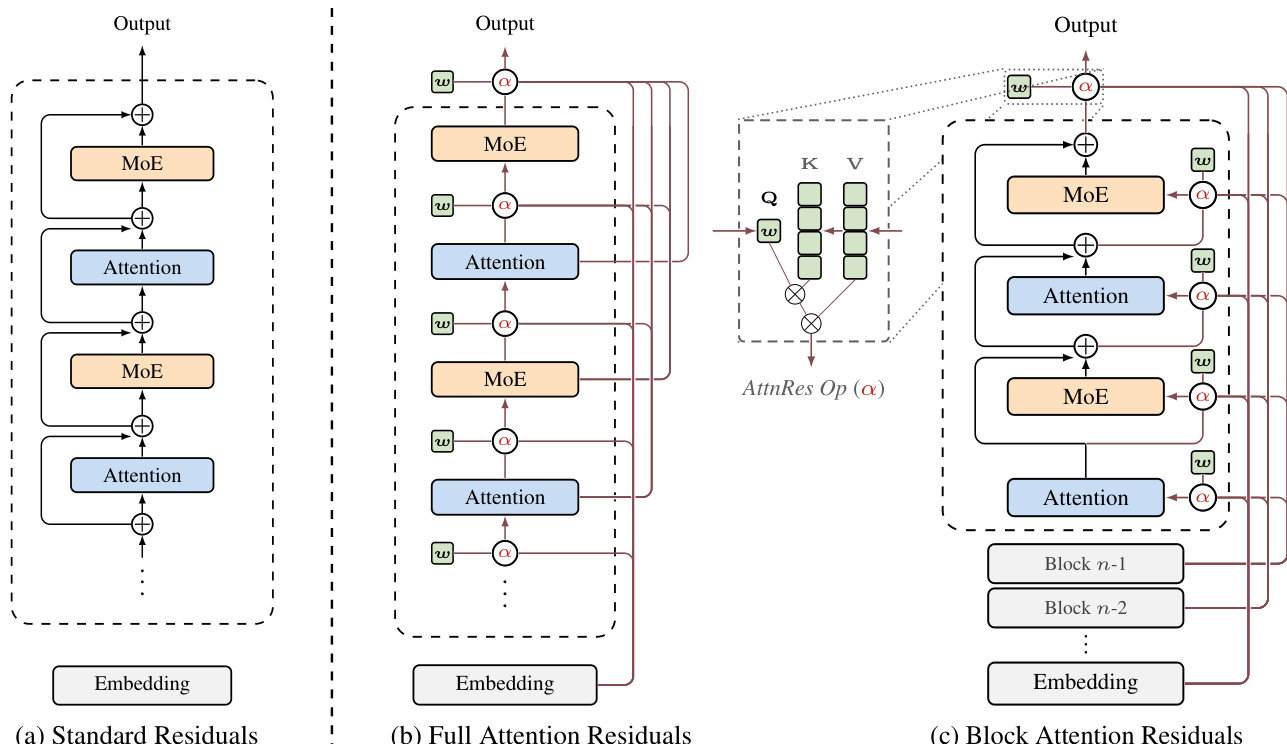
As shown in the figure, the standard approach (a) simply adds the previous layer output. In contrast, Full AttnRes (b) allows each layer to selectively aggregate all previous layer outputs via learned attention weights. Specifically, the input to layer l is computed as hl=∑i=0l−1αi→l⋅vi, where vi represents the output of layer i (or the embedding for i=0). The attention weights αi→l are derived from a softmax over a kernel function ϕ(ql,ki), where ql=wl is a learnable pseudo-query vector specific to layer l, and ki=vi are the keys derived from previous outputs. This mechanism enables content-aware retrieval across depth with minimal parameter overhead.
To make this approach scalable for large models, the authors introduce Block AttnRes (c). This variant partitions the L layers into N blocks. Within each block, layer outputs are reduced to a single representation via summation, and attention is applied only over the N block-level representations. This reduces the memory and communication complexity from O(Ld) to O(Nd). The intra-block accumulation is defined as bn=∑j∈Bnfj(hj), where Bn is the set of layers in block n. Inter-block attention then operates on these block summaries, allowing layers within a block to attend to previous blocks and the partial sum of the current block.
For efficient training at scale, the method incorporates specific infrastructure optimizations to handle the communication of block representations across pipeline stages. As illustrated in the pipeline communication example, cross-stage caching is employed to eliminate redundant data transfers.
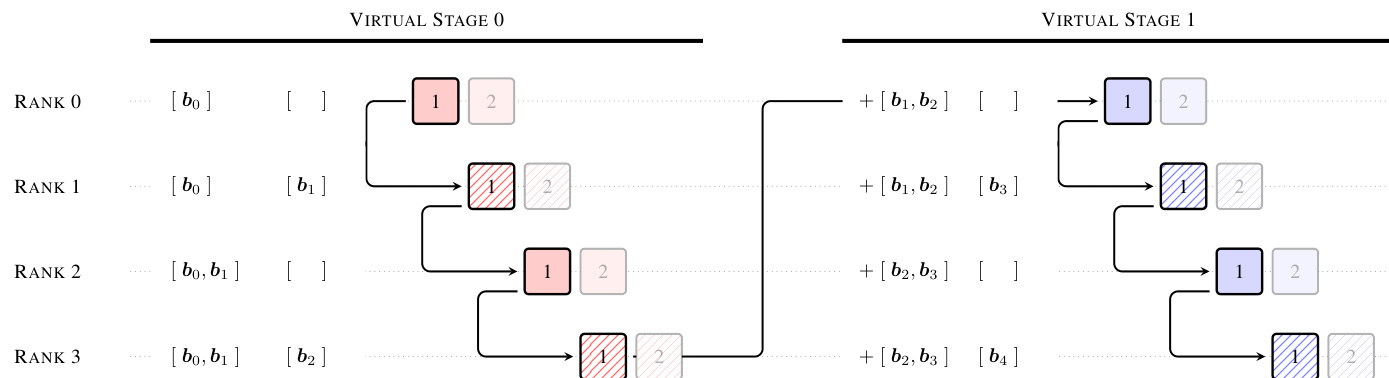
In this setup, blocks received during earlier virtual stages are cached locally. Consequently, stage transitions only transmit incremental blocks accumulated since the receiver's corresponding chunk in the previous virtual stage, rather than the full history. This caching strategy reduces the peak per-transition communication cost significantly, enabling the method to function as a practical drop-in replacement for standard residual connections with marginal training overhead. Additionally, a two-phase computation strategy is used during inference to amortize cross-block attention costs, further minimizing latency.
Experiment
- Scaling law experiments validate that both Full and Block Attention Residuals (AttnRes) consistently outperform the PreNorm baseline across all model sizes, with Block AttnRes recovering most of the performance gains of the full variant while maintaining lower memory overhead.
- Main training results demonstrate that AttnRes resolves the PreNorm dilution problem by bounding hidden-state growth and achieving a more uniform gradient distribution, leading to superior performance on multi-step reasoning, code generation, and knowledge benchmarks.
- Ablation studies confirm that input-dependent weighting via softmax attention is critical for performance, while block-wise aggregation offers an effective trade-off between memory efficiency and the ability to access distant layers compared to sliding-window or full cross-layer access.
- Architecture sweeps reveal that AttnRes shifts the optimal design preference toward deeper and narrower networks compared to standard Transformers, indicating that the method more effectively leverages increased depth for information flow.
- Analysis of learned attention patterns shows that AttnRes preserves locality while establishing learned skip connections to early layers and the token embedding, with Block AttnRes successfully maintaining these structural benefits through implicit regularization.