Command Palette
Search for a command to run...
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Yan Shu Bin Ren Zhitong Xiong Xiao Xiang Zhu Begüm Demir Nicu Sebe Paolo Rota
概要
視覚言語モデル(VLMs)は地球観測(EO)分野において有望な成果を示してきましたが、複雑な空間推論を精密なピクセルレベルの視覚表現に基づいて行うタスクにおいては依然として課題を抱えています。本研究では、この課題に対処するため、ピクセルに根ざした地理空間推論を実現する統合型 VLM「TerraScope」を提案します。TerraScope は以下の 2 つの主要機能を備えています:(1)モダリティに柔軟な推論:光学画像または SAR(合成開口レーダー)画像といった単一モダリティの入力を処理するだけでなく、両方が利用可能な場合には適応的に異なるモダリティを融合させ、推論プロセスに統合します。(2)多時相推論:複数の時点にわたる変化分析を行うために、時系列データを統合的に活用します。さらに、複数のソースから収集され、推論チェーン内にピクセルレベルのマスクを埋め込んだ 100 万サンプル規模の大規模データセット「Terra-CoT」を構築しました。また、ピクセルに根ざした地理空間推論の性能を評価する最初のベンチマーク「TerraScope-Bench」を提案します。このベンチマークは 6 つのサブタスクで構成され、回答の精度とマスクの品質の両方を評価することで、真のピクセルに根ざした推論を確保します。実験結果により、TerraScope は既存の VLMs をピクセルに根ざした地理空間推論の分野で大幅に凌駕し、かつ解釈可能な視覚的証拠を提供することが示されました。
One-sentence Summary
Researchers from the University of Trento, BIFOLD, TU Berlin, and Technical University of Munich propose TerraScope, a unified Vision Language Model that advances earth observation by integrating pixel-level grounding masks into interleaved CoT for superior spatial reasoning. This approach outperforms prior VLMs by enabling modality-flexible and multi-temporal analysis while supported by the new Terra-CoT dataset and TerraScope-Bench.
Key Contributions
- The paper introduces TerraScope, a unified Vision-language model that grounds each reasoning step in precise segmentation masks to enable fine-grained spatial analysis while supporting multi-temporal change reasoning and adaptive fusion of optical and SAR modalities.
- A large-scale dataset named Terra-CoT is curated containing 1 million instruction-tuning samples with pixel-accurate masks embedded directly into reasoning chains to facilitate scalable training for pixel-grounded geospatial tasks.
- The work presents TerraScope-Bench, the first benchmark for pixel-grounded geospatial reasoning featuring 3,837 expert-verified samples and dual evaluation metrics that assess both answer accuracy and mask quality to ensure authentic visual grounding.
Introduction
Earth observation relies on analyzing vast satellite archives for critical tasks like disaster response and environmental monitoring, yet current Vision Language Models struggle to perform the precise, pixel-level spatial reasoning required for these applications. Existing approaches often fail because they rely on coarse-grained visual cues like bounding boxes that cannot capture the continuous spatial distributions of land cover, or they depend on external tools that increase complexity and reduce controllability. To address these gaps, the authors introduce TerraScope, a unified framework that interleaves pixel-level segmentation masks with textual reasoning chains to enable fine-grained geospatial analysis. This model uniquely supports adaptive fusion of optical and SAR modalities as well as multi-temporal change detection, while the team also releases Terra-CoT, a large-scale dataset with embedded masks, and TerraScope-Bench, the first evaluation suite designed to measure both answer accuracy and mask quality.
Dataset
-
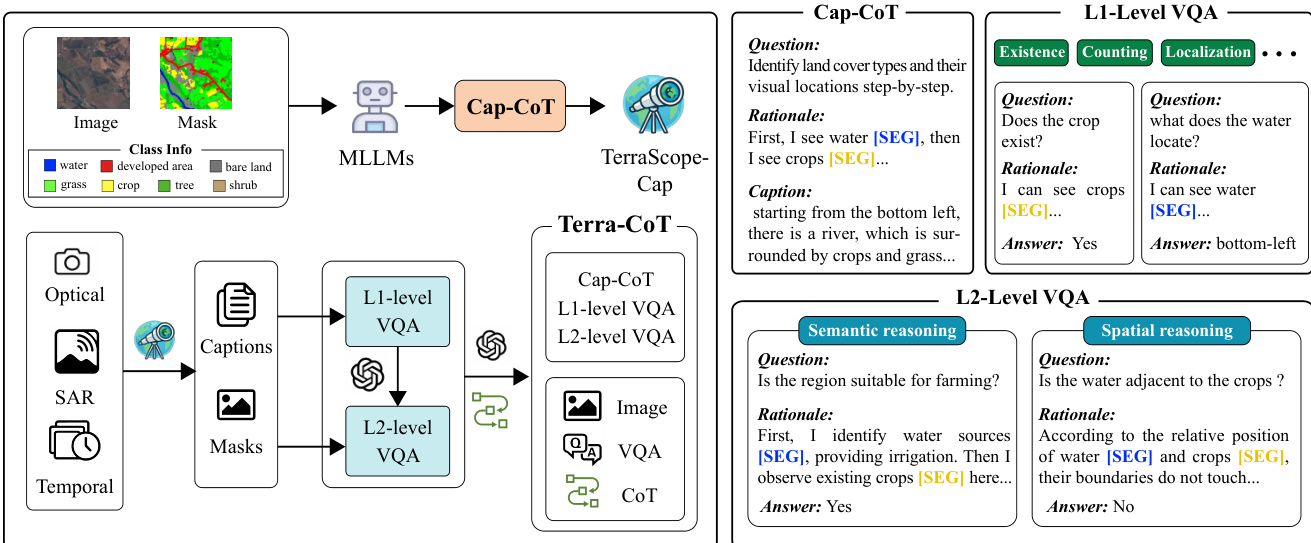
Dataset Composition and Sources The authors construct the Terra-CoT dataset through a two-stage automated pipeline to create pixel-grounded visual Chain-of-Thought (CoT) data. The process begins with Cap-CoT, a 250K sample subset derived from existing datasets with semantic annotations including ChatEarthNet, BigEarthNet, xBD, and TEOChat. This initial subset trains an intermediate annotator called TerraScope-Cap, which is then used to synthesize the full Terra-CoT dataset from diverse sources covering optical, SAR, and temporal imagery across global regions.
-
Key Details for Each Subset
- Cap-CoT: Contains 250K samples generated by prompting a large multimodal model with mask-overlaid images and segmentation labels to produce detailed captions with explicit reasoning traces.
- L1-Level VQA: Comprises basic spatial grounding tasks such as object existence, counting, localization, area quantification, and boundary detection, synthesized using template-based questions and deterministic mask analysis.
- L2-Level VQA: Includes 1M samples featuring complex multi-step reasoning divided into L2-Spatial (cross-entity analysis like adjacency or distance) and L2-Semantic (domain knowledge tasks like land suitability), generated by an LLM combining visual evidence with spatial or semantic logic.
-
Model Usage and Training Strategy The authors utilize the 250K Cap-CoT samples to train the TerraScope model and build the TerraScope-Cap annotator. The full Terra-CoT dataset, comprising 1M synthesized samples, serves as the primary training mixture for instruction tuning. The data is processed to ensure a balance between simple spatial queries and complex reasoning tasks, with the L2 subset specifically designed to enhance multi-step spatial analysis capabilities.
-
Processing, Cropping, and Metadata Construction
- Grounded Captioning: The pipeline inputs satellite images with colored mask overlays and segmentation labels into a model to force explicit references to masked regions during caption generation.
- Hierarchical Synthesis: L1 questions are generated via templates with answers computed deterministically from segmentation masks, while L2 questions are synthesized by an LLM to combine multiple L1 tasks into complex scenarios.
- Refinement: For VQA-CoT, the authors refine ground-truth masks by computing intersections between predicted masks from TerraScope-Cap and available annotations to ensure higher quality.
- Metadata: Input data includes satellite images, segmentation labels, and metadata such as resolution, sensor type, and location to support diverse reasoning contexts.
Method
The authors propose TerraScope, a framework designed for pixel-grounded visual reasoning. Unlike traditional Vision-Language Models (VLMs) that rely solely on textual reasoning, TerraScope interleaves segmentation masks and masked visual features directly into the reasoning chain. Formally, while traditional VLMs output an answer via language-only reasoning, TerraScope generates a sequence that includes reasoning steps, segmentation masks, and masked visual features.
[r1,(m1,v1),r2,(m2,v2),…,rk,(mk,vk),a]=f(v,q)As shown in the framework diagram, the system integrates a Language Tokenizer, Visual Encoder, and Ground Encoder into a unified pipeline. The Large Language Model (LLM) works in tandem with a Mask Decoder. When the LLM generates a special [SEG] token, it triggers the Mask Decoder to produce a segmentation mask based on the hidden states of that token. This design allows the LLM to control mask generation through learned prompt embeddings, effectively grounding the reasoning process in specific visual regions.
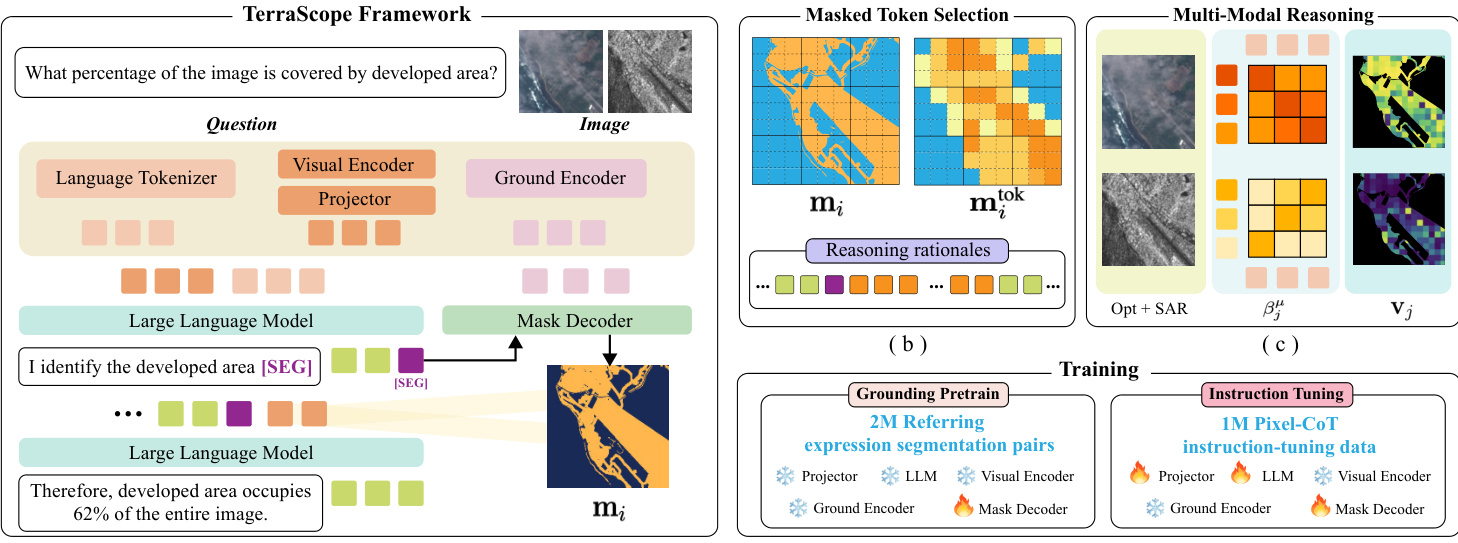
This mechanism allows the model to ground its reasoning in specific visual regions. For instance, when asked to compare sizes or measure distances, the model identifies relevant areas, generates masks, and extracts visual features from those specific regions to inform subsequent text generation. The examples below demonstrate how the model explicitly segments water, crops, or buildings to derive accurate answers.

The framework handles complex Earth Observation (EO) data scenarios. For multi-source inputs like Optical and SAR pairs, the model employs text-guided token-level modality selection. It computes relevance scores to dynamically choose the most informative modality for each visual token. For temporal sequences, explicit indicators specify which image frame to segment and extract features from.
Training occurs in two stages. First, the model undergoes grounding pretraining on referring expression segmentation pairs to establish basic capabilities. Second, it is fine-tuned on the Terra-CoT dataset, which contains instruction-tuning data with interleaved visual and textual traces. The data curation pipeline involves generating captions and masks to create diverse reasoning questions at different complexity levels.
To ensure efficiency, the system limits the number of visual tokens injected into the reasoning sequence. If the selected tokens exceed a threshold, spatial uniform sampling is applied to maintain representative coverage. The effectiveness of this approach is evident when comparing performance against standard VLMs. While other models might rely on color-based heuristics or rough estimates, TerraScope performs precise pixel counting and area identification to reach the correct conclusion.

Experiment
- Main benchmark evaluations on TerraScope-Bench, LandSat30-AU, and DisasterM3 validate that pixel-grounded reasoning significantly outperforms existing general and EO-specific VLMs, particularly on tasks requiring fine-grained spatial analysis like area estimation and object counting.
- Ablation studies on CoT strategies confirm that precise pixel-level grounding via segmentation masks is essential for accurate reasoning, as random token selection or coarse bounding boxes fail to capture complex spatial boundaries.
- Experiments on multi-modal reasoning demonstrate that adaptive selection between optical and SAR modalities improves performance in challenging conditions like cloud cover while maintaining efficiency by reducing context length compared to feature concatenation.
- Analysis of the Terra-CoT dataset composition shows that combining VQA and captioning data with explicit reasoning steps is necessary to achieve strong generalization across diverse geospatial tasks.
- Qualitative results and failure case analysis reveal that while the model achieves interpretable reasoning traces, its performance remains dependent on segmentation quality and is currently limited by the use of RGB-only inputs which restrict spectral discrimination.