Command Palette
Search for a command to run...
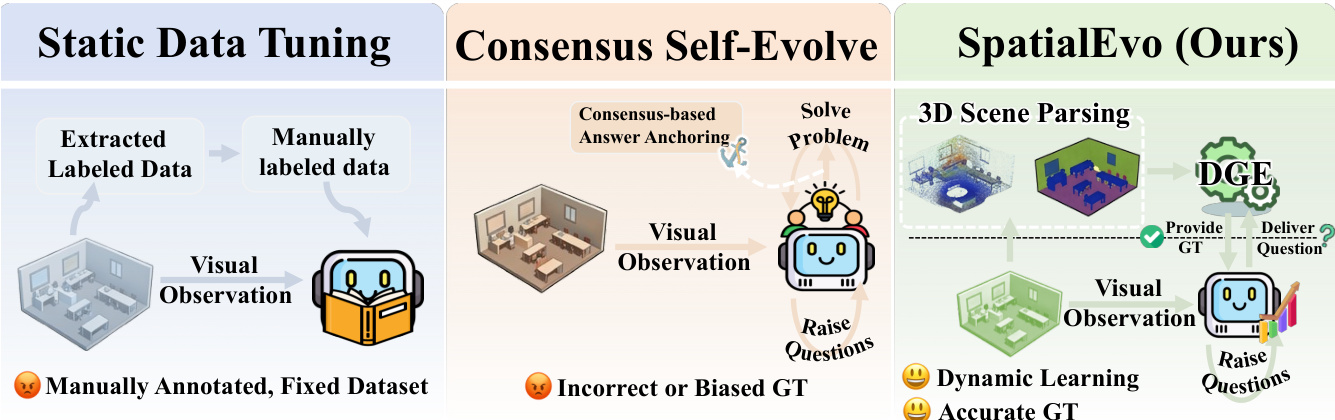
SpatialEvo: 決定論的な幾何学的環境を通じた自己進化型空間インテリジェンス
SpatialEvo: 決定論的な幾何学的環境を通じた自己進化型空間インテリジェンス
概要
ご指定いただいた条件に基づき、提供された英文テキストを、技術的な正確性と学術的な格調を維持した日本語へと翻訳いたしました。3Dシーンにおける空間推論(Spatial reasoning)は、エンボディドAI(embodied intelligence)の中核となる能力であるが、継続的なモデルの向上は、幾何学的アノテーション(geometric annotation)のコストによってボトルネックとなっている。自己進化(self-evolving)パラダイムは有望な道筋を提示しているが、擬似ラベル(pseudo-labels)の構築をモデルの合意(model consensus)に依存しているため、学習プロセスがモデル自身の幾何学的な誤りを修正するのではなく、むしろ強化してしまうという問題がある。我々は、この制限を回避できる、3D空間推論に固有の特性を特定した。それは、「Ground truth(正解)は基礎となる幾何学構造から決定論的な帰結として導き出されるものであり、モデルを介在させることなく、ポイントクラウド(point clouds)とカメラポーズ(camera poses)から正確に計算可能である」という点である。この知見に基づき、我々は「Deterministic Geometric Environment(DGE:決定論的幾何環境)」を中心とした、3D空間推論のための自己進化フレームワークである「SpatialEvo」を提案する。DGEは、明示的な幾何学的検証ルールに基づき、16の空間推論タスクカテゴリを定式化し、アノテーションのない3Dシーンを「ノイズゼロのインタラクティブなオラクル(interactive oracles)」へと変換することで、モデルの合意に代わる客観的な物理的フィードバックを提供する。DGEの制約下において、単一の共有パラメータを持つポリシーが、質問者(questioner)と解答者(solver)の両方のロール(role)を横断して共進化(co-evolve)する。質問者はシーンの観測に基づいた物理的に妥当な空間的な質問を生成し、解答者はDGEによって検証されたground truthに対して正確な回答を導き出す。さらに、タスク適応型スケジューラ(task-adaptive scheduler)が、モデルの最も脆弱なカテゴリに対して内因的に学習を集中させることで、手動設計を介さずに動的なカリキュラムを生成する。9つのbenchmarkにわたる実験の結果、SpatialEvoは3Bおよび7Bのスケールにおいて最高平均スコアを達成した。空間推論のbenchmarkにおいて一貫した向上を示し、かつ一般的な視覚理解(general visual understanding)の性能を低下させることなく、その有効性を実証した。
One-sentence Summary
The authors propose SpatialEvo, a self-evolving framework for 3D spatial reasoning that utilizes a Deterministic Geometric Environment to replace error-prone model consensus with objective physical feedback, enabling a shared-parameter policy to co-evolve across questioner and solver roles using zero-noise interactive oracles in unannotated 3D scenes.
Key Contributions
- The paper introduces SpatialEvo, a self-evolving framework for 3D spatial reasoning that replaces error-prone model consensus with deterministic physical feedback.
- This work develops the Deterministic Geometric Environment (DGE), which formalizes 16 spatial reasoning task categories and uses point clouds and camera poses to convert unannotated scenes into zero-noise interactive oracles.
- The method employs a single shared-parameter policy that co-evolves as both a questioner and a solver, a process that demonstrates significant performance gains across multiple spatial reasoning benchmarks.
Introduction
Effective 3D spatial reasoning is essential for embodied intelligence, yet progress is often hindered by the high cost of geometric annotations and the limitations of static datasets. Existing self-evolution methods typically rely on model consensus to generate pseudo-labels, which can reinforce a model's own geometric errors rather than correcting them. The authors leverage the deterministic nature of 3D geometry to overcome this, introducing SpatialEvo. This framework utilizes a Deterministic Geometric Environment (DGE) to compute exact ground truth from point clouds and camera poses, replacing unreliable model voting with objective physical feedback. By using a single policy that co-evolves as both a questioner and a solver, SpatialEvo creates a dynamic, task-adaptive curriculum that improves spatial reasoning without manual intervention.
Dataset

Dataset Overview
The authors utilize a pre-filtered multi-source visual context pool designed for online Reinforcement Learning (RL). The dataset is structured as follows:
-
Composition and Sources
- The pool consists of 4,365 total contexts derived from the training splits of ScanNet, ScanNet++, and ARKitScenes.
- Data is organized into three distinct modalities: scene-level multi-frame contexts, image-pair contexts, and single-image contexts.
-
Filtering and Quality Control
- Scene-level contexts: Filtered to ensure high grounded visible object counts and low zero-visibility ratios.
- Image-pair contexts: Required to contain at least three shared visible objects across frames and a minimum of five visible objects per frame.
- Single-image contexts: Required to include at least six visible objects.
-
Data Usage and Training Strategy
- Mixture Ratios: The context pool is balanced by modality based on the number of supported task types, resulting in an approximate 6:7:3 ratio for scene-level, image-pair, and single-image inputs.
- Sampling Logic: To prevent data redundancy, the authors sample a limited number of contexts per video, specifically no more than three per modality.
- Online Generation: During training, the policy model receives raw image contexts as input, while both question and answer generation are performed online.
Method
The SpatialEvo framework, as illustrated in the figure below, introduces a novel architecture for spatial reasoning through a co-evolutionary paradigm that integrates a deterministic geometric environment with a shared vision-language policy model. The framework operates as a closed-loop system where a single policy model, parameterized by πθ, dynamically assumes two complementary roles: a Questioner and a Solver. The Questioner generates spatially grounded reasoning questions from visual observations, while the Solver predicts answers to these questions, with both roles operating under the hard constraints of geometric ground truth provided by the Deterministic Geometric Environment (DGE). This design establishes a continuous self-reinforcement loop, where the Questioner's exploration of spatial boundaries is corrected by the Solver's interaction with the DGE's absolute ground truth, thereby enabling mutual knowledge reinforcement and the emergence of robust spatial intelligence.
The core of this framework is the Deterministic Geometric Environment (DGE), which functions as a Geometric Oracle to provide noise-free feedback. The DGE receives natural language questions from the policy model and maps them to the underlying 3D scene assets—comprising dense point clouds and camera pose sequences—to perform objective verification and compute exact ground-truth answers. This process is implemented through a tightly coupled pipeline consisting of two primary components: task-specific geometric validation rule sets and an automated verification pipeline. The validation rule sets decompose each of the 16 spatial reasoning tasks into executable atomic criteria, ensuring that questions are valid along dimensions of premise consistency, inferential solvability, and geometric degeneracy filtering. For instance, a question about relative direction requires that the referenced frames are valid and that sufficient viewpoint disparity exists. The automated verification pipeline then executes this logic in three stages: first, it parses the free-form question using a lightweight LLM to extract structured entities; second, it validates the extracted entities against the task-specific rule set; and third, for valid questions, it performs precise geometric computation to synthesize the ground truth. This paradigm replaces unreliable model-based judgments with programmatic physical computation, ensuring that every gradient update for the policy model is anchored to objective physical laws.
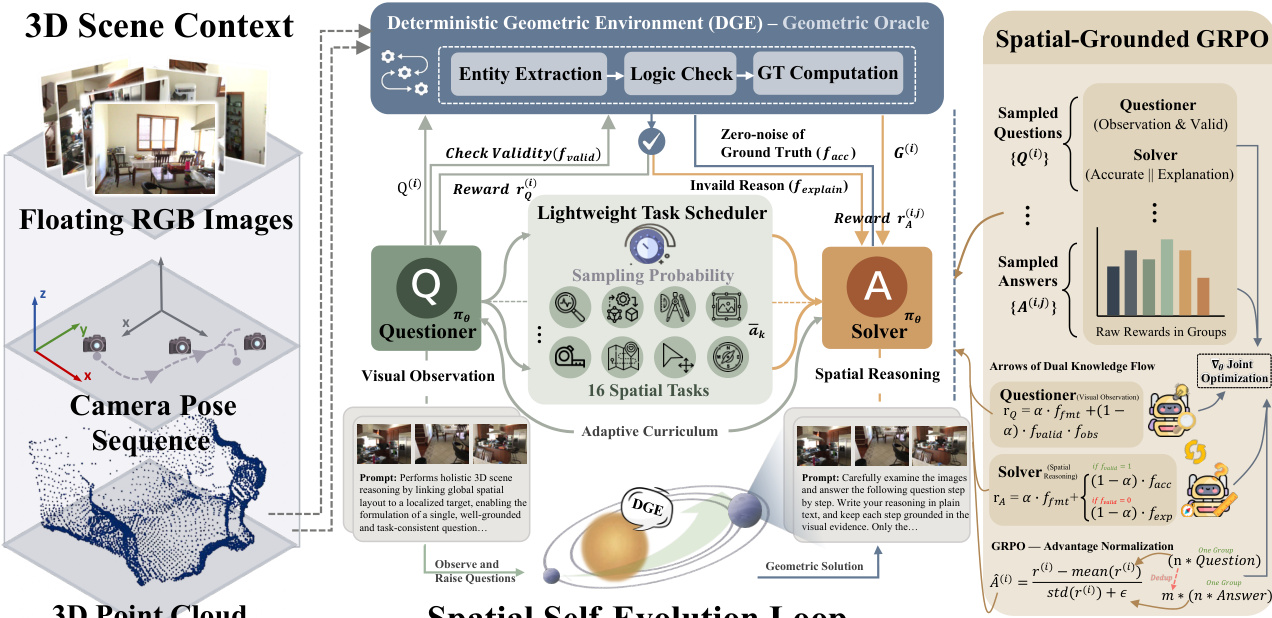
The co-evolution of the Questioner and Solver is driven by a spatial-grounded policy co-evolution mechanism based on the GRPO algorithm. This mechanism employs a single policy model that alternates between the two roles via role-conditioned prompting. The task scheduler, which is a lightweight component, dynamically adjusts the training curriculum by sampling tasks based on the Solver's historical performance. It first infers the feasible task set for the current scene and then assigns sampling weights inversely proportional to the historical effective accuracy of each task category, ensuring that the model focuses on its current cognitive weak spots. This creates a fully adaptive, endogenously driven curriculum. The training procedure involves the Questioner generating a batch of candidate questions, which are then verified by the DGE. Valid questions are passed to the Solver, which independently generates answers and receives rewards based on accuracy. Invalid questions also contribute to learning, as the Solver is required to generate an explanation for the rejection reason, which is scored by a lightweight LLM judge. The reward functions are carefully designed to promote high-quality, valid reasoning. For the Questioner, the reward combines format compliance with a coupled term of geometric validity and visual observation quality, which acts as a critical gating mechanism. For the Solver, the reward is structured to provide meaningful signals for both valid and invalid questions, ensuring that the model learns not only to answer correctly but also to understand the rules and constraints that define valid spatial queries.

The framework's design includes several key components to ensure robustness and interpretability. The DGE's automated verification pipeline includes a deduplication-aware statistics system that maintains a weighted count of unique semantic question signatures to preserve curriculum consistency. The questioner prompt templates are task-conditioned, with scene-level, single-image, and image-pair templates that guide the model to generate observations with a global-to-local flow. The invalid-question explanation judge prompt, which is used to score the Solver's explanations for rejected questions, is designed to prefer the simulator's authoritative failure reason over fluent but unsupported explanations. This ensures that the learning signal for invalid questions is anchored to the DGE's structured rejection evidence, teaching the model which questions should not be asked and why. All auxiliary language model calls, including entity extraction and explanation judging, are unified to a single GPT-OSS-120B backend to control system complexity and ensure consistency. This comprehensive design enables the model to develop a deep, grounded understanding of spatial relationships through continuous interaction with a physically consistent environment.
Experiment
SpatialEvo is evaluated across nine benchmarks to validate its ability to improve 3D spatial reasoning through a self-evolving reinforcement learning framework. The experiments compare the proposed method against static data tuning and existing self-supervised approaches, while ablation studies isolate the benefits of the Deterministic Geometric Environment and the adaptive task scheduler. The results demonstrate that providing exact physical feedback through programmatic verification enables superior spatial intelligence and emergent curriculum learning without degrading general visual capabilities.
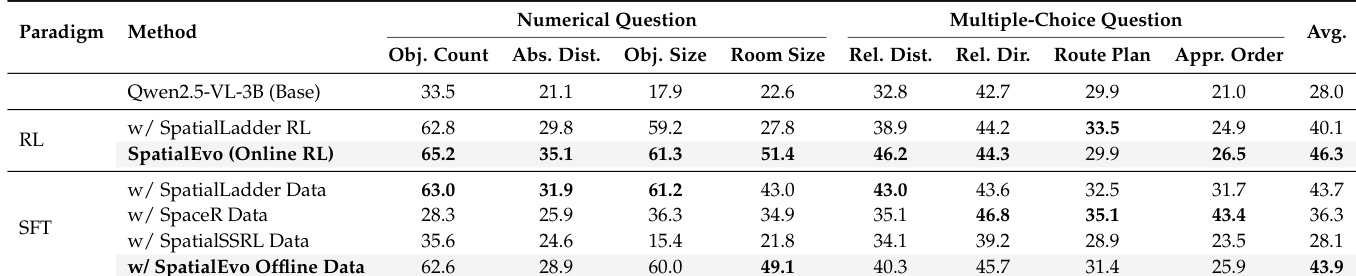
The the the table compares different training paradigms for spatial reasoning, showing that the online reinforcement learning method achieves the highest average score across multiple task categories. The results highlight the effectiveness of the proposed method in improving performance on numerical and multiple-choice questions compared to static data tuning approaches. The online reinforcement learning method outperforms static data tuning methods across all task categories. The proposed method achieves the highest average score, indicating superior performance in spatial reasoning tasks. Static data tuning methods show lower performance, particularly in numerical and multiple-choice question categories.
The the the table lists key hyperparameters used in the training process, including settings for gradient accumulation, learning rate, and data processing. These parameters are part of the reinforcement learning configuration for the model's training pipeline. Training uses gradient accumulation with a step count of 4 and a learning rate of 1e-6. The model employs flash attention for efficient computation and processes images with a maximum pixel size of 150,528. Training involves 4 epochs and uses tensor parallelism with a size of 2.

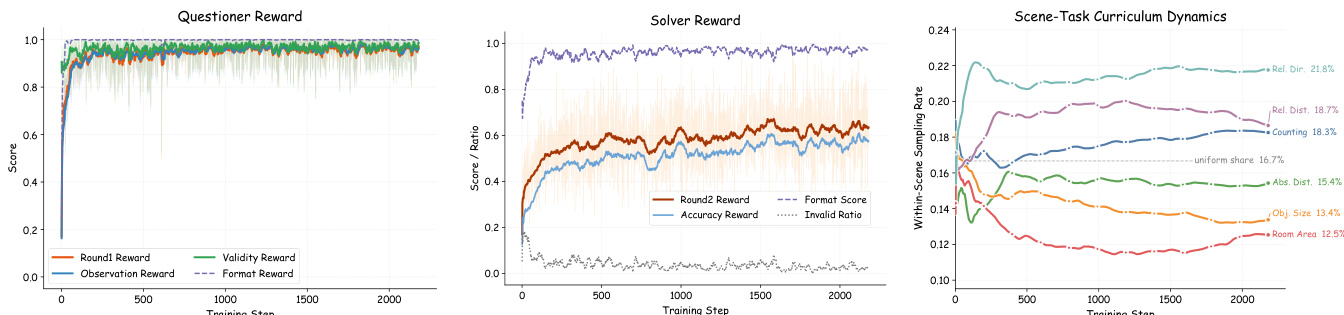
The figures illustrate the training dynamics of SpatialEvo, showing the evolution of questioner and solver rewards and the adaptive curriculum development. Results show that the questioner quickly learns to generate valid questions, while the solver's accuracy improves and invalid responses decrease. The adaptive scheduler dynamically adjusts task sampling rates, focusing on harder categories as training progresses. The questioner reward stabilizes near 1.0, indicating rapid learning of valid question generation. Solver accuracy improves and the invalid ratio declines, reflecting internalization of geometric reasoning. The adaptive scheduler up-weights harder tasks and down-weights easier ones, creating an endogenous curriculum.
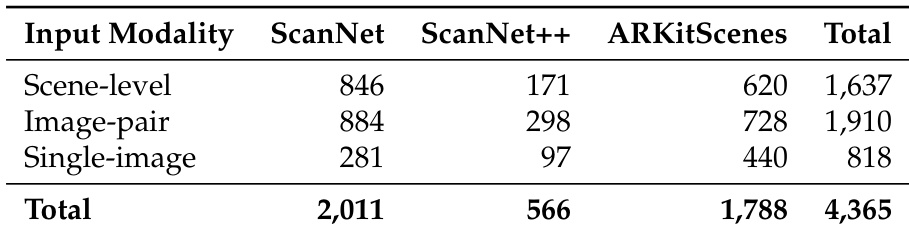
The the the table presents a breakdown of input modalities across three 3D scene datasets: ScanNet, ScanNet++, and ARKitScenes. It shows the number of scene-level, image-pair, and single-image inputs for each dataset, along with their totals, indicating the scale and distribution of data sources used in the experiments. The datasets differ in the number of scene-level and image-pair inputs, with ScanNet having the highest counts in both categories. ARKitScenes contributes more single-image inputs compared to the other datasets. The total number of inputs across all modalities and datasets is 4,365, with ScanNet having the largest contribution overall.
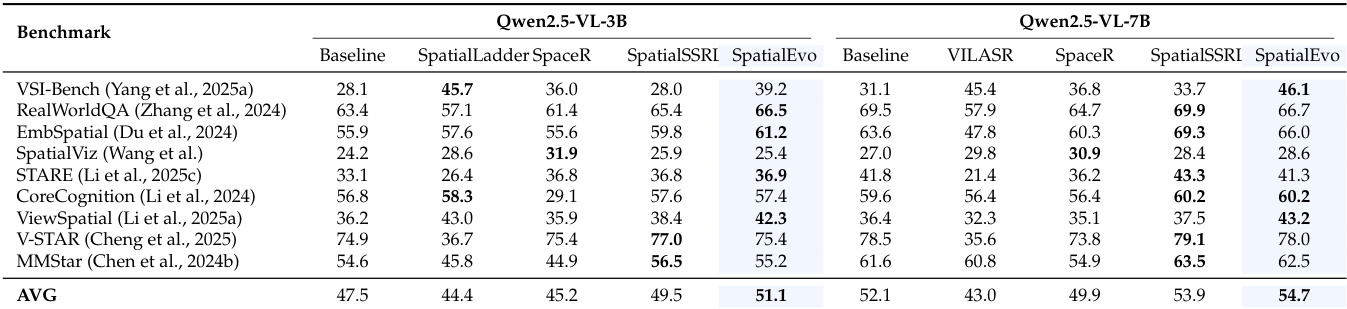
Results show that SpatialEvo achieves the highest average score across multiple benchmarks for both model sizes, outperforming all baselines. The framework demonstrates consistent gains in spatial reasoning tasks while maintaining competitive performance on general visual understanding benchmarks. SpatialEvo achieves the highest average score on all evaluated benchmarks for both model scales. SpatialEvo outperforms all baselines on spatial reasoning benchmarks, with notable improvements on VSI-Bench and EmbSpatial. SpatialEvo maintains competitive performance on general visual understanding tasks, showing no degradation compared to baseline models.
The evaluation compares various training paradigms and benchmarks to validate the effectiveness of the SpatialEvo framework in enhancing spatial reasoning. Results demonstrate that the online reinforcement learning method significantly outperforms static data tuning across multiple task categories, particularly in numerical and multiple-choice reasoning. Furthermore, the adaptive curriculum development successfully facilitates the internalization of geometric reasoning while maintaining competitive performance on general visual understanding tasks.