HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
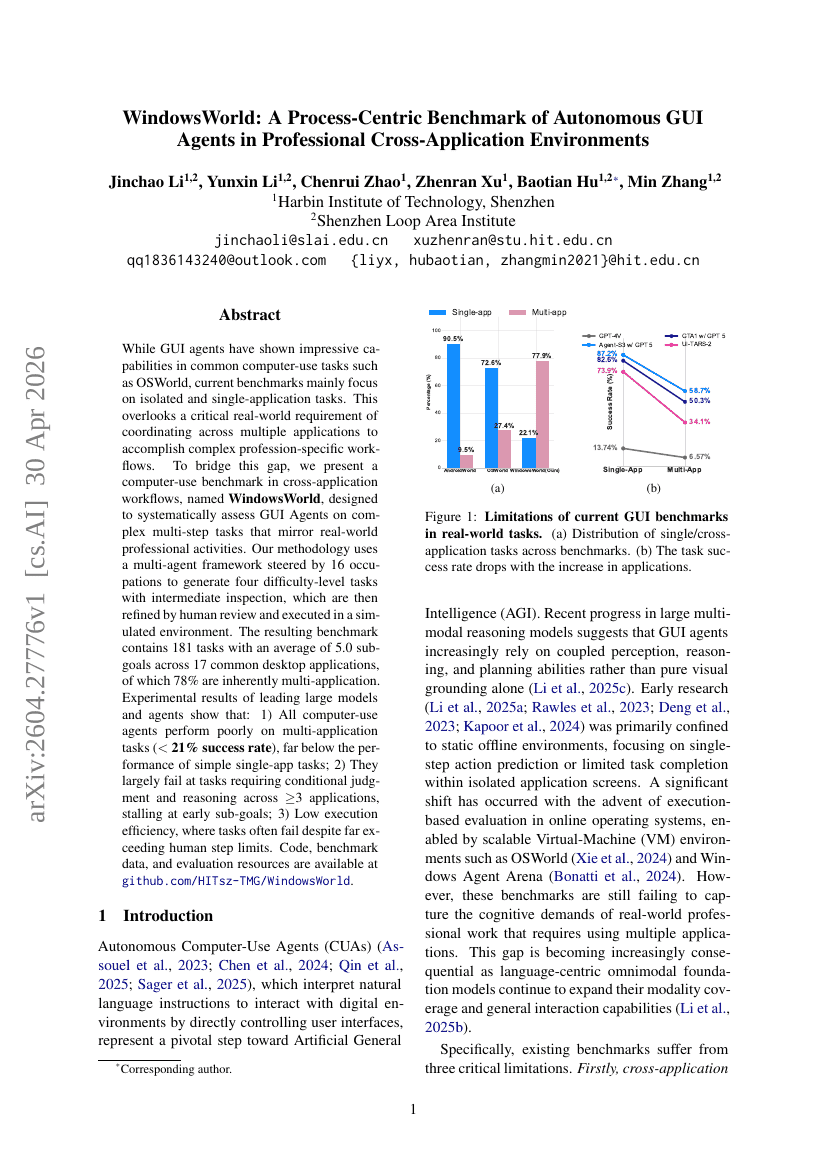
WindowsWorld:専門的なクロスアプリケーション環境における自律型GUIエージェントのためのプロセス中心ベンチマーク

ハルシネーションは信頼を損なう;メタ認知が次なる道である

















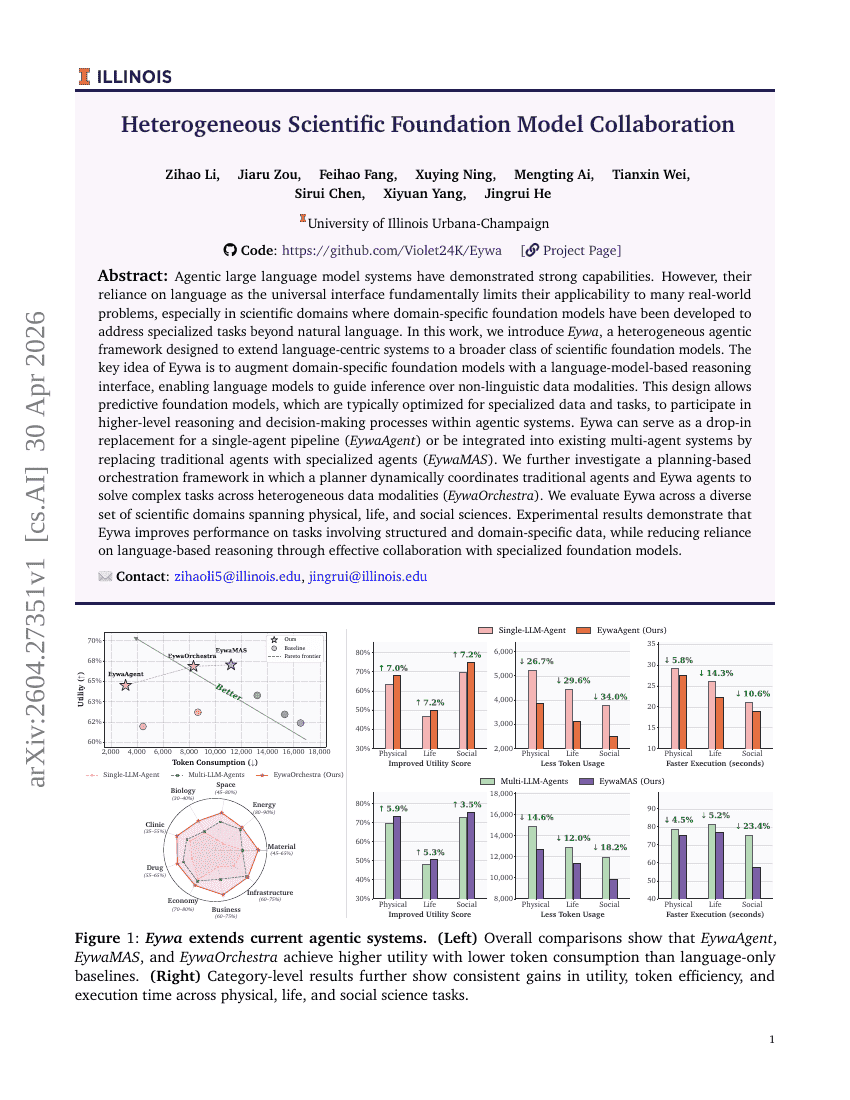










WindowsWorld:専門的なクロスアプリケーション環境における自律型GUIエージェントのためのプロセス中心ベンチマーク
ハルシネーションは信頼を損なう;メタ認知が次なる道である
X2SAM: 画像および動画における任意のセグメンテーション
OpenSeeker-v2:情報豊富で高難易度のトラジェクトリを用いた検索agentの限界突破
PRISM: マルチモーダル強化学習のためのブラックボックスオンポリシー蒸留による事前整列
ARIS: 敵対的多エージェント協働による自律的研究
ProgramBench:言語モデルはゼロからプログラムを再構築できるか
GPU上における効率的な加速されたグラフ編集距離計算
危機報道のためのソーシャルメディアの状況信号に関するLLMベースの不確実性評価
カノニカルLST: Tezosのためのプロトコルネイティブリクイッドステーキングソリューション
知性と実行の分離:モデルコンテキストプロトコル用のワークフローエンジン
テキストからビデオへの検索におけるパフォーマンスの頭打ちの理解:包括的な経験的および言語学的分析
永続的視覚記憶:LVLMsにおける深層生成のための知覚の持続
EnergAIzer: AIワークロードに対する高速かつ高精度なGPU電力推定フレームワーク
画像編集における検証者ベースの強化学習の活用
RoundPipeを用いた複数の消費者向けGPUでの効率的なトレーニング
外見的生成を汎用的な対話型ヒューマノイド制御として捉えるExoActor
Co-Evolving Policy Distillation
新しい時代のビジュアル生成:アトミックマッピングからエージェント型ワールドモデリングへの進化
異種科学基盤モデルの協調
拡散テンプレート:制御可能な拡散のための統一プラグインフレームワーク
RADIO-ViPE: 動的環境におけるオープンボキャブラリセマンティックSLAMのためのオンライン密結合マルチモーダル融合
ClawGym:効果的なClawエージェントを構築するためのスケーラブルなフレームワーク
TIDEの変革:拡散大規模言語モデルのためのアーキテクチャ横断的蒸留
潜在蒸留による大規模言語モデルの探索
GLM-5V-Turbo:マルチモーダルエージェントのためのネイティブファウンデーションモデルへの道
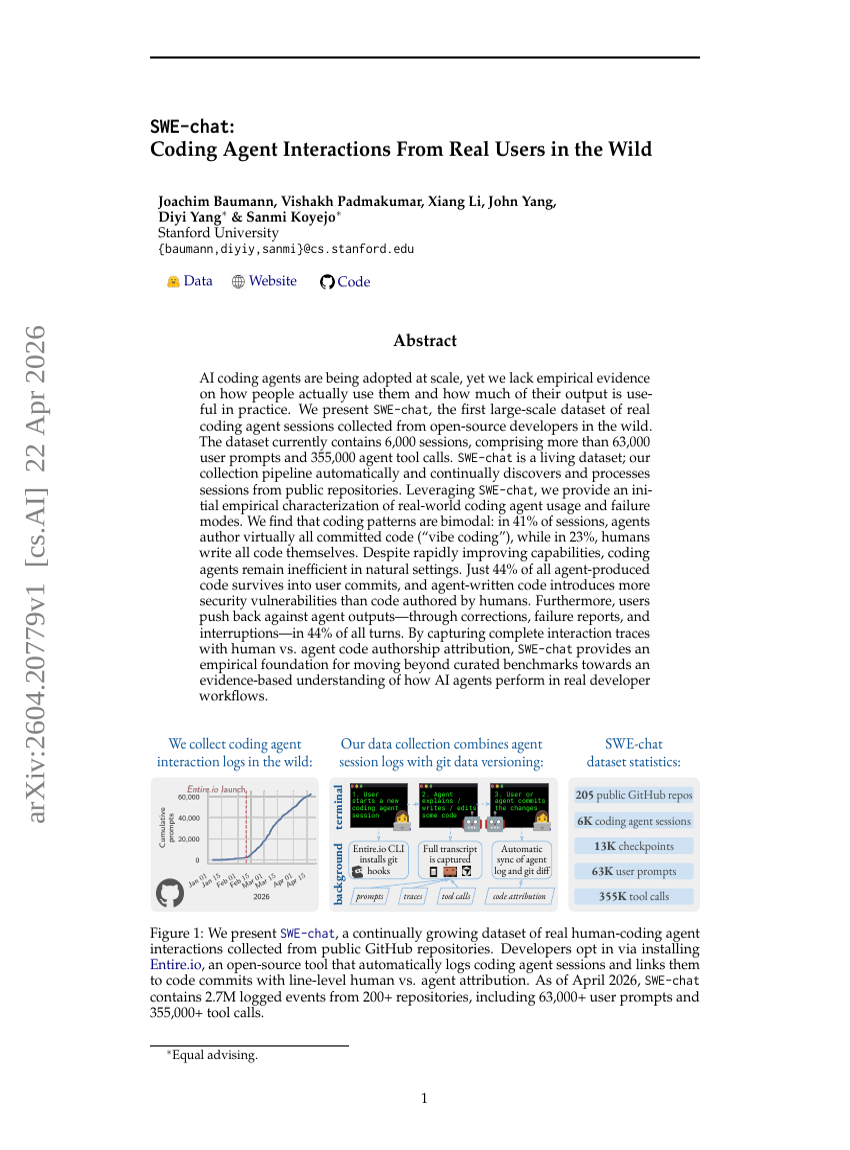
SWE-chat: 野外環境における実ユーザーからのコーディングエージェントの対話
AdaExplore: 効率的なカーネル生成のための失敗駆動適応および多様性維持探索
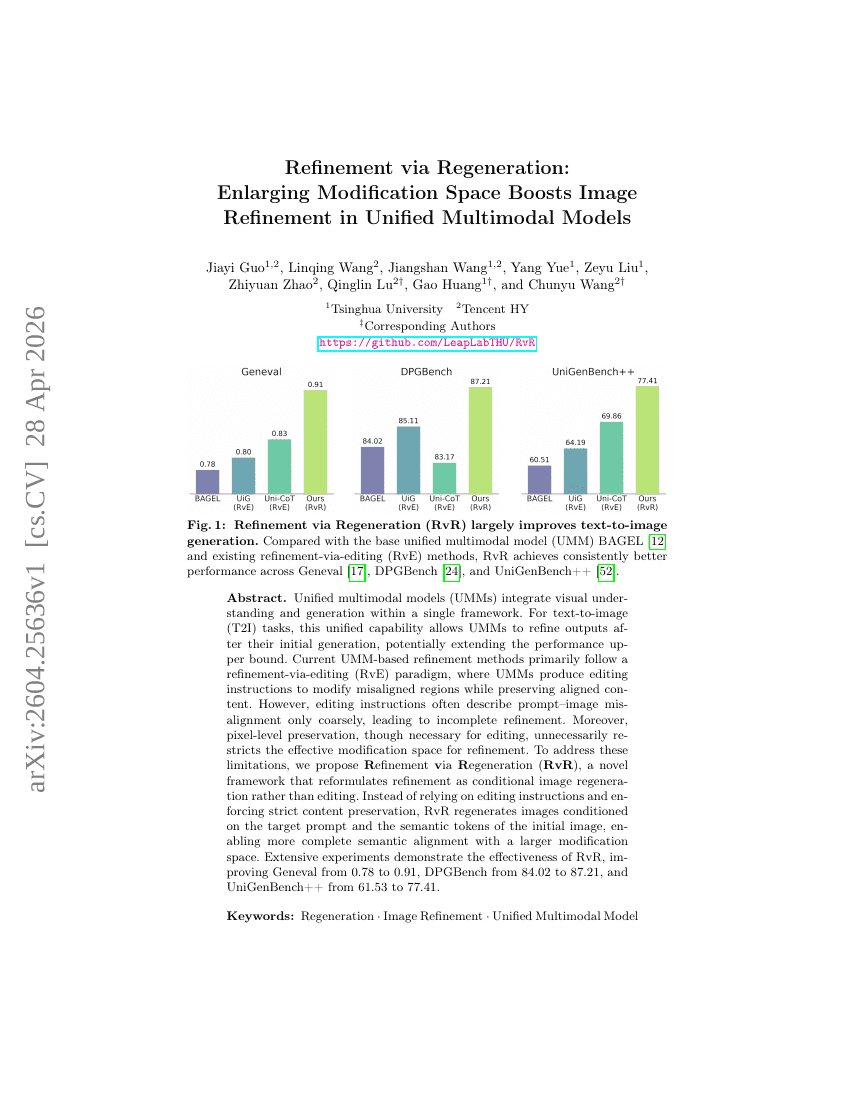
再生による精緻化:修正空間の拡大が統一マルチモーダルモデルにおける画像精緻化を促進する
AutoResearchBench: 複雑な科学的文献検索におけるAIエージェントのベンチマーク
Meta-CoT: 画像編集における粒度と汎化能力の向上
DV-World: 現実世界でのデータ可視化エージェントの評価ベンチマーク
X2SAM: 画像および動画における任意のセグメンテーション
OpenSeeker-v2:情報豊富で高難易度のトラジェクトリを用いた検索agentの限界突破
PRISM: マルチモーダル強化学習のためのブラックボックスオンポリシー蒸留による事前整列
ARIS: 敵対的多エージェント協働による自律的研究
ProgramBench:言語モデルはゼロからプログラムを再構築できるか
GPU上における効率的な加速されたグラフ編集距離計算
危機報道のためのソーシャルメディアの状況信号に関するLLMベースの不確実性評価
カノニカルLST: Tezosのためのプロトコルネイティブリクイッドステーキングソリューション
知性と実行の分離:モデルコンテキストプロトコル用のワークフローエンジン
テキストからビデオへの検索におけるパフォーマンスの頭打ちの理解:包括的な経験的および言語学的分析
永続的視覚記憶:LVLMsにおける深層生成のための知覚の持続
EnergAIzer: AIワークロードに対する高速かつ高精度なGPU電力推定フレームワーク
画像編集における検証者ベースの強化学習の活用
RoundPipeを用いた複数の消費者向けGPUでの効率的なトレーニング
外見的生成を汎用的な対話型ヒューマノイド制御として捉えるExoActor
Co-Evolving Policy Distillation
新しい時代のビジュアル生成:アトミックマッピングからエージェント型ワールドモデリングへの進化
異種科学基盤モデルの協調
拡散テンプレート:制御可能な拡散のための統一プラグインフレームワーク
RADIO-ViPE: 動的環境におけるオープンボキャブラリセマンティックSLAMのためのオンライン密結合マルチモーダル融合
ClawGym:効果的なClawエージェントを構築するためのスケーラブルなフレームワーク
TIDEの変革:拡散大規模言語モデルのためのアーキテクチャ横断的蒸留
潜在蒸留による大規模言語モデルの探索
GLM-5V-Turbo:マルチモーダルエージェントのためのネイティブファウンデーションモデルへの道
SWE-chat: 野外環境における実ユーザーからのコーディングエージェントの対話
AdaExplore: 効率的なカーネル生成のための失敗駆動適応および多様性維持探索
再生による精緻化:修正空間の拡大が統一マルチモーダルモデルにおける画像精緻化を促進する
AutoResearchBench: 複雑な科学的文献検索におけるAIエージェントのベンチマーク
Meta-CoT: 画像編集における粒度と汎化能力の向上
DV-World: 現実世界でのデータ可視化エージェントの評価ベンチマーク