Command Palette
Search for a command to run...
GlobalSplat: Global Scene Tokensを用いた効率的なFeed-Forward 3D Gaussian Splatting
GlobalSplat: Global Scene Tokensを用いた効率的なFeed-Forward 3D Gaussian Splatting
Roni Itkin Noam Issachar Yehonatan Keypur Yehonatan Keypur Anpei Chen Sagie Benaim
概要
ご指定いただいた翻訳基準に基づき、提供されたテキストを日本語に翻訳いたしました。プリミティブ(primitives)の効率的な空間配置は、表現のコンパクトさ、再構成速度、およびレンダリングの忠実度の相乗効果を直接決定づけるため、3D Gaussian Splattingの基盤となります。従来の解決策は、反復的な最適化に基づくものか、あるいはfeed-forwardなinferenceに基づくものかにかかわらず、これら目標間の重大なトレードオフに悩まされてきました。その主な要因は、グローバルなシーンへの認識を欠いた、局所的かつヒューリスティックな配置戦略に依存していることにあります。具体的には、現在のfeed-forwardな手法の多くは、pixel-alignedまたはvoxel-alignedな手法です。ピクセルをビューに整合した高密度なプリミティブへとunprojectすることで、3Dアセットに冗長性を焼き付けてしまいます。その結果、入力ビューが増えるにつれて表現サイズが増大し、グローバルな一貫性が損なわれやすくなります。この課題に対し、我々は「先に整列させ、後でデコードする(align first, decode later)」という原則に基づいたフレームワーク、GlobalSplatを提案します。本手法は、多視点入力をエンコードし、明示的な3D幾何学をデコードする前に視点間の対応関係を解決する、コンパクトでグローバルな潜在的シーン表現(latent scene representation)を学習します。極めて重要な点は、この定式化により、学習済みのpixel-predictionバックボーンに依存したり、高密度なベースラインから潜在的な特徴量を再利用したりすることなく、コンパクトでグローバルに一貫した再構成が可能になることです。また、デコード容量を段階的に増加させるcoarse-to-fineな学習カリキュラムを活用することで、GlobalSplatは表現の肥大化(representation bloat)をネイティブに防ぎます。RealEstate10KおよびACIDデータセットにおいて、本モデルはわずか16KのGaussiansを使用しながら、高密度なpipelineが必要とする数よりも大幅に少ない量で、競争力のあるnovel-view synthesis性能を達成し、わずか4MBという軽量なフットプリントを実現しました。さらに、GlobalSplatはベースラインよりも大幅に高速なinferenceを可能にし、単一のforward passにおいて78ミリ秒未満で動作します。プロジェクトページはこちらからご覧いただけます:https://r-itk.github.io/globalsplat/
One-sentence Summary
GlobalSplat is a feed-forward framework that utilizes global scene tokens to learn a compact latent representation before decoding explicit geometry, achieving high-fidelity 3D Gaussian Splatting reconstructions on RealEstate10K and ACID with as few as 16K Gaussians, a 4MB footprint, and inference speeds under 78 milliseconds.
Key Contributions
- The paper introduces GlobalSplat, a feed-forward 3D Gaussian Splatting framework based on an "align first, decode later" principle that aggregates multi-view observations into a compact, fixed-size set of global scene tokens. This approach resolves cross-view correspondences within a global latent representation before decoding explicit 3D geometry to eliminate the redundancy found in dense, view-centric pipelines.
- The method implements a disentangled dual-branch architecture paired with a coarse-to-fine training curriculum that gradually increases decoded capacity. This design prevents representation bloat and enables a stronger quality-efficiency trade-off when reconstructing large-context scenes.
- Experiments on the RealEstate10K and ACID datasets demonstrate that the model achieves competitive novel-view synthesis performance using as few as 16K Gaussians and a 4MB footprint. The framework also provides high efficiency, performing inference in under 78 milliseconds in a single forward pass.
Introduction
Feed-forward 3D Gaussian Splatting (3DGS) aims to generate explicit 3D representations from multiple input views in a single network pass, enabling fast novel-view synthesis without per-scene optimization. However, existing methods typically rely on dense, view-aligned intermediates such as pixel-aligned or voxel-aligned predictions. This design introduces significant redundancy and causes the representation size to inflate as more input views are added, making large-context reconstruction difficult to scale. The authors leverage a "align first, decode later" principle to introduce GlobalSplat, a framework that aggregates multi-view inputs into a compact, fixed set of global latent scene tokens before decoding any explicit geometry. By utilizing a dual-branch iterative attention architecture and a coarse-to-fine training curriculum, GlobalSplat achieves highly competitive reconstruction quality while maintaining an ultra-compact footprint of only 16K Gaussians.
Dataset

Since the provided text only contains implementation details regarding image resizing and cropping rather than the dataset composition, sources, or mixture ratios, the following description focuses on the data processing pipeline:
- Image Preprocessing: During evaluation, the authors resize each image to a height of 256 pixels while maintaining the original aspect ratio. The width is rounded to the nearest multiple of 8 to accommodate the patch size.
- Camera Parameter Adjustment: To maintain spatial accuracy, the intrinsic camera parameters are updated accordingly after the resizing step.
- Cropping and Final Scaling: The pipeline applies a centered square crop to the resized image. If the dimensions are not already correct, a final resize is performed to produce an exact 256 by 256 pixel image.
- Consistency: This deterministic preprocessing workflow is applied identically to both the context and target views.
Method
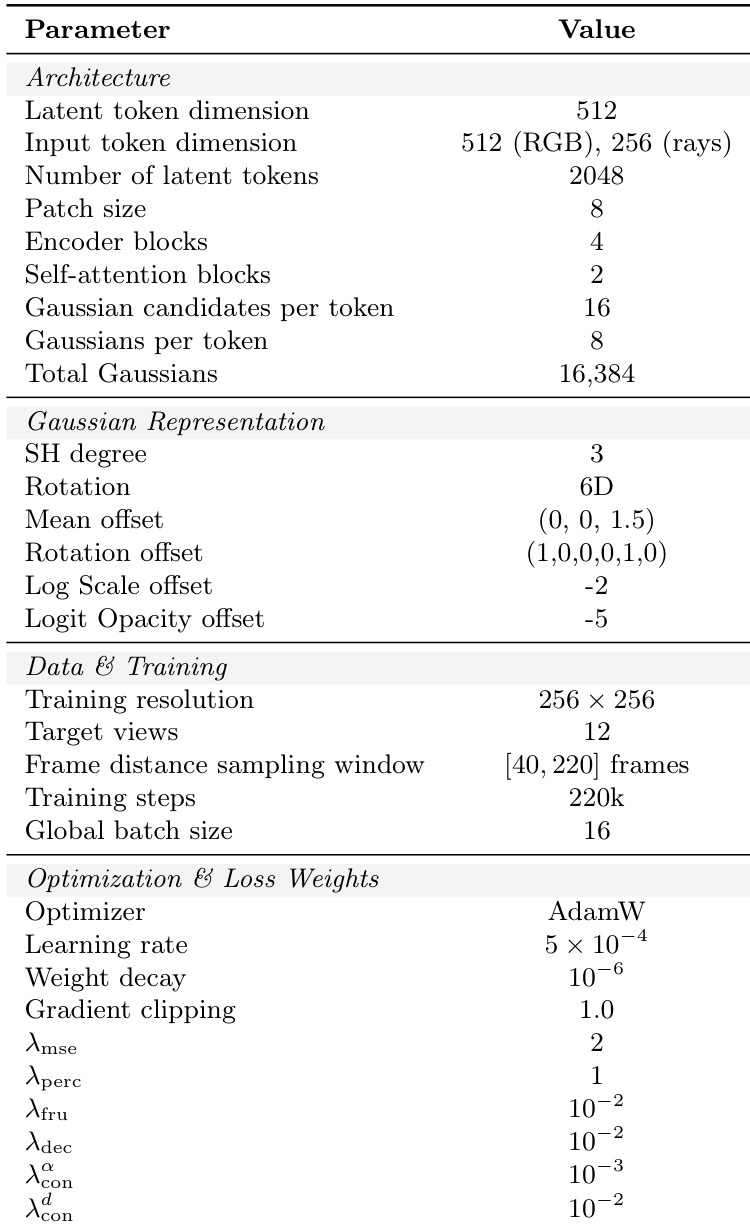
The authors leverage a novel architecture named GlobalSplat, which employs a learnable latent representation to efficiently model 3D scenes. The overall framework operates by first extracting features from input views and then iteratively refining a fixed set of latent scene tokens through a dual-branch attention mechanism before decoding them into explicit 3D Gaussians. The model begins with a view encoder that processes input images to generate patchified features. These features are then used to augment per-patch context by combining patchified Plücker-ray embeddings with a per-view camera code, which explicitly encodes the camera's global context, including absolute position and focal parameters. This augmented context is fed into the core processing pipeline.
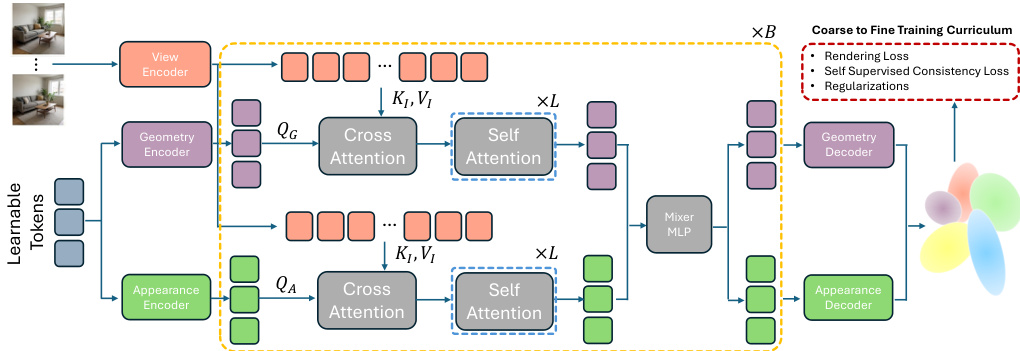
As shown in the figure below, the model initializes a fixed set of M=2048 learnable latent tokens, which serve as the primary representation of the scene. These tokens are processed through a dual-branch encoder consisting of B=4 iterative blocks. Within each block, the tokens are projected into separate geometry and appearance streams. The geometry stream processes queries QG that cross-attend to the multi-view features KI,VI and then self-attend to the global context, while the appearance stream performs a similar operation with queries QA. This architectural disentanglement ensures that geometric structure and appearance are processed independently, preventing texture from masking poor structural predictions. The outputs of the two streams are fused via a mixer MLP to update the latent tokens, which are then passed to the next block.
Following the iterative refinement, the final latent tokens are decoded into the explicit 3D Gaussian representation. This is achieved through two specialized decoders: a geometry decoder that predicts the 3D mean, anisotropic scale, rotation (using a continuous 6D parameterization), opacity, and an importance score, and an appearance decoder that predicts the view-dependent color coefficients using spherical harmonics (SH) of degree 3. The model employs a coarse-to-fine training curriculum to manage the complexity of the representation. Initially, each latent token predicts a fixed set of 16 Gaussian candidates, but only a single representative Gaussian (G=1) is exposed to the renderer. As training progresses, the capacity is incrementally increased by reducing the merging of candidates, ultimately revealing G=8 Gaussians per token. This staged approach ensures that the model first establishes a stable global geometry before refining local details, preventing representation bloat and improving training stability.
Experiment
The proposed method is evaluated against state-of-the-art feed-forward novel view synthesis baselines using the RealEstate10K dataset for primary performance testing and the ACID dataset to assess zero-shot cross-dataset generalization. Ablation studies further validate the effectiveness of the dual-stream architecture, the coarse-to-fine capacity curriculum, and the inclusion of camera metadata. The results demonstrate that the model achieves a superior trade-off between reconstruction quality and representation compactness, providing sharp, artifact-free renderings with significantly lower memory and computational requirements than existing heavy-weight methods.
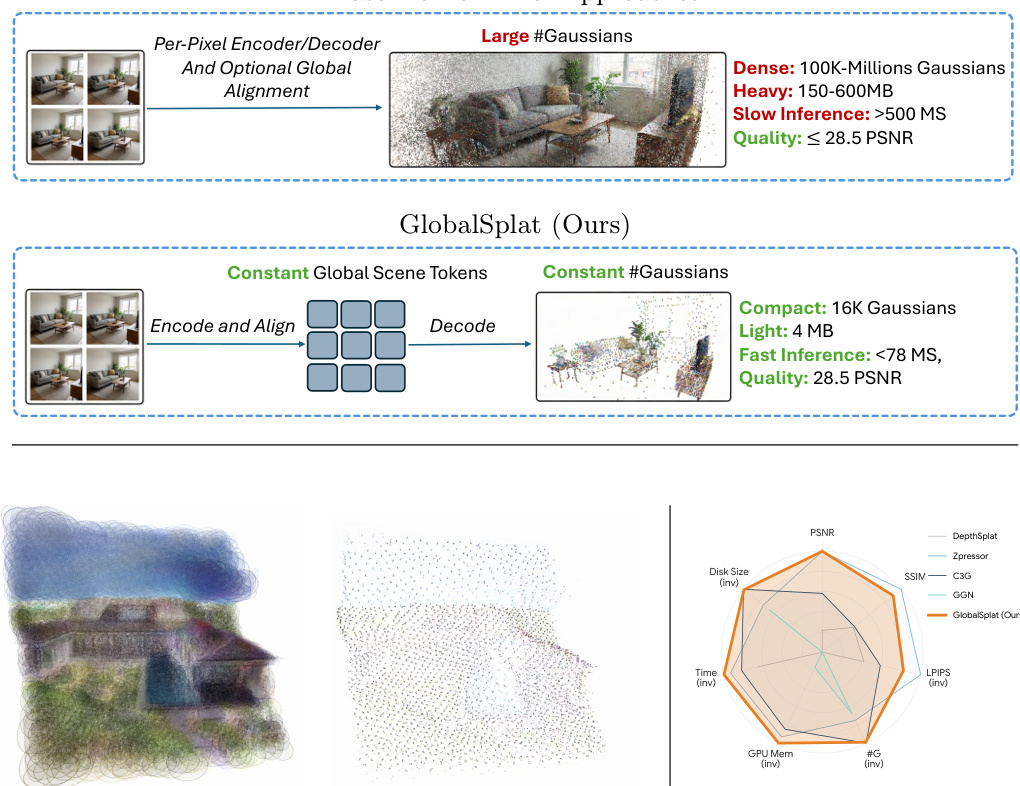
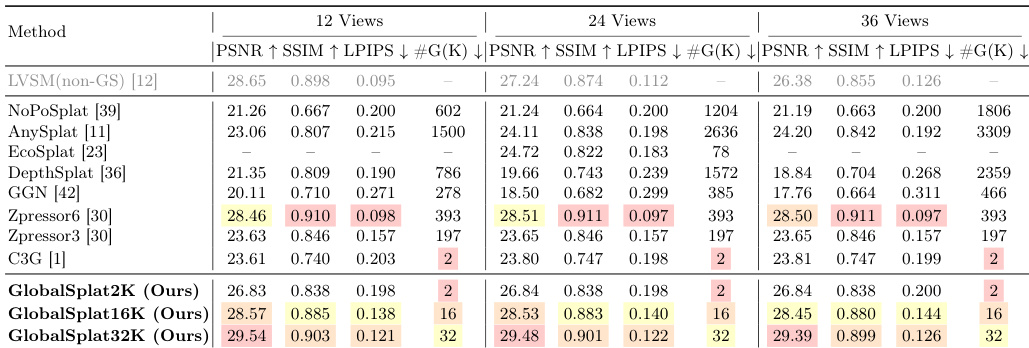
The authors evaluate their method against state-of-the-art feed-forward novel view synthesis baselines on RealEstate10K and ACID datasets. Results show that the proposed method achieves strong reconstruction quality with a compact representation, demonstrating favorable trade-offs between quality and model size, and excels in cross-dataset generalization and computational efficiency. The method achieves competitive reconstruction quality while using a significantly smaller number of Gaussians compared to baseline methods. The approach demonstrates robust cross-dataset generalization, maintaining performance on ACID despite being trained only on RealEstate10K. The method is computationally efficient, requiring the lowest peak GPU memory and fastest inference time among compared methods.
The authors compare their method against state-of-the-art feed-forward novel view synthesis baselines on RealEstate10K, evaluating reconstruction quality, compactness, and efficiency. Results show that their approach achieves competitive image quality with a significantly smaller number of Gaussians compared to other methods, demonstrating a favorable quality-compactness trade-off. The method also maintains strong performance across different numbers of input views and exhibits high computational efficiency. GlobalSplat achieves competitive reconstruction quality while using a fraction of the Gaussians required by other methods. The method maintains consistent performance across 12, 24, and 36 input views, indicating a view-invariant representation. GlobalSplat is the most memory-efficient and fastest method in terms of inference time and disk footprint.
The authors compare the efficiency of their method with several baselines, focusing on peak GPU memory, inference time, and disk size. Results show that their method achieves significantly lower memory usage and faster inference while maintaining a small disk footprint. These efficiency gains are achieved without sacrificing reconstruction quality, highlighting the benefit of a compact representation. The proposed method uses substantially less peak GPU memory and inference time compared to baselines. The method maintains a minimal disk footprint, significantly smaller than all other methods. Efficiency improvements are achieved while preserving high reconstruction quality.

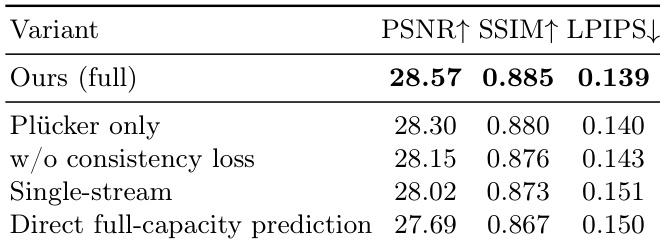
The authors conduct an ablation study to evaluate the impact of different design choices on model performance. Results show that removing the consistency loss or using a single-stream architecture leads to a drop in reconstruction quality, while predicting the full Gaussian capacity from the start also degrades performance. The full model achieves the best results across all metrics. Removing the consistency loss reduces reconstruction quality and increases artifacts Using a single-stream architecture instead of a two-stream design degrades performance Predicting the full Gaussian capacity from the beginning of training leads to worse results than progressive capacity growth
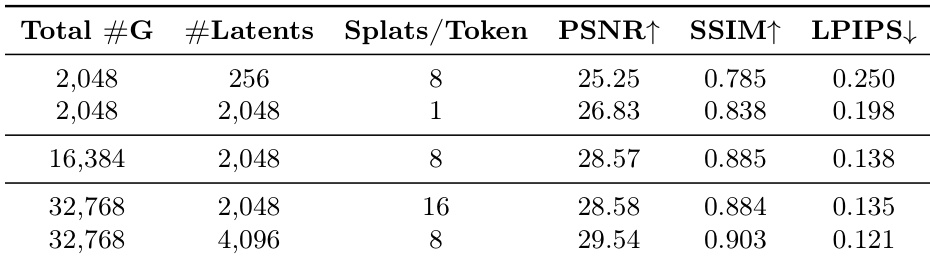
The the the table examines the impact of latent scene representation size and decoder density on reconstruction quality under fixed Gaussian budgets. Results show that increasing the number of latent tokens is more effective than increasing the number of Gaussians per token, with larger latent capacity leading to better performance across metrics. Increasing latent capacity improves reconstruction quality more than increasing Gaussians per token Larger latent representations achieve higher PSNR, SSIM, and lower LPIPS under the same Gaussian budget The trade-off between latent size and decoder density shows diminishing returns for higher decoder density
The proposed method is evaluated against state-of-the-art feed-forward novel view synthesis baselines on the RealEstate10K and ACID datasets to assess reconstruction quality, efficiency, and generalization. Results demonstrate that the approach achieves competitive image quality with a significantly more compact representation, offering superior computational efficiency and robust performance across different datasets and input view counts. Ablation studies and architectural analyses further confirm that the two-stream design, consistency loss, and progressive capacity growth are essential for maintaining high-quality reconstructions while optimizing the trade-off between latent representation size and decoder density.