Command Palette
Search for a command to run...
データや最適化を介さない最大脳損傷:Sign-Bit FlipによるNeural Networkの破壊
データや最適化を介さない最大脳損傷:Sign-Bit FlipによるNeural Networkの破壊
Ido Galil Moshe Kimhi Ran El-Yaniv
概要
ご指定いただいた条件に基づき、提供された英文を専門的な技術論文のスタイルで日本語に翻訳いたしました。【翻訳文】ディープニューラルネットワーク(DNN)は、わずか数ビットのパラメータを反転させるだけで、壊滅的な障害を引き起こす可能性がある。本論文では、データを用いず(data-free)、最適化も必要としない(optimization-free)手法である「Deep Neural Lesion(DNL)」を提案する。DNLは、ネットワーク内の極めて重要なパラメータを特定する手法である。さらに、その改良版として、ランダムな入力に対する1回のforward passとbackward passによってパラメータの選択を精緻化する、シングルパス版の「1P-DNL」を導入する。我々は、この脆弱性が画像分類、物体検出、インスタンスセグメンテーション、そして推論能力を持つLarge Language Models(LLMs)を含む、複数のドメインにわたることを示す。画像分類においては、ImageNet上のResNet-50におけるわずか2ビットの符号ビット(sign bits)の反転が、精度を99.8%低下させる。物体検出およびインスタンスセグメンテーションにおいては、バックボーンにおける1または2ビットの符号反転が、Mask R-CNNおよびYOLOv8-segモデルにおけるCOCO detectionおよびmask APを崩壊させる。言語モデリングにおいては、異なるExpertへの2ビットの符号反転により、Qwen3-30B-A3B-Thinkingの精度が78%から0%へと低下する。また、脆弱な符号ビットのごく一部を選択的に保護することで、このような攻撃に対する実用的な防御策となり得ることも示す。
One-sentence Summary
By introducing Deep Neural Lesion (DNL) and its single-pass variant 1P-DNL, the authors present a data-free and optimization-free method to disrupt neural networks via sign-bit flips that achieves catastrophic failure in image classification, object detection, and large language models while offering a practical defense through selective bit protection.
Key Contributions
- The paper introduces Deep Neural Lesion (DNL), a data-free and optimization-free method for locating critical parameters, along with an enhanced single-pass variant called 1P-DNL that refines parameter selection using one forward and backward pass on random inputs.
- This work demonstrates that flipping a minimal number of sign bits can catastrophically disrupt diverse architectures, including ResNet-50 on ImageNet, Mask R-CNN and YOLOv8-seg on COCO, and reasoning large language models like Qwen3-30B-A3B-Thinking.
- The authors propose a targeted defense mechanism that selectively protects a small fraction of vulnerable sign bits to substantially improve model robustness against these bit-flip attacks.
Introduction
As deep neural networks (DNNs) are increasingly deployed in safety-critical systems like autonomous driving and large language models, understanding their vulnerability to hardware and software exploits is essential. While existing weight-space attacks can disrupt models, they typically require significant computational overhead, iterative optimization, or access to large datasets to compute gradients.
The authors introduce Deep Neural Lesion (DNL), a lightweight, data-agnostic, and optimization-free method that identifies and flips critical sign bits to induce catastrophic model failure. By leveraging a magnitude-based heuristic and an enhanced single-pass variant (1P-DNL), the authors demonstrate that flipping as few as one or two sign bits can reduce the accuracy of ResNet-50, YOLOv8, and Mixture-of-Experts language models to near zero. This approach bypasses the need for training data or continuous inference, making it a highly stealthy and potent threat in real-world deployment scenarios.
Method
The authors leverage a targeted sign-bit flipping attack, termed DNL (Deep Neural Lesion), to expose critical vulnerabilities in deep neural networks (DNNs) by demonstrating that flipping a small number of specific sign bits can catastrophically degrade model performance. The attack is entirely data-agnostic, requiring no knowledge of training data, domain-specific inputs, or synthetic data. The framework is designed to identify and manipulate the most critical parameters within a model's weight space, focusing on the sign bit (MSB) of the floating-point representation, which induces an immediate and often severe change in a parameter's value. This approach is motivated by the observation that while random sign-bit flips have negligible impact on performance, strategically selected flips can lead to drastic accuracy reductions.
The core of the DNL attack involves two primary strategies: a "Pass-free" variant and a "1-Pass" variant. The Pass-free attack operates without any additional computational passes beyond the model's forward computation. It relies on a simple, heuristic-based selection of parameters to flip. The authors first identify that parameters with large magnitudes are disproportionately sensitive to sign flips, drawing an analogy to magnitude-based pruning in the literature. This leads to a magnitude-based strategy where the top-k largest parameters in absolute value are selected for flipping. Furthermore, for convolutional neural networks (CNNs), the attack is constrained to flip at most one sign bit per convolutional kernel. This constraint is crucial because flipping multiple bits within the same kernel often results in partial cancellation of the perturbation, reducing the overall impact. This is illustrated in the figure below, where a single sign flip in a Sobel filter severely disrupts its edge-detection capability, whereas two sign flips can partially offset the damage, allowing the filter to retain some functionality.
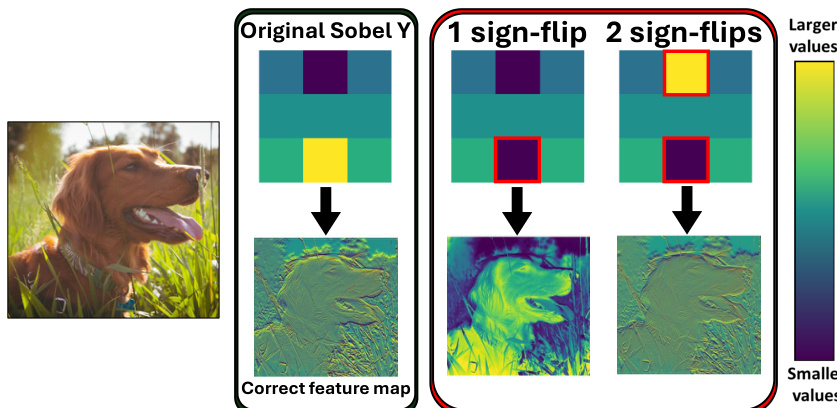
The attack's effectiveness is further enhanced by targeting parameters in the early layers of the network. The authors argue that early-layer parameters, particularly in CNNs, are critical for extracting fundamental features such as edges and textures. A perturbation in these layers propagates through the entire network, causing compounding errors that lead to severe performance degradation. This is analogous to early lesions in the visual system causing total blindness. The figure below provides a visual demonstration of this concept, showing how flipping the sign bit of a weight in the first convolutional kernel of a DNN leads to a large disruption in the learned feature maps, rendering the network unable to correctly detect edges.

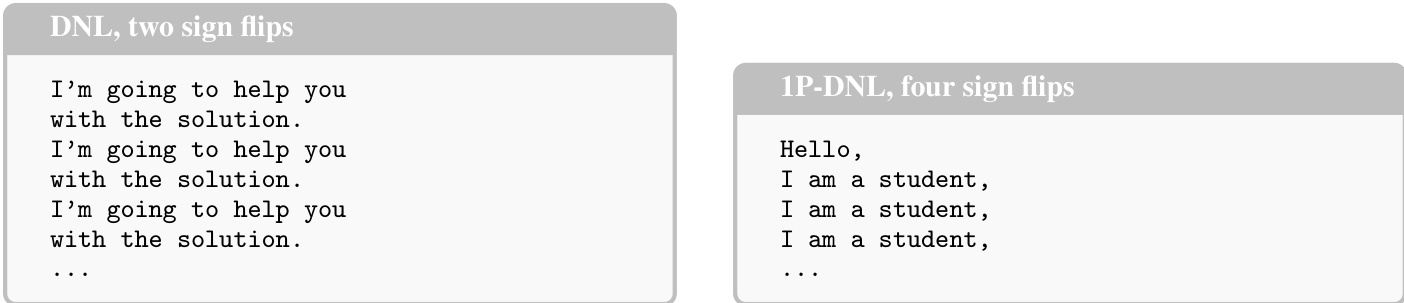
To refine the attack under a limited computational budget, the authors propose the 1P-DNL (1-Pass DNL) variant, which uses a single forward and backward pass with random inputs to compute a more sophisticated importance score for each parameter. This score, termed a hybrid importance score, combines magnitude-based saliency with second-order information derived from the model's gradients and Hessian. The formula for this score is defined as S(θi)=α∣θi∣+β∂θi∂Rθi+21Hiiθi2+∑j=iHijθiθj, where R is the model's loss or output on a random input. In practice, the Hessian is approximated diagonally, and Hii is replaced by (∂θi∂R)2 for computational efficiency. This approach allows the attack to identify parameters that are most sensitive to perturbations, not just those with the largest magnitude. The results, visualized in the figure below, show that this enhanced method is significantly more potent than the pass-free version, with both DNL and 1P-DNL causing most models to collapse under a small number of flips.
Experiment
The researchers evaluate the effectiveness of DNL and 1P-DNL bit-flip attacks across diverse domains, including reasoning language models, text encoders, image classification, and object detection. The experiments demonstrate that targeted sign-bit flips can cause rapid model collapse, often reducing performance to near zero with only a few perturbations. These findings reveal a fundamental vulnerability in neural network representations that persists regardless of model scale or architecture, while also suggesting that selectively protecting high-impact parameters can serve as an effective defense.
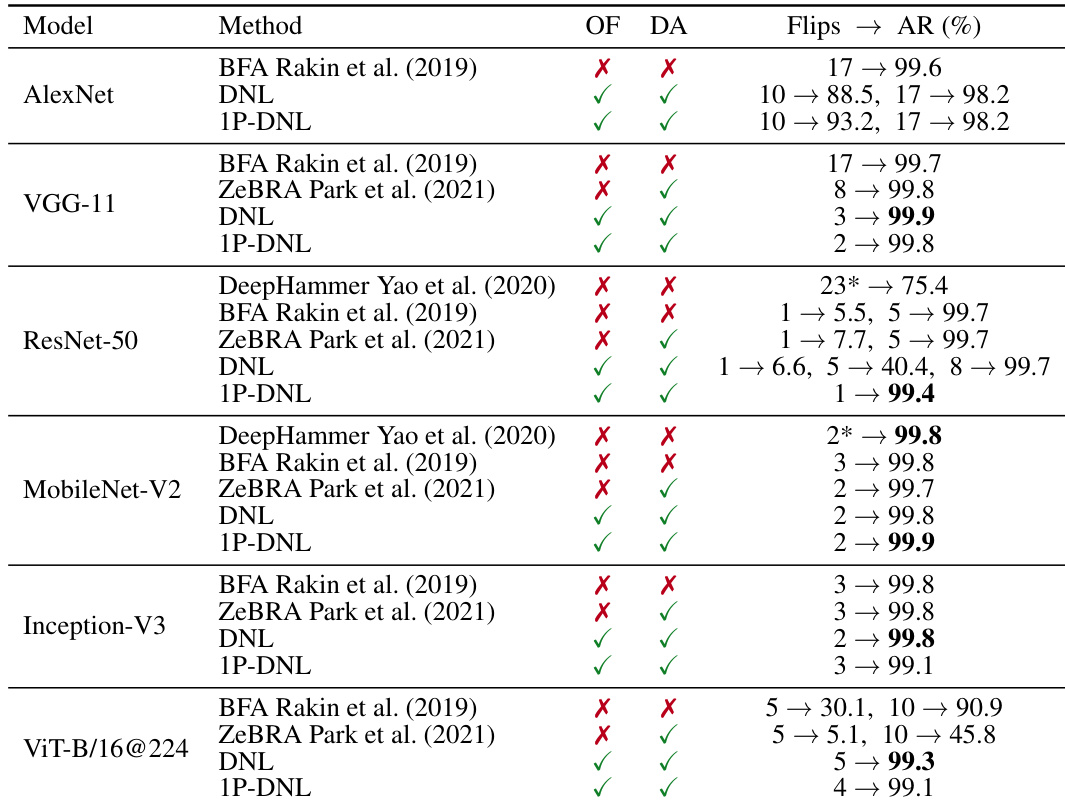
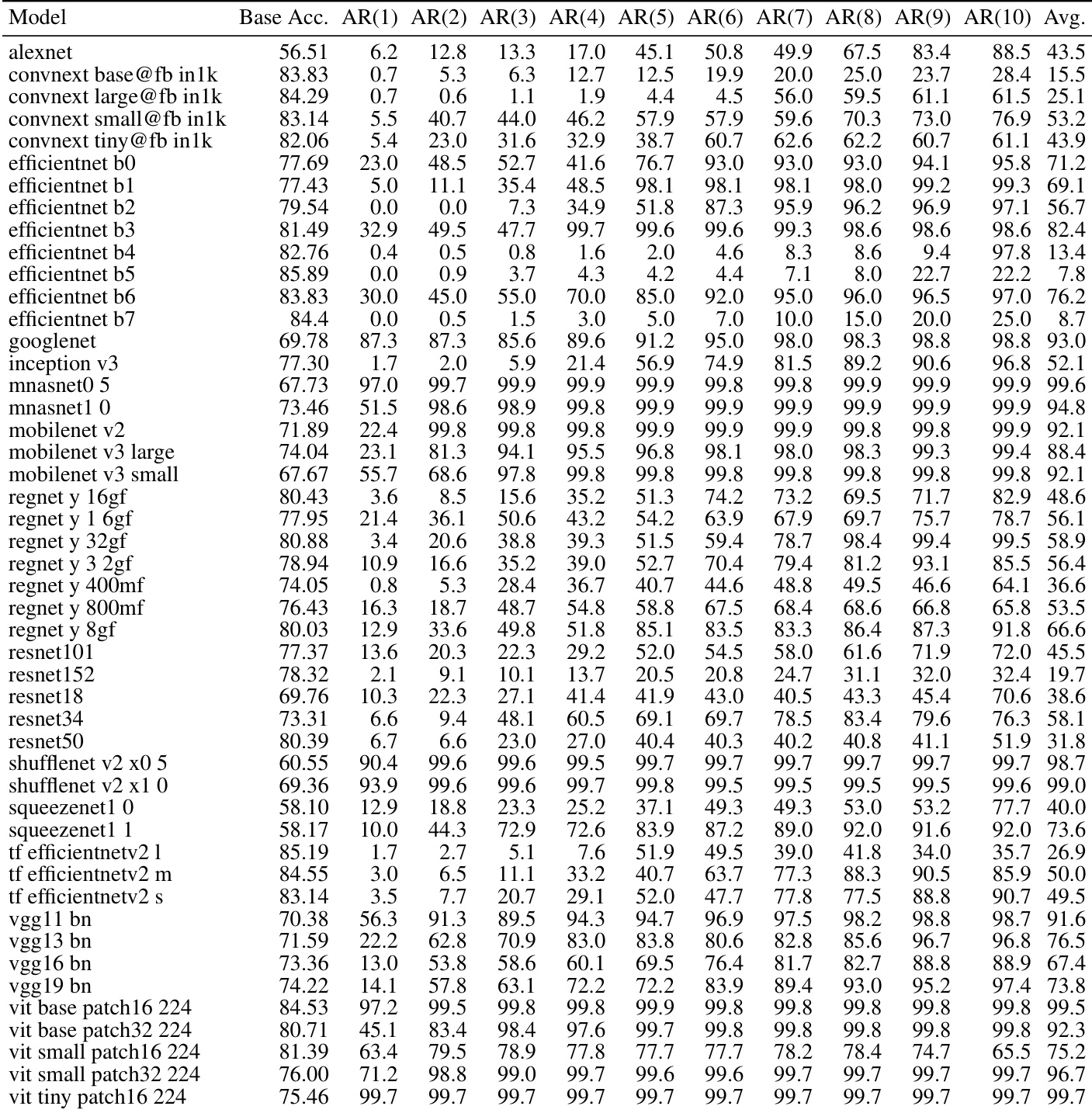
The the the table compares different bit-flip attack methods across multiple models, showing that DNL and 1P-DNL achieve high accuracy reduction with few flips. These methods are optimization-free and data-agnostic, outperforming others in effectiveness and efficiency. DNL and 1P-DNL achieve high accuracy reduction with minimal flips across various models. The attacks are optimization-free and data-agnostic, making them more efficient than other methods. 1P-DNL consistently outperforms DNL, achieving near-complete collapse with fewer flips.
The authors evaluate targeted sign-bit attacks on image classification models across multiple datasets and architectures. Results show that a small number of carefully selected bit flips lead to rapid and severe accuracy degradation, with most models collapsing to near-zero performance after a few flips. The attack is effective across different model types and datasets, indicating a fundamental vulnerability in deep neural network representations. A single targeted sign-bit flip causes significant accuracy reduction in image models. Most models collapse to near-zero accuracy after only a few sign-bit flips. The attack is effective across diverse architectures and datasets, indicating a general vulnerability.

The authors evaluate targeted sign-bit attacks on various image classification models, showing that a small number of carefully selected parameter flips lead to rapid accuracy collapse across multiple architectures. The results demonstrate consistent vulnerability regardless of model size or type, with most models experiencing severe degradation after just a few flips. A small number of targeted sign-bit flips cause rapid accuracy collapse across diverse image classification models Attack effectiveness is consistent across different model architectures and sizes Most models show severe degradation after only a few flips, indicating fundamental vulnerability
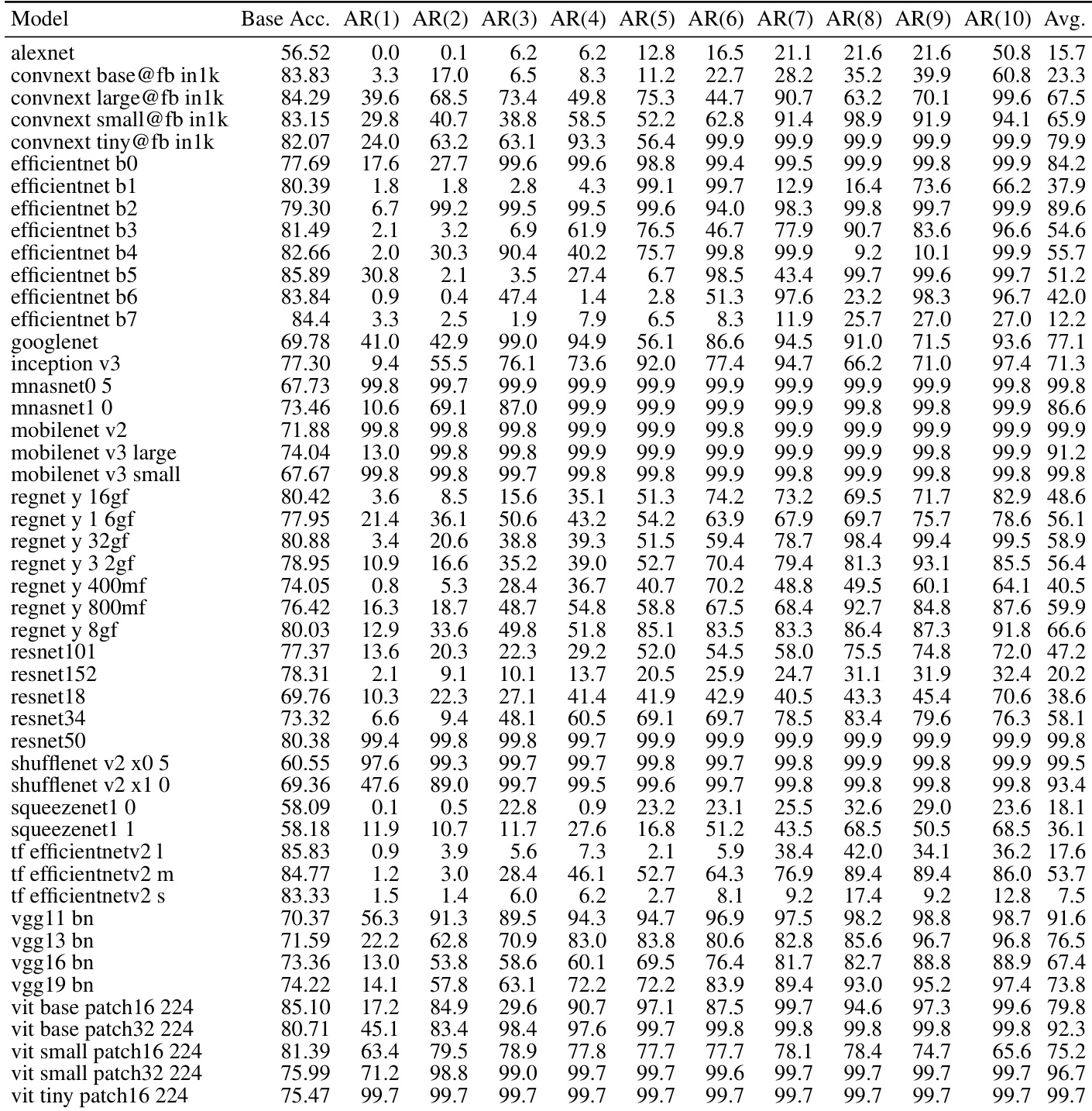
The authors evaluate targeted sign-bit attacks on a range of image classification models, showing that a small number of carefully selected parameter flips can cause severe accuracy degradation. The results demonstrate consistent vulnerability across diverse architectures, with most models collapsing to near-zero accuracy after only a few flips. Targeted sign-bit attacks cause rapid and severe accuracy reduction across diverse image models Most models exhibit near-complete collapse with fewer than 10 parameter flips The attack is effective regardless of model architecture, size, or design choices
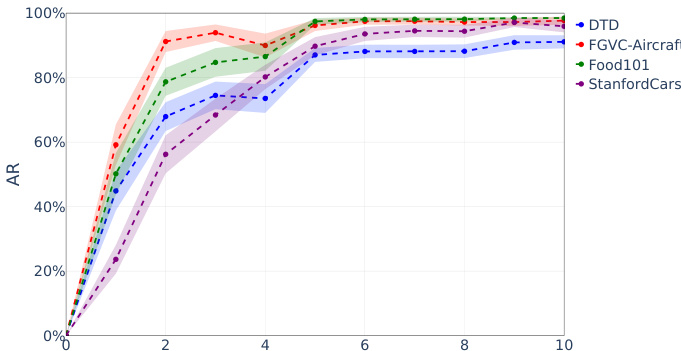
The authors evaluate targeted sign-bit attacks on image classification models across multiple datasets, showing that a small number of carefully selected bit flips cause rapid and severe accuracy reduction. The attack is effective across different models and datasets, with performance collapsing sharply after just a few flips. A few targeted sign-bit flips cause rapid collapse in image classification accuracy across multiple datasets. The attack is effective on various models, with performance dropping sharply after only a few flips. Different datasets show similar vulnerability patterns, indicating a general weakness in model representations.
The experiments evaluate various bit-flip attack methods, specifically focusing on targeted sign-bit attacks, across diverse image classification architectures and datasets. The results demonstrate that optimization-free and data-agnostic methods like 1P-DNL can cause rapid and severe accuracy collapse with only a minimal number of flips. This consistent vulnerability across different model sizes and designs indicates a fundamental weakness in deep neural network representations.