Command Palette
Search for a command to run...
OCRか、それともNotか?実世界の広範なデータセットを用いた、MLLMs時代におけるドキュメント情報抽出の再考
OCRか、それともNotか?実世界の広範なデータセットを用いた、MLLMs時代におけるドキュメント情報抽出の再考
Jiyuan Shen Peiyue Yuan Atin Ghosh Yifan Mai Daniel Dahlmeier
概要
マルチモーダル大規模言語モデル(MLLM)は、自然言語処理の可能性を大きく広げるものです。しかし、文書情報の抽出における実際のインパクトについては、いまだ不明な点が多く残されています。特に、よりシンプルな構成である「MLMのみのpipeline」が、従来の「OCR + MLLM」の構成と同等の性能を真に発揮できるのかという点は解明されていません。本論文では、ビジネス文書の情報抽出における様々な既存のMLMの性能を評価するため、大規模なbenchmarking調査を実施しました。また、失敗モード(failure modes)を検証・探究するために、LLMを活用してエラーパターンを体系的に診断する、自動化された階層的なエラー分析フレームワークを提案します。研究の結果、強力なMLMにおいては、画像のみの入力であってもOCRを併用した手法と同等の性能を達成できることから、OCRは必ずしも必要ではない可能性が示唆されました。さらに、慎重に設計されたschema、exemplars、およびinstructionsを用いることで、MLMの性能をさらに向上させられることも実証しました。本研究が、文書情報抽出の発展に向けた実践的な指針と貴重な知見を提供できることを期待しています。
One-sentence Summary
Through a large-scale benchmarking study and an automated hierarchical error analysis framework, this research evaluates various out-of-the-box Multimodal Large Language Models (MLLMs) on business-document information extraction, finding that image-only pipelines can achieve performance comparable to traditional OCR-enhanced setups when utilizing optimized schemas, exemplars, and instructions.
Key Contributions
- This work conducts a large-scale benchmarking study that evaluates various out-of-the-box Multimodal Large Language Models (MLLMs) on business-document information extraction to compare image-only pipelines against traditional OCR-enhanced setups.
- The paper introduces an automated hierarchical error analysis framework that leverages large language models to systematically diagnose and discover error patterns in document extraction tasks.
- The study demonstrates that image-only inputs can achieve comparable or even superior performance to OCR-enhanced approaches for powerful MLLMs, and shows that performance can be further improved through carefully designed schemas, exemplars, and instructions.
Introduction
Automating the extraction of structured information from business documents like invoices and financial statements is essential for streamlining enterprise workflows. Traditional industry pipelines typically rely on a complex two-stage framework that uses Optical Character Recognition (OCR) followed by a specialized extraction model, but this approach is prone to error propagation and lacks easy generalization across new domains. The authors conduct a large-scale benchmarking study to evaluate whether Multimodal Large Language Models (MLLMs) can replace these traditional setups. They propose an automated hierarchical error analysis framework to systematically diagnose failure modes and demonstrate that for powerful MLLMs, image-only inputs can match or even surpass the performance of OCR-enhanced pipelines.
Dataset
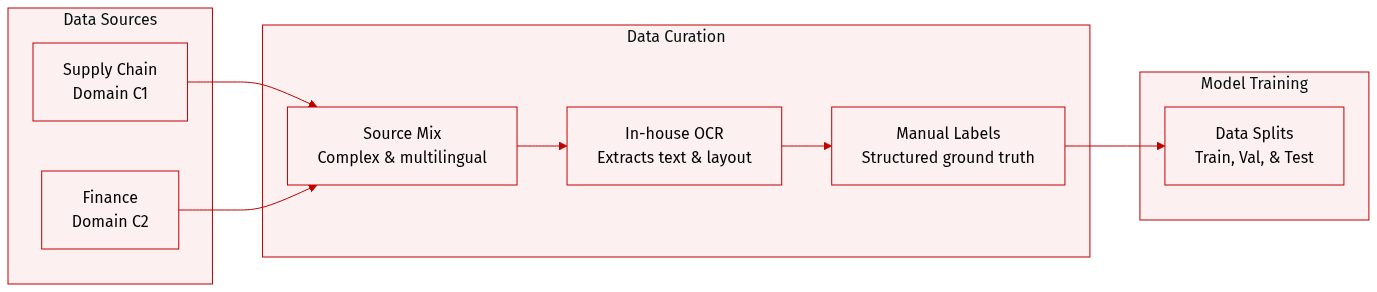
The authors utilize an internal industrial document dataset designed to address the complexities of real world business documents. The dataset composition and processing details are as follows:
- Dataset Composition and Sources: The dataset consists of two primary subsets: C1, which is sourced from the supply chain domain, and C2, which is sourced from the finance domain.
- Key Characteristics: Unlike standard open source datasets, this collection is characterized by high structural complexity and multilingual content. It includes documents with nested information, stacked cells within line items, and heterogeneous header structures.
- Data Processing and OCR: The authors employ a proprietary in house OCR engine specifically developed for business documents. This engine achieves over 90 percent average accuracy across multiple languages and outperforms major machine learning platform services.
- Metadata and Layout Preservation: To maintain structural integrity, the processing pipeline preserves layout information by retaining whitespace as a structural delimiter within the extracted text.
- Ground Truth Construction: Each document is accompanied by manually annotated, carefully curated structured ground truth labels alongside the OCR extracted text results.
Method
The authors propose a multi-stage evaluation pipeline and a hierarchical error analysis framework designed to systematically diagnose and categorize failures in document information extraction.
The evaluation pipeline begins with an OCR engine that extracts textual content from document images while preserving positional information. For experiments focusing solely on image inputs, this OCR step is bypassed. In the subsequent stage, the system performs structured information extraction. For Multimodal Large Language Model (MLLM) based approaches, the authors utilize a prompt template containing format instructions and a document schema to facilitate zero-shot extraction. The target schema is designed to capture both header fields and a list of line items, representing structured tabular data. The MLLM generates a JSON object where keys denote entity types and values contain the extracted content. Finally, performance is quantified using the standard F1 score, calculated by computing precision and recall over all extracted key-value pairs.
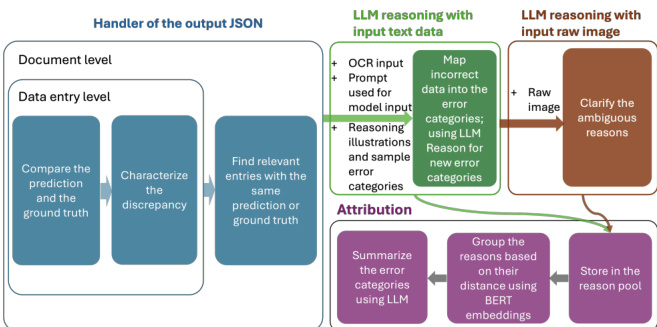
To address the complexities of extraction errors, the authors implement a hierarchical error analysis framework. As shown in the framework diagram, the process progresses from initial error detection to high-level attribution through three distinct modules: the Handler, LLM Reasoning, and Attribution.
The process is initiated by an automated error handler. This module compares predicted values against ground-truth values at both the character and semantic levels. The handler operates at both the field and document levels, performing three primary tasks: comparing predictions to ground truth, characterizing the nature of the discrepancies, and identifying relevant entries with similar predictions or ground-truth values for deeper investigation.
Following the handler, the LLM reasoning module refines error classification. This stage employs LLMs and MLLMs to generate structured diagnostic reports instead of relying on manual analysis. The reasoning process involves two steps. First, LLMs map incorrect predictions into predefined error categories using textual inputs such as OCR results, predicted values, and ground-truth labels. Second, to resolve ambiguities caused by layout complexities or visual nuances, the system incorporates raw document images as additional input to clarify the reasoning. This dual-modality approach allows the model to transition from textual reasoning to visual reasoning when necessary.
The final stage is the attribution module, which identifies the highest-level failure sources. The authors perform post-processing on the LLM-generated explanations by storing categorized reasons in a structured reason pool. To ensure coherent categorization, they apply BERT-based embedding clustering to group similar reasons based on cosine similarity. Representative keywords are then extracted for each cluster. This allows the framework to determine whether errors originate from specific root causes such as OCR misrecognition, layout misinterpretation, prompt misalignment, model capability limitations, or schema inconsistencies.
Experiment
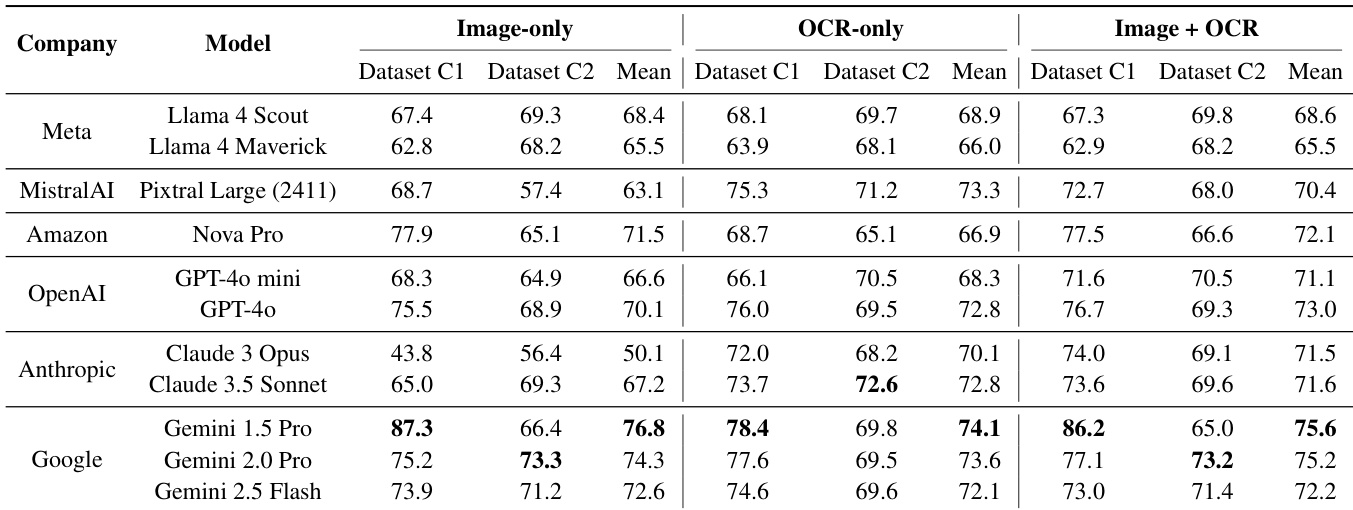
This study evaluates state-of-the-art multimodal large language models (MLLMs) on business document information extraction using three input modalities: image-only, OCR-only, and a combination of both. The experiments demonstrate that while combining modalities can stabilize performance, advanced models are increasingly capable of direct information extraction from images without relying on OCR. Furthermore, the findings suggest that optimized image-only approaches can outperform traditional methods by reducing schema ambiguity and leveraging the inherent layout comprehension of vision encoders.
The authors provide an estimation of the inference latency and cost per page for several closed-source multimodal large language models. The results indicate a variety of performance profiles regarding speed and expense across different model providers. Models such as Gemini 2.5 Flash demonstrate lower latency and lower costs compared to others in the benchmark. There is a notable trade-off between speed and expense, with some high-performance models requiring significantly higher costs per page. Latency varies widely among the evaluated models, ranging from very fast responses to several seconds per page.

The authors compare the performance of various multimodal large language models across three input modalities: image-only, OCR-only, and a combination of both. The results demonstrate that while OCR-only inputs provide relatively stable performance, combining image and OCR inputs can lead to more robust predictions for many flagship models. Flagship models from Google show high performance in the image-only setting, sometimes even performing better without explicit OCR text. Combining image and OCR inputs tends to reduce performance variance compared to using image-only inputs. Certain models exhibit performance decreases when transitioning from OCR-only to multimodal inputs, suggesting potential difficulties in integrating visual and textual information.
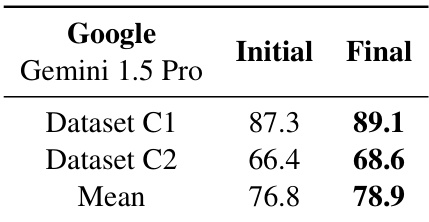
The authors evaluate the performance of Gemini 1.5 Pro using an optimized prompt template with image-only input. Results show that applying these refinements leads to performance gains across both tested business document datasets. The optimized prompt template improves performance for both Dataset C1 and Dataset C2. The mean performance increases following the application of the refined prompt strategy. The results demonstrate the effectiveness of the image-only approach when combined with enhanced instructions and schema adjustments.
The authors evaluate closed-source multimodal large language models by analyzing inference latency, cost efficiency, and performance across different input modalities. The experiments reveal a significant trade-off between speed and expense among providers and show that combining image and OCR inputs generally enhances prediction robustness, although some models struggle to integrate these modalities effectively. Furthermore, refining prompt templates for image-only inputs can successfully improve performance on business document datasets.