HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

SocialOmni: Omni Modelsにおける音響・視覚的ソーシャル・インタラクティビティのベンチマーキング

DeepSeek-V4:高効率なMillion-Tokenコンテキスト・インテリジェンスに向けて

























SocialOmni: Omni Modelsにおける音響・視覚的ソーシャル・インタラクティビティのベンチマーキング
DeepSeek-V4:高効率なMillion-Tokenコンテキスト・インテリジェンスに向けて
生成的な観点からの空間知能の探究
DeVI:合成ビデオ模倣による物理ベースの器用な人間と物体の相互作用
大規模モデル時代におけるReward Hacking:メカニズム、創発的ミスアライメント、および課題
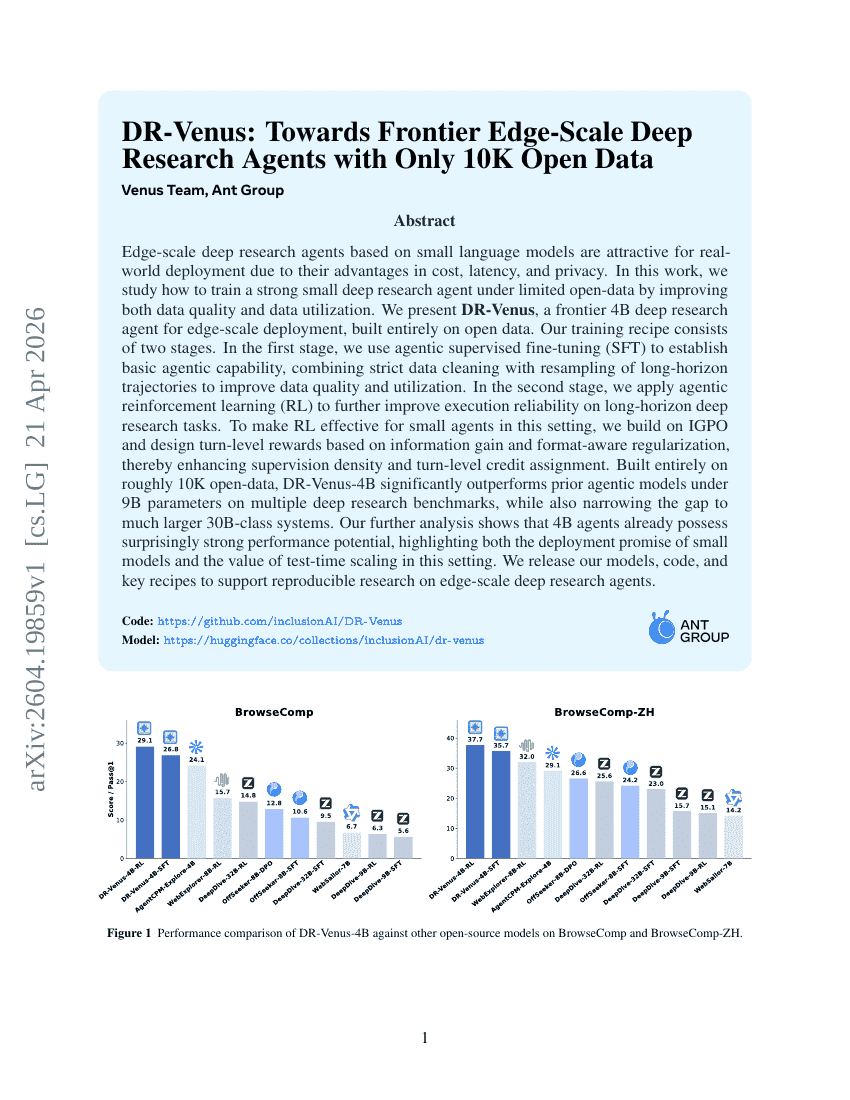
DR-Venus:わずか1万件のオープンデータによる、フロンティア級エッジスケールDeep Research agentsの実現に向けて
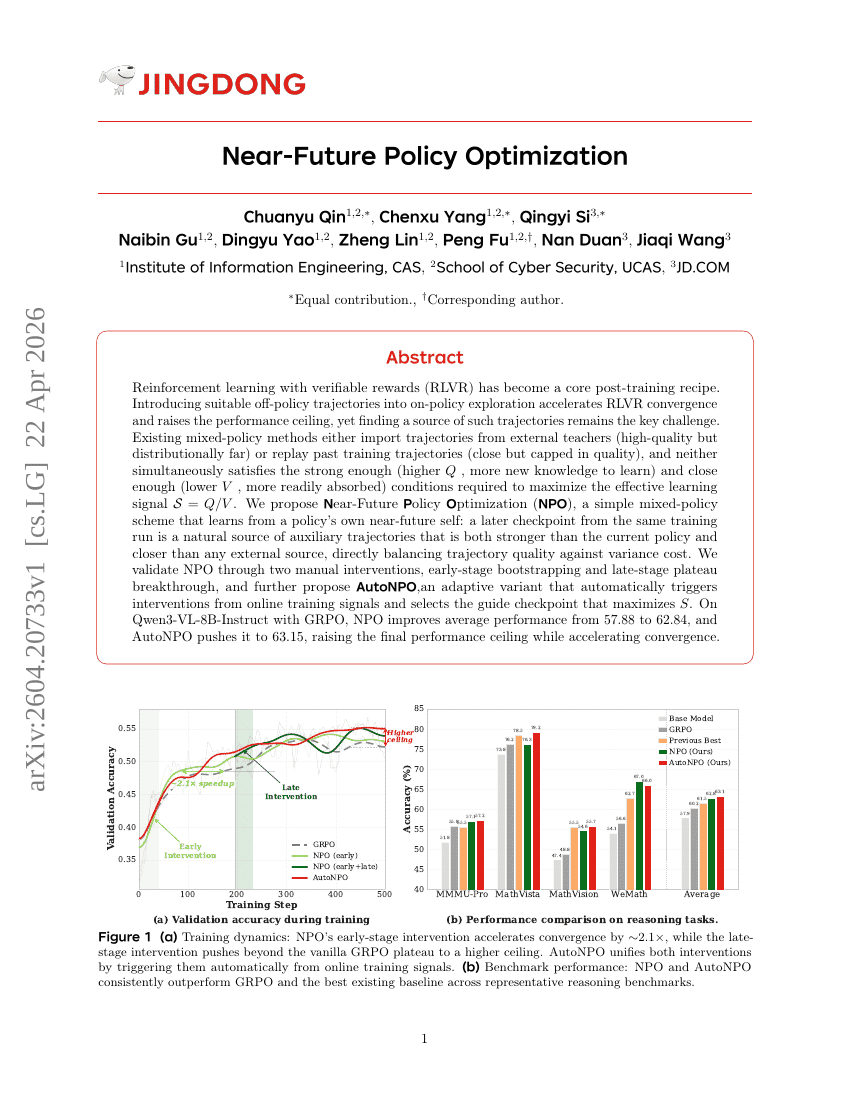
近未来の方策最適化
LLaDA2.0-Uni: Diffusion Large Language Modelによるマルチモーダル理解と生成の統合
BioInstruct: 生物医学自然言語処理に向けたLarge Language ModelsのInstruction Tuning
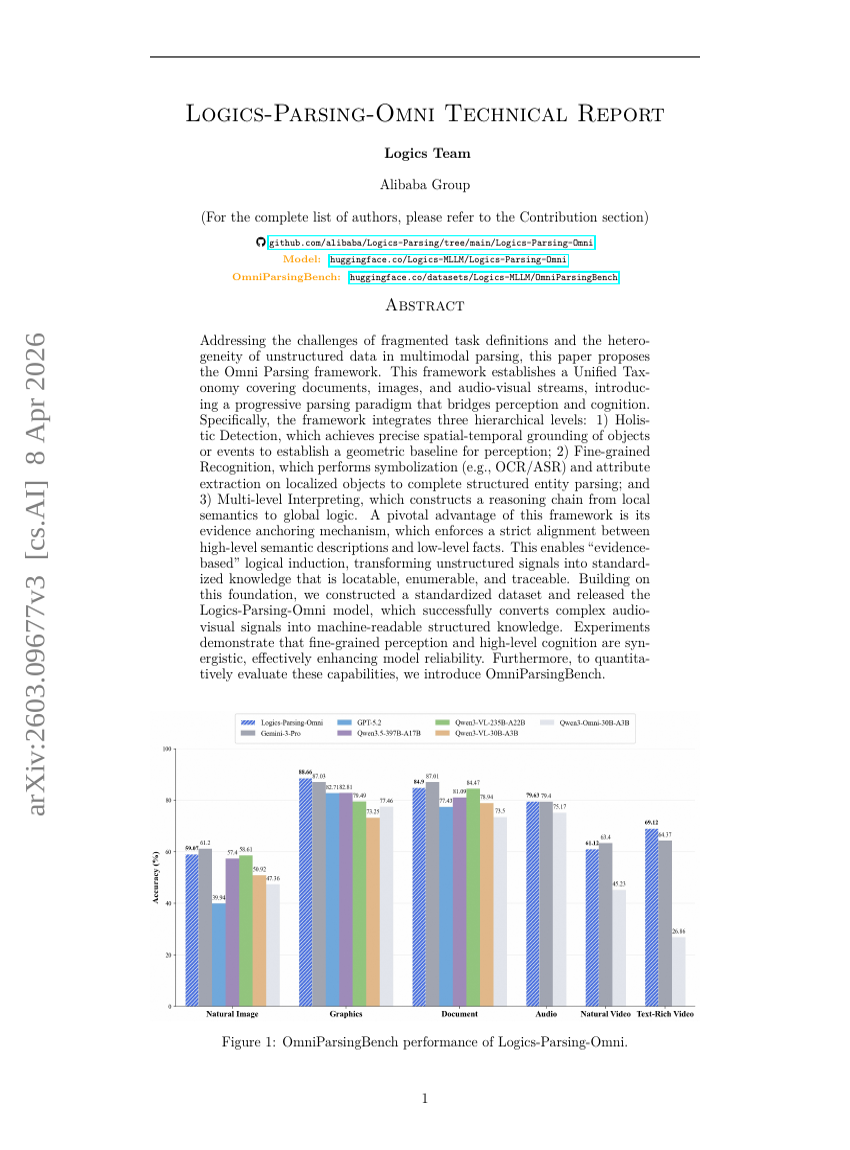
Logics-Parsing-Omni 技術報告書
Task Tokens: Behavior Foundation Modelを適応させるための柔軟なアプローチ
PlayCoder: LLMが生成したGUIコードの実行可能性を実現する
TEMPO: 大規模推論モデルにおけるTest-time Trainingのスケールアップ
AnyRecon: ビデオ拡散モデルを用いた任意の視点からの3D再構成
AgentSPEX: Agentの仕様および実行のための言語
CoInteract: 空間構造化共生成による物理的整合性を備えた人間と物体(Human-Object)の相互作用ビデオ合成
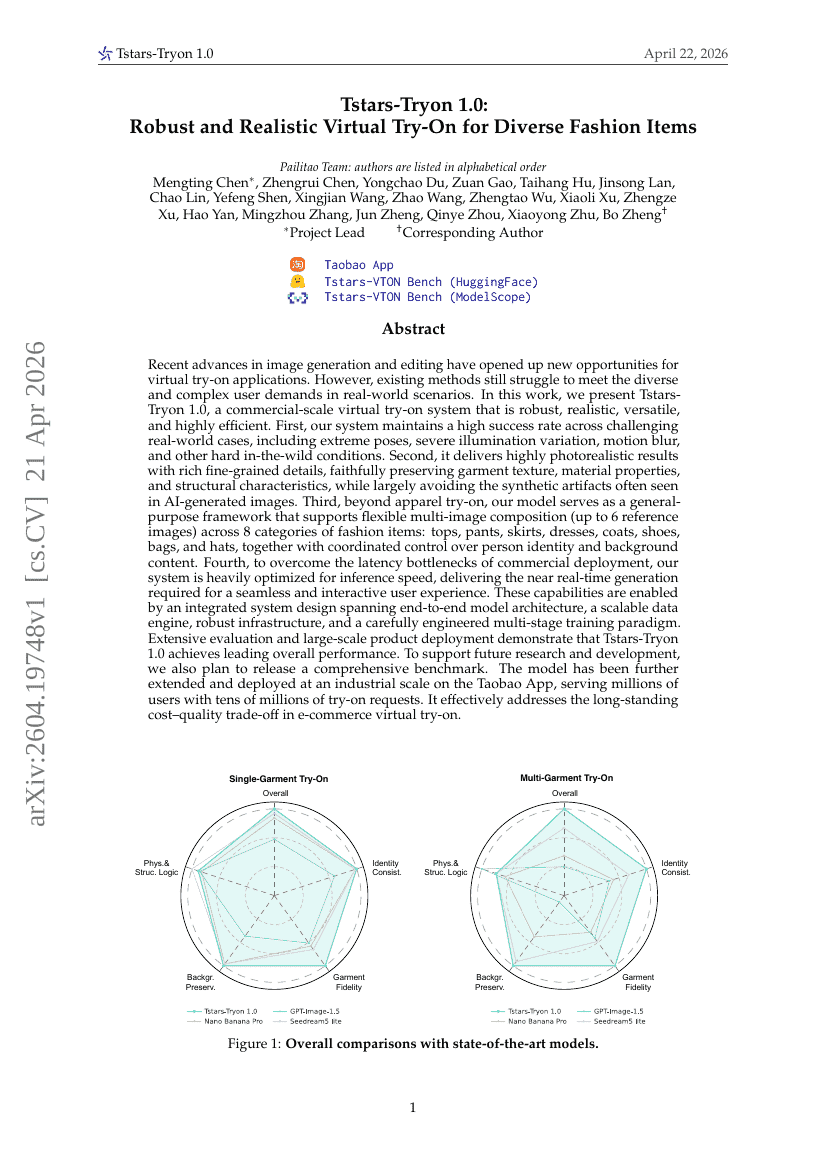
Tstars-Tryon 1.0:多様なファッションアイテムに対応した、堅牢かつリアルなバーチャルTry-On
Large Language Model 推論のための高速な NF4 量子化解除カーネル
EasyVideoR1:ビデオ理解のためのより容易なRL
MultiWorld: スケーラブルなMulti-Agent Multi-Viewビデオワールドモデル
OpenGame: ゲームのためのOpen Agentic Coding
Agent-World: 進化する汎用agent知能に向けた、実世界環境合成のスケーリング
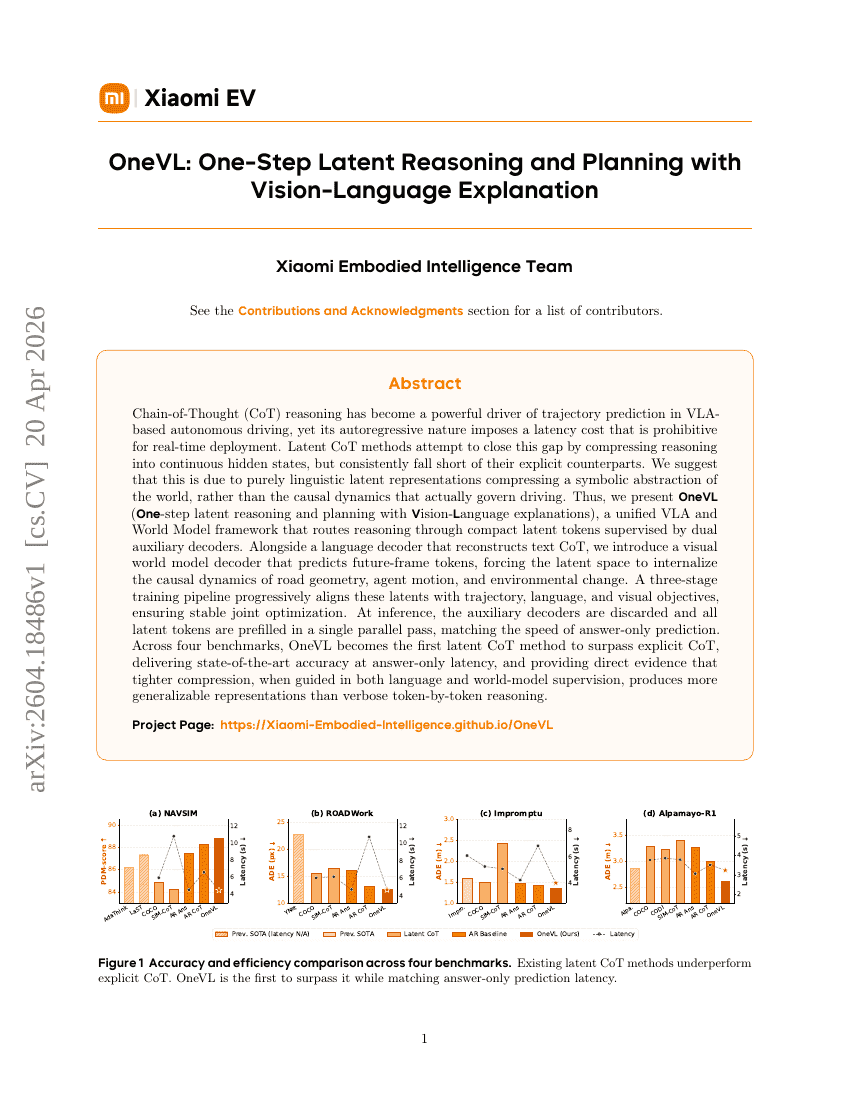
OneVL: Vision-Languageによる説明を伴うワンステップの潜在的推論およびプランニング
識別的なテキスト表現を用いた、クラスラベルからテキストへのワンステップ画像生成の拡張
ScribblePrompt: あらゆる生体医用画像に対する高速かつ柔軟なインタラクティブ・セグメンテーション
Long-VITA: 短いコンテキストにおける卓越した精度を維持しつつ、Large Multi-modal Modelsを1 million tokensまでスケーリングする
UI-TARS:Native AgentによるGUI自動インタラクションの先駆的研究
HunyuanVideo:大規模ビデオ生成モデルのための体系的なフレームワーク
MathNet:数学的推論および検索のためのグローバルなマルチモーダル・ベンチマーク
LLM AgentにおけるExternalization:Memory、Skills、ProtocolsおよびHarness Engineeringに関する統一的レビュー
Active Context Compression: LLM Agentにおける自律的メモリ管理
生成的な観点からの空間知能の探究
DeVI:合成ビデオ模倣による物理ベースの器用な人間と物体の相互作用
大規模モデル時代におけるReward Hacking:メカニズム、創発的ミスアライメント、および課題
DR-Venus:わずか1万件のオープンデータによる、フロンティア級エッジスケールDeep Research agentsの実現に向けて
近未来の方策最適化
LLaDA2.0-Uni: Diffusion Large Language Modelによるマルチモーダル理解と生成の統合
BioInstruct: 生物医学自然言語処理に向けたLarge Language ModelsのInstruction Tuning
Logics-Parsing-Omni 技術報告書
Task Tokens: Behavior Foundation Modelを適応させるための柔軟なアプローチ
PlayCoder: LLMが生成したGUIコードの実行可能性を実現する
TEMPO: 大規模推論モデルにおけるTest-time Trainingのスケールアップ
AnyRecon: ビデオ拡散モデルを用いた任意の視点からの3D再構成
AgentSPEX: Agentの仕様および実行のための言語
CoInteract: 空間構造化共生成による物理的整合性を備えた人間と物体(Human-Object)の相互作用ビデオ合成
Tstars-Tryon 1.0:多様なファッションアイテムに対応した、堅牢かつリアルなバーチャルTry-On
Large Language Model 推論のための高速な NF4 量子化解除カーネル
EasyVideoR1:ビデオ理解のためのより容易なRL
MultiWorld: スケーラブルなMulti-Agent Multi-Viewビデオワールドモデル
OpenGame: ゲームのためのOpen Agentic Coding
Agent-World: 進化する汎用agent知能に向けた、実世界環境合成のスケーリング
OneVL: Vision-Languageによる説明を伴うワンステップの潜在的推論およびプランニング
識別的なテキスト表現を用いた、クラスラベルからテキストへのワンステップ画像生成の拡張
ScribblePrompt: あらゆる生体医用画像に対する高速かつ柔軟なインタラクティブ・セグメンテーション
Long-VITA: 短いコンテキストにおける卓越した精度を維持しつつ、Large Multi-modal Modelsを1 million tokensまでスケーリングする
UI-TARS:Native AgentによるGUI自動インタラクションの先駆的研究
HunyuanVideo:大規模ビデオ生成モデルのための体系的なフレームワーク
MathNet:数学的推論および検索のためのグローバルなマルチモーダル・ベンチマーク
LLM AgentにおけるExternalization:Memory、Skills、ProtocolsおよびHarness Engineeringに関する統一的レビュー
Active Context Compression: LLM Agentにおける自律的メモリ管理