Command Palette
Search for a command to run...
DR3-Eval:面向真实且可复现的深度研究评估 (Deep Research Evaluation)
DR3-Eval:面向真实且可复现的深度研究评估 (Deep Research Evaluation)
概要
ご依頼ありがとうございます。ご提示いただいた英文は、Deep Research Agentsに関する新しい評価ベンチマークに関する学術的な要旨(Abstract)です。ご指定の通り、専門用語(LLM/Agent等)は英語のまま保持し、科技・学術的なスタイルを用いて、正確かつ流暢な日本語に翻訳いたしました。翻訳文(日本語)Deep Research Agents (DRAs) は、計画、検索、マルチモーダル理解、およびレポート生成を伴う、複雑で長期的な(long-horizon)研究タスクの解決を目指している。しかし、動的なウェブ環境や曖昧なタスク定義が原因で、その評価は依然として困難な課題となっている。本論文では、マルチモーダルかつ複数ファイルにわたるレポート生成において、Deep Research Agentsを評価するための、現実的かつ再現可能なベンチマークである「DR3-Eval」を提案する。DR3-Evalは、ユーザーから提供された真正な資料に基づき構築されており、各タスクに対して静的なリサーチ・サンドボックス・コーパス(research sandbox corpus)が組み合わされている。このコーパスは、オープンウェブの複雑さをシミュレートしつつ、完全な検証可能性を維持しており、支援文書、ディストラクター(distractors)、およびノイズを含んでいる。さらに、我々は、Information Recall(情報の想起)、Factual Accuracy(事実の正確性)、Citation Coverage(引用の網羅性)、Instruction Following(指示への追従性)、およびDepth Quality(内容の深さ)を測定する多角的な評価フレームワークを導入し、それが人間の判断と一致することを検証した。複数の最先端言語モデル(state-of-the-art language models)に基づき開発されたマルチAgentシステム「DR3-Agent」を用いた実験により、DR3-Evalが非常に高い難易度を持つこと、および、検索の堅牢性(retrieval robustness)とhallucination(ハルシネーション)制御における決定的な失敗モードを明らかにできることを示した。なお、我々のコードとデータは公開されている。
One-sentence Summary
The authors propose DR3-Eval, a realistic and reproducible benchmark for evaluating deep research agents on multimodal, multi-file report generation that utilizes a static research sandbox corpus to simulate open-web complexity and employs a multi-dimensional evaluation framework to assess information recall, factual accuracy, citation coverage, instruction following, and depth quality.
Key Contributions
- The paper introduces DR3-Eval, a realistic and reproducible benchmark designed to evaluate deep research agents on the task of multimodal, multi-file report generation.
- This work presents a research sandbox corpus constructed from authentic user materials that simulates the complexity of the open web through the use of supportive documents, distractors, and noise.
- The authors develop a multi-dimensional evaluation framework that measures Information Recall, Factual Accuracy, Citation Coverage, Instruction Following, and Depth Quality, which is validated to align with human judgments.
Introduction
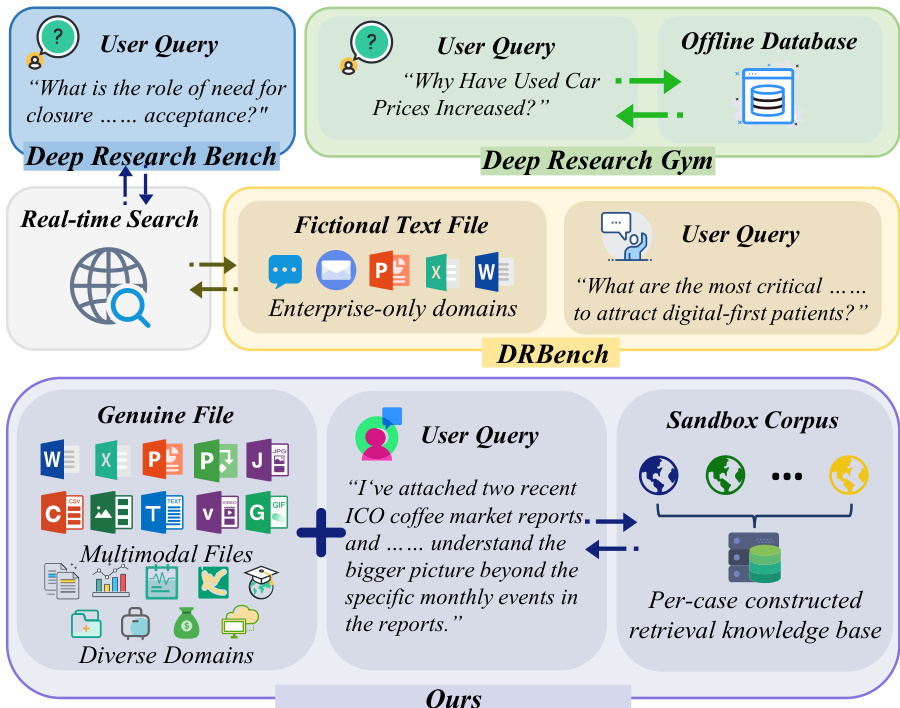
Deep Research Agents (DRAs) are designed to automate complex, long-horizon tasks such as planning, multimodal information retrieval, and the synthesis of structured reports. While these agents are increasingly capable, evaluating them is difficult because live web environments are temporally volatile and hard to reproduce. Existing benchmarks often struggle with this tension, either relying on unpredictable real-time web access or using simplified, text-only sandboxes that lack the multimodal complexity and noisy, misleading information found in real-world research.
The authors leverage a new benchmark called DR3-Eval to bridge this gap. They introduce a controlled, static research sandbox that simulates the complexity of the open web using curated documents, distractors, and noise to ensure results are both realistic and fully verifiable. To provide a rigorous assessment, the authors implement a multi-dimensional evaluation framework that measures metrics such as Information Recall, Factual Accuracy, and Citation Coverage, ensuring that agent performance is judged on both evidence acquisition and analytical depth.
Dataset

The authors developed DR3-Eval, a high-purity benchmark designed to evaluate deep research capabilities through a five-stage construction process.
-
Dataset Composition and Sources
- The dataset consists of 100 independent tasks, split evenly between English and Chinese samples.
- Content is grounded in real-world needs using multimodal material sets (text, structured data, static visuals, and dynamic media) provided by academic volunteers.
- Topics span three major domains: Technology, Economy, and Humanities, covering 13 specific sub-fields such as Computer Science, Healthcare, and Finance.
- Input modalities include documents (45.98%), images (27.68%), and videos (13.84%), with 68% of tasks being multimodal.
-
Sandbox Corpus and Web Page Subsets To simulate real-world research environments, the authors constructed a static sandbox corpus for each task using a divergent-convergent keyword generation strategy. Web pages are categorized into three distinct types:
- Supportive Web Pages: High-relevance results from signal keywords that provide necessary and sufficient evidence.
- Distractor Web Pages: Results from signal keywords that are outdated, one-sided, or inaccurate to test the ability to distinguish useful evidence from misleading information.
- Noise Web Pages: Results from noise keywords used to adjust signal-to-noise ratios.
-
Processing and Difficulty Scaling
- Sanitization: All materials undergo an automated PII redaction script followed by manual cross-validation to ensure complete anonymization.
- Cleaning: A unified pipeline crawls web results, removes failed pages, and strips template elements like ads and navigation bars.
- Context Scaling: To simulate the long-tail effect of information quality, the authors implement a fine-grained difficulty scaling strategy with five context lengths: 32k, 64k, 128k, 256k, and 512k tokens.
- Mixing Strategy: All settings include the full set of supportive web pages. As the target context length increases, the number of distractor pages grows proportionally, with the remaining quota filled by noise web pages.
-
Quality Control and Query Construction
- The authors use an evidence-based, reverse construction method where queries are synthesized based on pre-determined documents to ensure answers are verifiable and require joint reasoning.
- A "QC funnel" was applied to filter 280 initial candidate tasks down to the final 100. Tasks were discarded if they lacked synthesis necessity, provided easy shortcuts via public search, or contained ambiguous interpretations.
Method
The authors leverage the MiroFlow framework to construct DR³-Agent, a large language model (LLM)-driven system designed to address the deep research challenges posed by DR³-Eval, particularly those involving user-provided files and an offline sandbox corpus. The system's architecture is structured around a central reasoning hub, the main agent, which orchestrates information acquisition and report generation through a dynamic "Plan-Act-Observe" loop. This main agent maintains a global task context and coordinates specialized sub-agents to handle specific information acquisition tasks, thereby mitigating the burden on the primary reasoning component. As shown in the figure below, the system processes both user-provided files and a sandbox corpus, which is a per-case constructed retrieval knowledge base. The main agent is augmented with perception tools, enabling it to directly handle multimodal user files such as audio and video, allowing it to synthesize content within the global context rather than treating it as isolated extraction tasks. This design is essential for the system's ability to synthesize information from diverse sources.
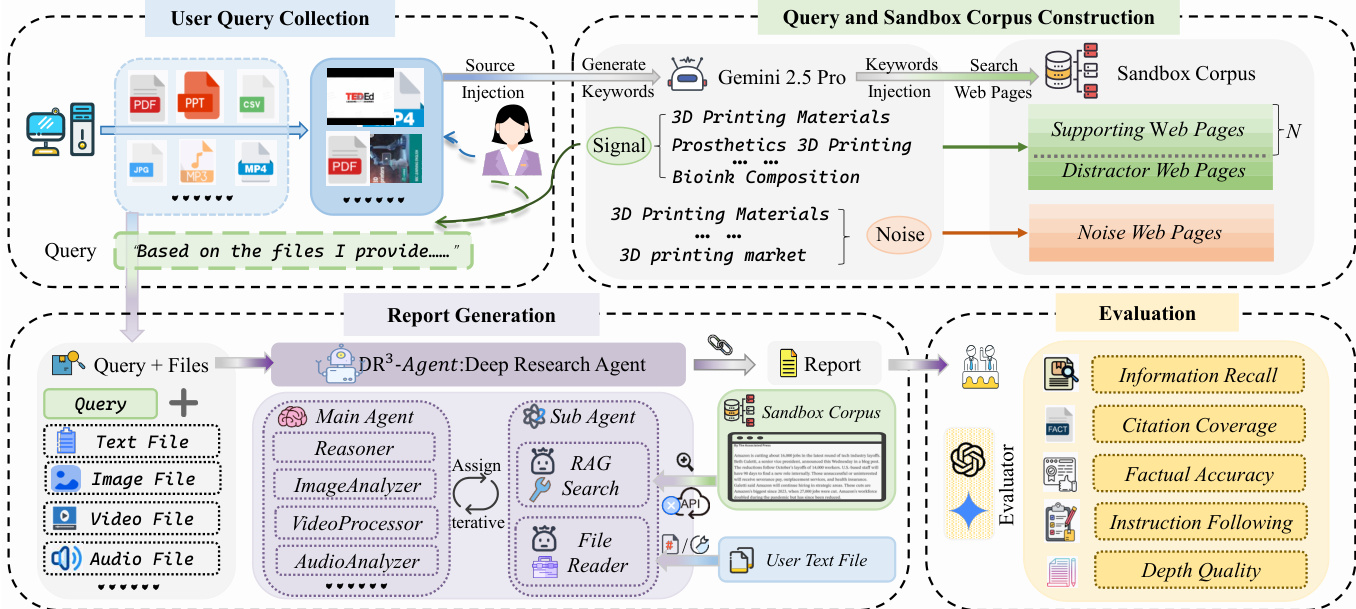
At the information acquisition level, the system employs two dedicated sub-agents, both powered by the same underlying LLM, to perform specific tasks. The RAG search sub-agent is responsible for interacting with the static sandbox corpus. It replaces traditional open web search with an iterative dense retrieval mechanism based on the text-embedding-3-small model, operating within a controlled environment. This agent uses the ReAct paradigm to perform autonomous, multi-step retrieval with iterative query refinement. This process allows the agent to evaluate incomplete or conflicting evidence and revise its search direction across iterations, making the search functionally analogous to heuristic exploration over hyperlink graphs. The file reader sub-agent specializes in parsing long-text user files, utilizing tools to execute fine-grained keyword queries and retrieve content by page numbers. Both sub-agents operate independently, do not share the global state, and return only highly condensed summaries to the main agent.
The report generation process begins with the main agent, which, based on the query and files, generates a comprehensive report. This report is then evaluated by a suite of metrics to assess its quality. The evaluation framework includes Information Recall (IR), which measures the coverage of specific insights extracted from user files and the sandbox corpus. Citation Coverage (CC) evaluates the model's ability to retrieve and cite documents necessary for the query. Factual Accuracy (FA) assesses the veracity of claims within the report against their source, using a model to verify textual claims and Gemini-2.5-Pro to verify claims grounded in video or audio content. Instruction Following (IF) ensures the report satisfies all requirements derived from the task query, and Depth Quality (DQ) evaluates the analytical substance and logical rigor of the report using a model as an expert judge. This comprehensive evaluation framework ensures that the generated report meets high standards of accuracy, completeness, and analytical depth.
Experiment
The DR3-Eval framework assesses long-horizon research tasks by evaluating both information-seeking quality and report generation through a combination of automated metrics and LLM-based judges. Experiments demonstrate that while model performance scales with size, increasing context length introduces noise that degrades evidence retrieval, and high instruction-following capabilities do not inherently guarantee factual accuracy. Ultimately, the results suggest that the primary bottleneck for current models is maintaining grounding in external evidence during report generation rather than simple information acquisition.
The the the table compares LLM-generated and human-evaluated scores across multiple metrics for five cases. Results show consistent performance between LLM and human judges across most dimensions, with slight variations in scores for individual metrics. LLM and human judges show strong agreement in scoring across all cases. Information recall and citation coverage metrics exhibit the most consistent alignment between LLM and human evaluations. Some metrics like factual accuracy and instruction following show minor discrepancies between LLM and human scoring.
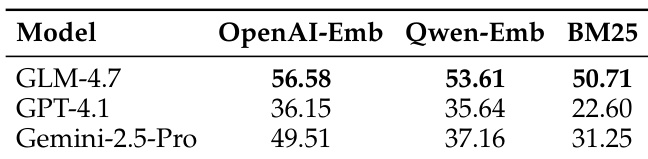
The the the table compares the performance of different retrieval methods across three models, showing that OpenAI-Emb achieves the highest scores, followed by Qwen-Emb, while BM25 performs the lowest. The results indicate that the choice of embedding method significantly impacts retrieval effectiveness. OpenAI-Emb outperforms Qwen-Emb and BM25 across all models. BM25 shows the lowest performance among the three retrieval methods. The embedding-based methods significantly outperform the traditional lexical-based approach.
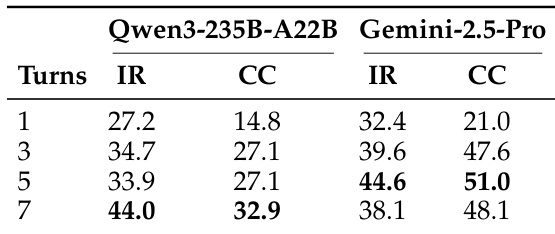
The the the table shows the impact of varying the number of RAG iteration turns on model performance, with metrics for information recall (IR) and citation coverage (CC). Performance generally improves as iteration turns increase, but some models show a decline after reaching a peak, indicating diminishing returns. Increasing RAG iteration turns generally improves performance up to a point Performance peaks and then declines for some models with higher iteration counts Citation coverage shows a more pronounced improvement with increased turns compared to information recall
{"caption": "Model performance across domains", "summary": "The authors evaluate multiple language models across various domains, showing significant variation in performance. Results indicate that model rankings differ by domain, with some models excelling in specific areas while others perform consistently well across most domains.", "highlights": ["Performance varies significantly across different domains, with top models showing strong domain-specific strengths.", "Models exhibit consistent rankings across most domains, suggesting stable relative performance.", "The evaluation reveals that no single model dominates all domains, highlighting the importance of domain-specific adaptation."]
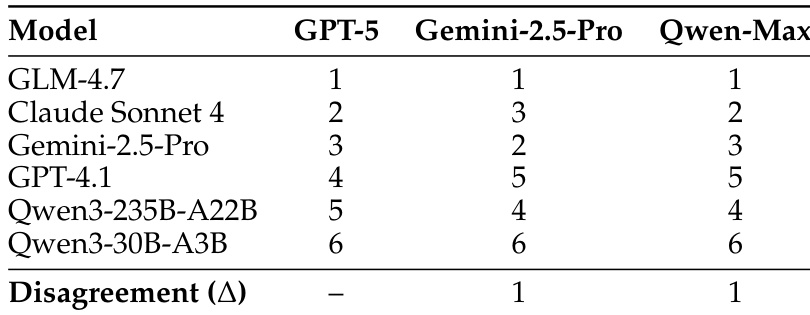
The the the table shows rankings of different models by three judge models, with high consistency in rankings across judges. There is minimal disagreement in the ordering of top models, indicating robust and stable evaluation results. Rankings are highly consistent across different judge models with minimal disagreement. Claude Sonnet 4 achieves the top rank across all three judge models. GPT-5, Gemini-2.5-Pro, and Qwen-Max produce nearly identical model rankings.
These experiments evaluate the reliability of LLM-based scoring, the effectiveness of various retrieval methods, and the impact of RAG iteration turns on model performance across different domains. The results demonstrate that LLM judges align closely with human evaluations and maintain consistent rankings across different judge models. Furthermore, embedding-based retrieval methods significantly outperform lexical approaches, and while increasing RAG iterations generally improves performance, models eventually encounter diminishing returns.