Command Palette
Search for a command to run...
GTR: Guided Thought Reinforcement Prevents Thought Collapse in RL-based VLM Agent Training
GTR: Guided Thought Reinforcement Prevents Thought Collapse in RL-based VLM Agent Training
Tong Wei Yijun Yang Junliang Xing Yuanchun Shi Zongqing Lu Deheng Ye
概要
検証可能な結果報酬を用いた強化学習(RLVR: Reinforcement Learning with Verifiable Outcome Rewards)は、大規模言語モデル(LLM)におけるChain-of-Thought(CoT)推論のスケーリングを効果的に進めてきました。しかし、視覚環境における目標指向型の行動推論を行うVision-Language Model(VLM)エージェントの学習において、その有効性は十分に確立されていません。本研究では、「24ゲーム」のような複雑なカードゲームや、ALFWorldにおけるエンボディード・タスク(Embodied tasks)を用いた広範な実験を通じて、この課題を調査しました。その結果、報酬が行動の結果のみに基づいている場合、RLはVLMにおけるCoT推論を促進するどころか、「thought collapse(思考崩壊)」と呼ばれる現象を引き起こすことが判明しました。この現象は、エージェントの思考における多様性の急速な喪失、状態(state)とは無関係かつ不完全な推論、そしてそれに続く無効な行動によって、負の報酬を招くという特徴を持ちます。このthought collapseに対処するため、本研究ではプロセス・ガイダンス(process guidance)の必要性を強調し、各RLステップにおいてエージェントの推論を評価・改善する自動コレクター(automated corrector)を提案します。このシンプルかつスケーラブルな「GTR(Guided Thought Reinforcement)」フレームワークは、ステップごとの密な人間によるラベル付けを必要とせず、推論と行動を同時に学習させることが可能です。実験の結果、GTRはLLaVA-7Bモデルの様々な視覚環境における性能と汎用性を大幅に向上させ、既存のSoTAモデルと比較して、著しく小さなモデルサイズでありながら、タスク成功率を3〜5倍向上させることに成功しました。
One-sentence Summary
To counteract thought collapse in vision-language model agents caused by outcome-only rewards, the authors propose GTR, a Guided Thought Reinforcement framework that employs an automated corrector to evaluate and refine reasoning at each step without dense, per-step human labeling, enabling the LLaVA-7B model to achieve task success rates three to five times higher than SoTA models across various visual environments.
Key Contributions
- The paper empirically identifies a phenomenon termed thought collapse where vision-language models lose reasoning diversity during reinforcement learning due to outcome-only rewards. This finding highlights that standard training fails to incentivize chain-of-thought reasoning in complex visual environments.
- The work introduces the Guided Thought Reinforcement framework, which employs an automated corrector to evaluate and refine reasoning at each reinforcement learning step. This method allows for simultaneous training of reasoning and action without the need for dense per-step human labeling.
- Experimental results demonstrate that the framework significantly enhances the performance and generalization of the LLaVA-7B model across various visual environments. The approach achieves task success rates that are three to five times higher than state-of-the-art models while utilizing a notably smaller model size.
Introduction
While reinforcement learning with verifiable outcome rewards has successfully scaled chain-of-thought reasoning in large language models, it remains less effective for training vision-language model agents in dynamic visual environments. Existing methods relying solely on final action rewards often cause thought collapse, where the agent’s reasoning diversity rapidly degrades into state-irrelevant patterns that lead to invalid actions. The authors propose Guided Thought Reinforcement to counteract this issue by employing an automated corrector that evaluates and refines reasoning at each reinforcement learning step. This framework delivers essential process guidance without requiring dense human annotations, enabling the model to achieve significantly higher task success rates in complex scenarios like card games and embodied tasks.
Dataset
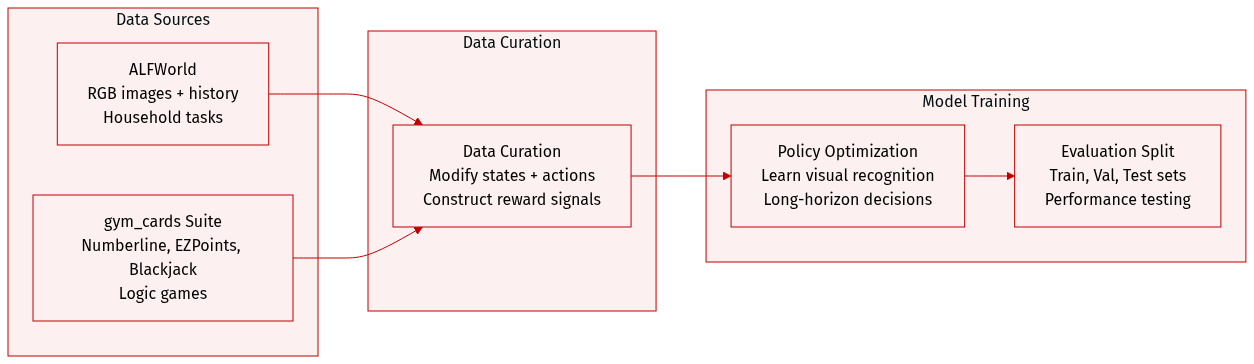
-
Dataset Composition and Sources
- The authors utilize two simulation environments for data generation: ALFWorld for embodied household tasks and the gym_cards suite for simpler logic games.
- These environments provide state-action sequences that serve as the basis for training and evaluation.
-
Key Details for Each Subset
- ALFWorld: States include RGB observation images and a history of past actions. The action space covers interactions such as go to, take, put, open, close, toggle, clean, heat, and cool.
- Numberline: Agents adjust a current integer to match a target value between 0 and 5 using addition or subtraction within five steps.
- EZPoints: This simplified Points24 variant requires solving for a target of 12 with two cards in exactly four steps.
- Blackjack: Agents play against a dealer with partial card visibility and choose between hit or stand actions to win the game.
-
Data Usage and Processing
- State Modification: The authors removed textual scene descriptions from ALFWorld to force reliance on visual observations and increase task difficulty.
- Metadata Construction: Action sequences are appended to the state history to better simulate real-world scenarios and test long-horizon decision-making.
- Reward Signals: The reward function grants points for achieving goals or sub-goals and applies penalties for illegal actions to guide policy optimization.
Method
The authors propose a framework termed GTR (Guided Thought Reinforcement) to enhance the reasoning capabilities of Vision-Language Models (VLMs) in sequential decision-making tasks. This approach integrates supervised fine-tuning (SFT) with Proximal Policy Optimization (PPO) to simultaneously optimize both the agent's reasoning thoughts and its actions.
Refer to the framework diagram for an overview of the system architecture. The process involves three main components: the VLM Agent, the VLM Corrector, and the RL Finetuning loop. The VLM Agent interacts with the environment, generating text outputs that contain both Chain-of-Thought (CoT) reasoning and specific actions. To ensure the agent learns from high-quality reasoning, an external VLM acts as a corrector model. This corrector evaluates the agent's generated thoughts for visual recognition accuracy and logical consistency. If inconsistencies or errors are detected, the corrector model refines the original thought. The framework then aligns the agent's reasoning with these corrected trajectories by applying an SFT loss on the thought tokens, while the PPO loss optimizes the action tokens based on environmental rewards.
The core reinforcement learning algorithm follows the standard PPO framework for finetuning VLMs. The post-processing function extracts the keyword "action : a" from the VLM's text output to determine the executed action. If the output lacks this keyword, the agent defaults to random exploration by selecting an action from the set of legal actions A. Formally, given the VLM's output vout and the set of legal actions A, the post-processing function f is defined as:
f(vout)={a,Unif(A),if "action: a"∈ voutotherwiseThe action probability required for the policy gradient is calculated from the generation probabilities of each token in the output text. A scaling factor λ is employed to balance the longer length of CoT outputs compared to action outputs. If πθ denotes the policy, ot and at represent the observation and action, and vtth and vtact represent CoT reasoning tokens and action tokens respectively, the calculation is shown as:
logπθ(at∣ot,vtin)=λlogπθ(vtth∣ot,vtin)+logπθ(vtact∣ot,vtin,vttht)=λ∑logp(ot,vtin,v[:i−1]tht)p(ot,vtin,v[:i]tht)+∑logp(ot,vtin,vttht,v[:i−1]act)p(ot,vtin,vttht,v[:i]act)The objective of GTR combines the PPO loss for actions and the SFT loss for thoughts. If the paper denote the agent's thought output as th and action as a, given agent model πθ and corrector model πcorr, the objective is represented as:
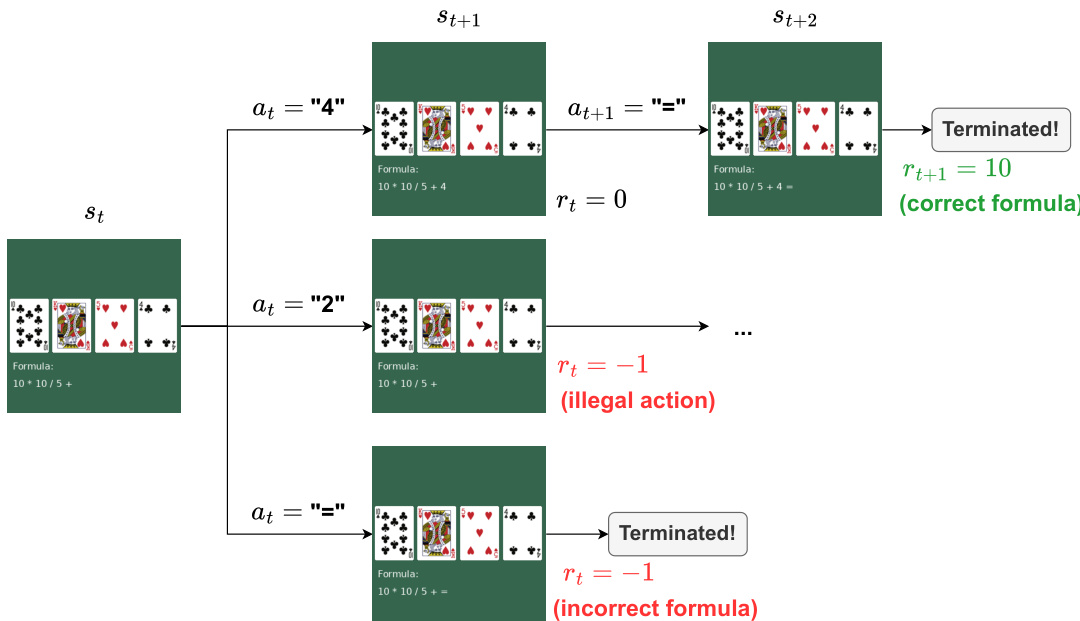
θminEo,(th,a)∼πθ[LPPO(o,a)+LSFT(o,πcorr(o,th))]As shown in the figure below, the framework is applied to specific environments like the Points24 card game. In this task, the agent observes an image of four cards and a current formula. The goal is to form a formula equal to 24. The environment provides rewards based on the validity of the action and the final outcome. For instance, an illegal action yields a reward of −1, while a legal action yields 0. If the episode terminates with a correct formula evaluating to 24, the agent receives a reward of 10.
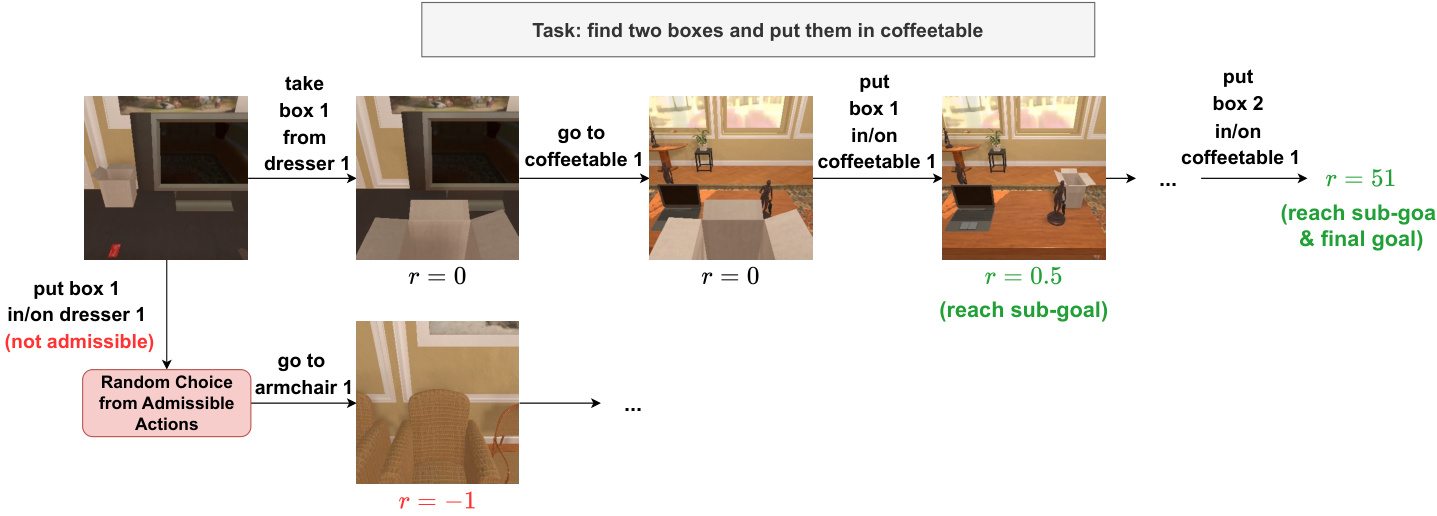
The method is also applicable to more complex robotic manipulation tasks, as illustrated in the task execution flow. In such environments, the agent must navigate, pick up objects, and place them in designated locations. The reward structure encourages reaching sub-goals, such as placing a box on a table, before achieving the final goal. This hierarchical reward signal helps guide the agent through long-horizon tasks.
To address the distribution shift issue that arises when incorporating thought cloning into PPO training, the authors adopt an interactive imitation learning algorithm known as Dataset Aggregation (DAgger). As the agent's policy updates, previous data is discarded and resampled. Performing thought cloning on this non-i.i.d dataset can lead to catastrophic forgetting. By aggregating all historical corrections and samples, the DAgger approach ensures convergence to the expert policy provided by the corrector model. The objective function is rewritten to separate the expectations over the PPO data buffer B and the DAgger thought dataset D:
θmin(s,a)∼BELPPO(s,a)+(s,th)∼DELSFT(s,πcorr(s,th)).Finally, to improve data quality during RL training, the authors incorporate a token-level repetition penalty and explicitly integrate format judgment into the corrector model. This ensures that answers with valid formats receive a format reward at each step. Additionally, the corrector model can leverage function-calling abilities to access specific information, such as calculating possible equations in the Points24 game. This capability allows for data sampling control, where episodes can be truncated if the agent enters unsolvable states, thereby improving the efficiency of the RL training.
Experiment
The study evaluates the Guided Thought Reinforcement framework on the complex Points24 reasoning task and the multimodal ALFWorld benchmark to assess performance in long-horizon decision-making. Experiments reveal that process guidance effectively prevents thought collapse, enabling agents to achieve substantial performance gains over baseline reinforcement learning methods that rely solely on outcome rewards. Furthermore, ablation analyses confirm that maintaining continuous thought supervision and utilizing a capable corrector model are critical for stabilizing training and ensuring coherent reasoning throughout the learning process.
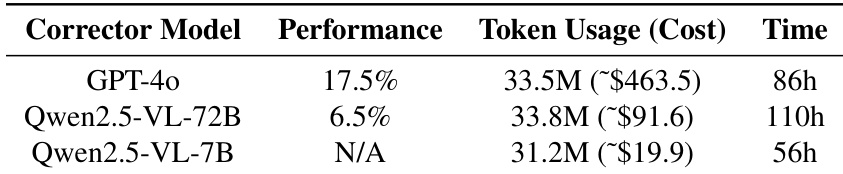
The study evaluates the trade-offs between performance and computational overhead when using different corrector models for the GTR framework. GPT-4o provides the highest success rate but comes with the highest financial cost and training duration. Open-source alternatives offer cost savings but struggle with performance, where the larger model underperforms due to tool-use issues and the smaller model fails to adhere to correction formats. GPT-4o achieves the best task success rate but requires significantly more time and financial resources than open-source models. The Qwen2.5-VL-72B model offers a cost advantage over GPT-4o but suffers from a substantial drop in performance. The Qwen2.5-VL-7B model is the most resource-efficient option but is unable to follow the necessary correction formats for effective training.
The authors evaluate the GTR framework on the Points24 task, demonstrating its superior performance compared to various baselines including commercial models and standard reinforcement learning methods. Results indicate that GTR achieves the highest success rate and episode return, significantly outperforming approaches that lack process guidance. These findings validate the effectiveness of integrating automated thought correction with reinforcement learning for complex visual reasoning tasks. GTR demonstrates the highest success rate and episode return among all evaluated models. The method significantly outperforms reinforcement learning baselines and SFT-only approaches. Commercial models and other baselines struggle to solve the task effectively compared to GTR.
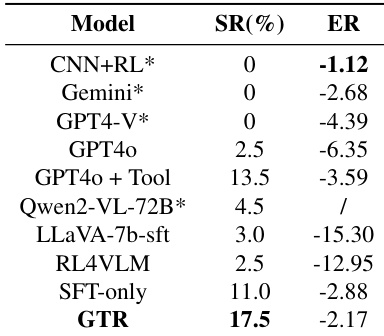
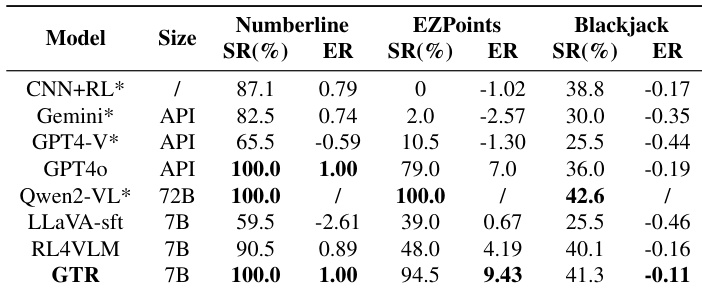
The the the table evaluates model performance on simpler tasks within the gym_cards environment, specifically Numberline, EZPoints, and Blackjack, where decision spaces are smaller. The proposed GTR framework demonstrates robust capabilities, achieving results comparable to much larger models while significantly outperforming other 7B parameter baselines. GTR achieves perfect success rates on the Numberline task, matching the performance of the significantly larger Qwen2-VL model. On the EZPoints task, GTR substantially outperforms the RL4VLM baseline in both success rate and episode return. The framework shows consistent improvements over SFT-only methods across all three evaluated tasks.
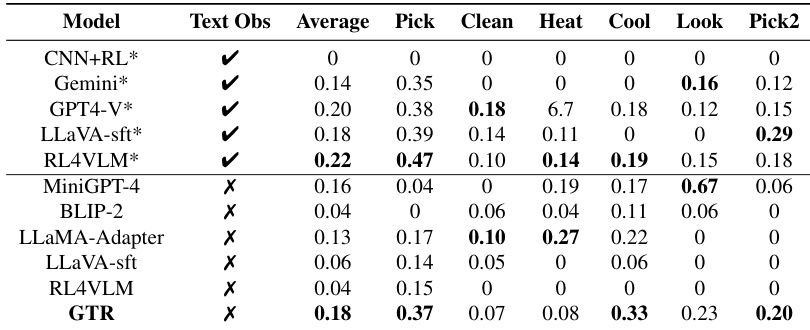
The the the table evaluates vision-language models on ALFWorld embodied tasks, distinguishing between configurations that utilize textual observations and those relying solely on visual input. The proposed GTR framework demonstrates superior performance among models without textual assistance, achieving the highest average score and leading results in specific categories. Models utilizing textual descriptions generally achieve higher average scores compared to those restricted to visual inputs alone. GTR outperforms other baselines in the no-text setting, particularly excelling in tasks involving cooling and picking multiple objects. MiniGPT-4 shows distinct strength in the Look task, while LLaMA-Adapter performs notably well in Heat-related scenarios.
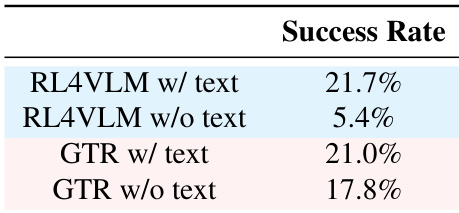
The provided data evaluates the success rates of the GTR framework and the RL4VLM baseline on the ALFWorld benchmark, specifically comparing performance with and without textual scene descriptions. The results show that while the baseline method relies heavily on text inputs to succeed, GTR maintains high performance even when text descriptions are removed. This indicates that GTR effectively utilizes visual information and process guidance to solve complex tasks without depending on textual shortcuts. GTR maintains robust performance in text-free settings where the baseline method fails significantly. Both methods achieve comparable success rates when text descriptions are provided. The framework demonstrates superior visual reasoning capabilities compared to the baseline when textual inputs are unavailable.
This study evaluates the GTR framework by comparing corrector model trade-offs and benchmarking performance against various baselines across Points24, gym_cards, and ALFWorld tasks. While GPT-4o yields the highest success rate, open-source alternatives incur significant performance drops due to tool-use and format adherence challenges. The framework consistently outperforms reinforcement learning and supervised fine-tuning methods, validating its effectiveness in complex visual reasoning and maintaining robust results even without textual scene descriptions.