HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
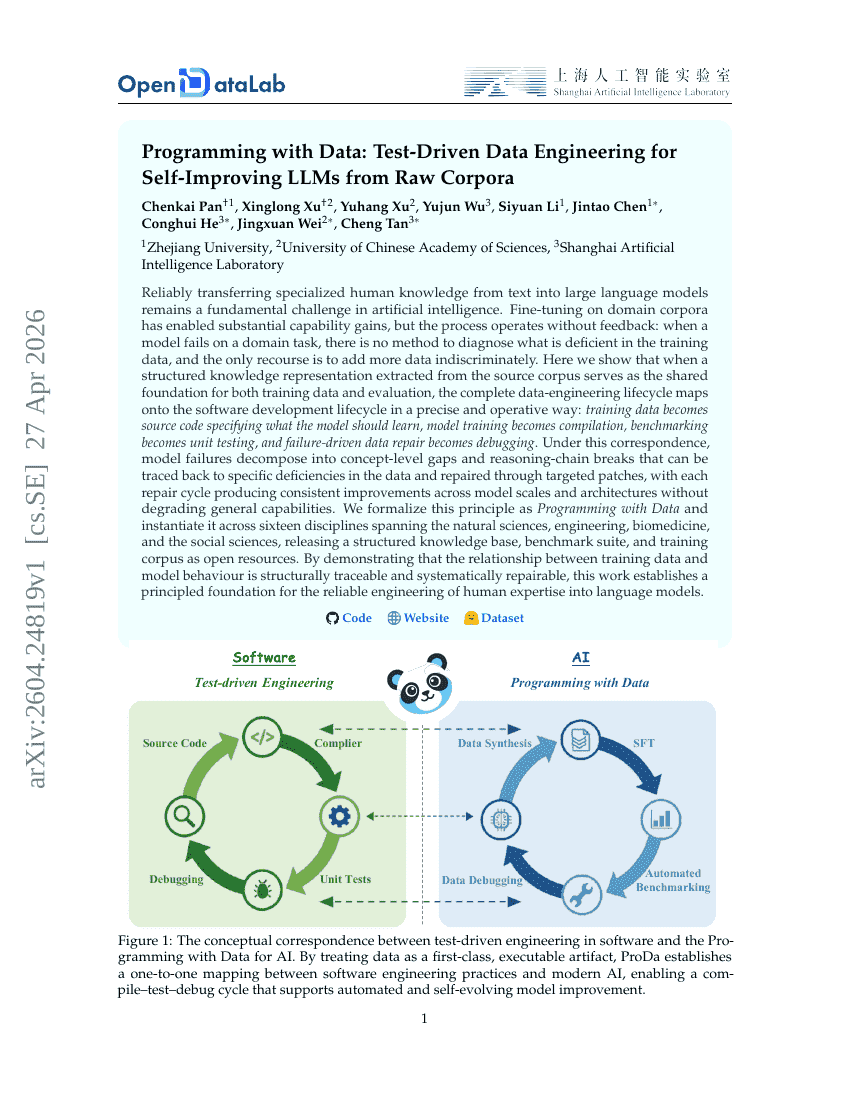
データによるプログラミング:生データコーパスから自己進化型大規模言語モデルのためのテスト駆動型データエンジニアリング
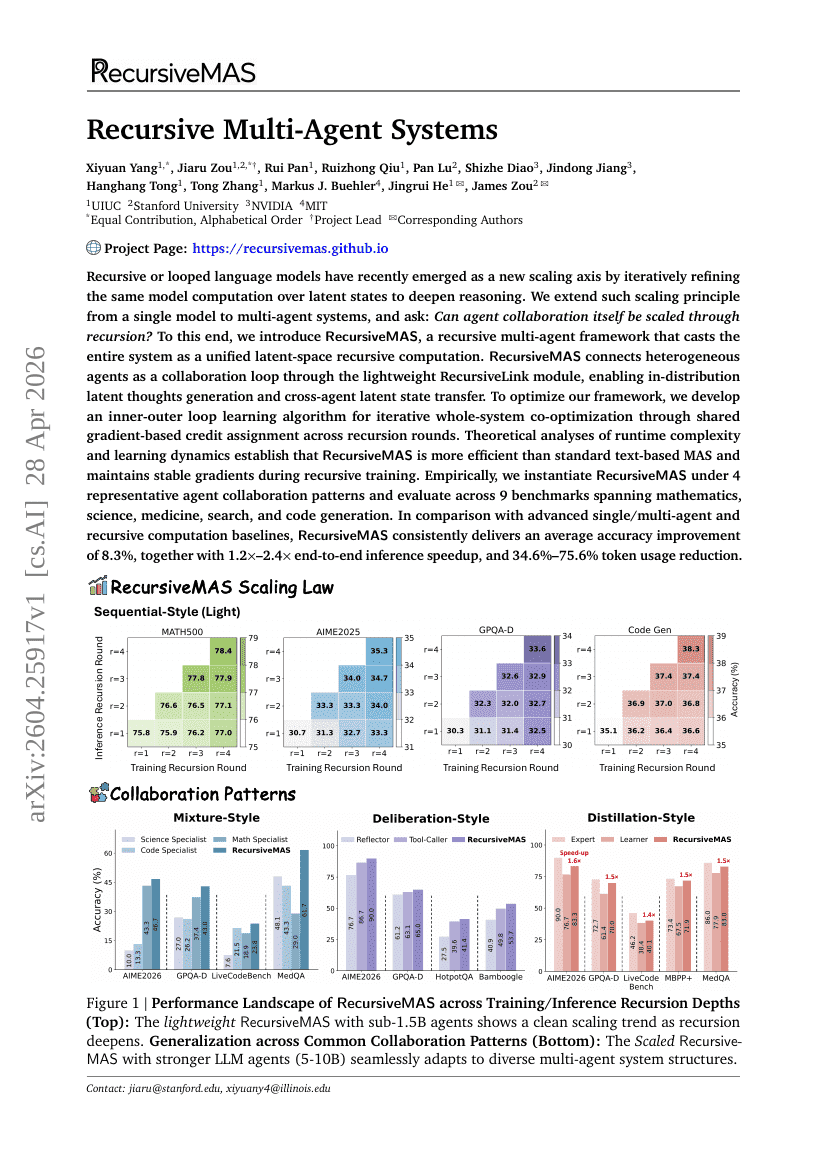
再帰型マルチエージェントシステム





























データによるプログラミング:生データコーパスから自己進化型大規模言語モデルのためのテスト駆動型データエンジニアリング
再帰型マルチエージェントシステム
エージェント型AIに対するスキル検索拡張
SketchVLM:ビジョン言語モデルは思考を説明するために画像を注釈付けし、ユーザーをガイドすることができます。
RSRCC: 検索拡張ベスト・オブ・N 順位付けによって構築されたリモートセンシング地域変化理解ベンチマーク
LongSpeech: 長尺音声における文字起こし、翻訳、理解のためのスケーラブルなベンチマーク
ClawMark: 複数ターン・複数日間にわたるマルチモーダルcoworker agents向けのライブワールドベンチマーク
Tuna-2: ピクセル埋め込みは、マルチモーダルな理解と生成においてビジョンエンコーダを上回る (訳注:学術文脈における「beat」は、パフォーマンス比較の文脈において「~を上回る」「凌駕する」等の表現で訳すのが一般的ですが、タイトルとして簡潔に「勝る」「凌ぐ」の意味を込めて「上回る」としました。また、技術用語「Pixel Embeddings」は「ピクセル埋め込み」、「Vision Encoders」は「ビジョンエンコーダ」と訳しています。)
ビジョン・言語・アクションの安全性:脅威、課題、評価、そしてメカニズム
ReVSI:VLMの3D推論能力を正確に評価するための視覚的空間知能評価の再構築
スキルから人材へ:現実の企業として異質なエージェントを組織化する
World-R1: テキストから動画生成に対する3次元制約の強化
意味論的進行関数を用いたビデオ解析および生成
SmartPhotoCrafter: 自動写真画像編集のための統合的な推論・生成・最適化フレームワーク
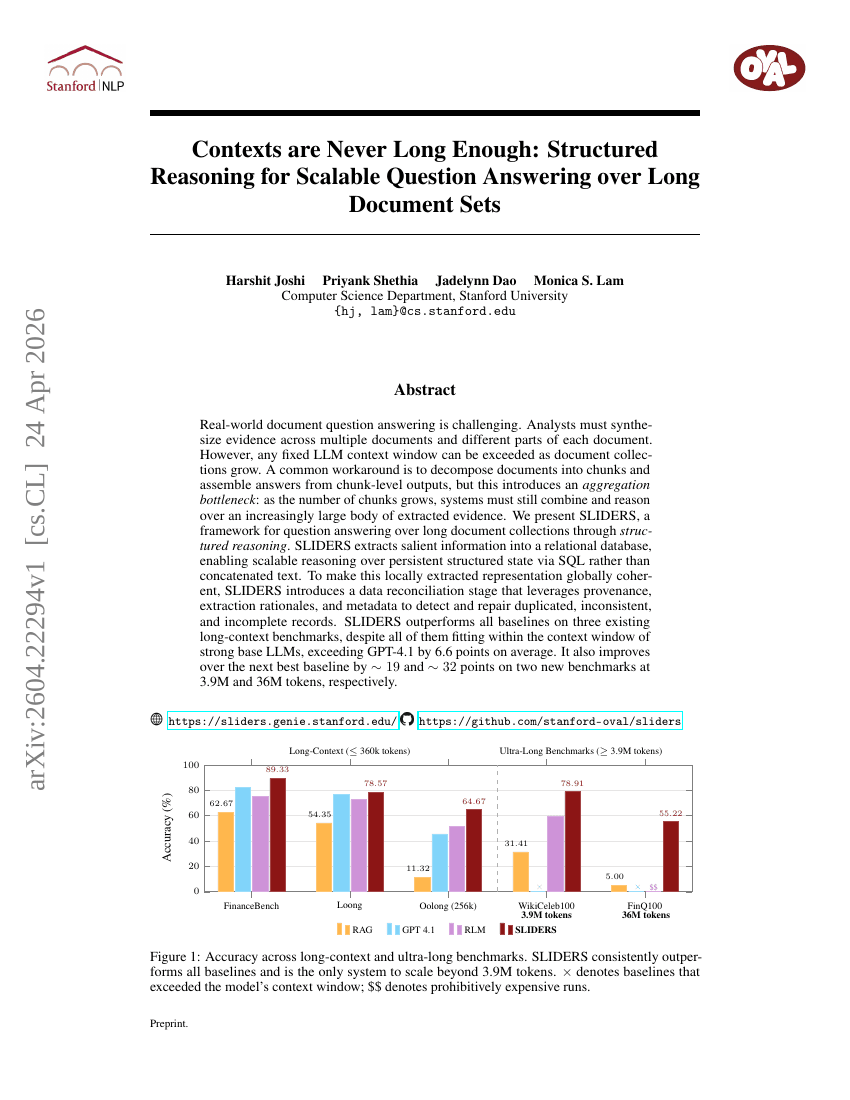
コンテキストは常に不十分である:長大な文書集合に対するスケーラブルな質問応答のための構造化推論
AgentSearchBench: 実世界のAI agent検索におけるベンチマーク
FlowAnchor: Inversion-freeなビデオ編集に向けた編集信号の安定化
内部表現を用いたLLMの安全性確保:有害コンテンツの検出
DiffNR: 疎な視点からの3D断層再構成に向けた拡散モデルによるニューラル表現最適化の強化
Agentic World Modeling:基盤、能力、法則、そしてその先へ
強靭な分散型事前学習のためのDecoupled DiLoCo
EVENT TENSOR: 動的MEGAKERNELをコンパイルするための統一的抽象化
速い動きと遅い動きの認識:ビデオにおける時間の流れの学習
長期的タスクに向けたLLMの意思決定とSkill Bank agentの共進化
StyleID:スタイルに依存しない顔識別のための、知覚を考慮したデータセットおよび指標
UniT:人間からヒューマノイドへのpolicy学習および世界モデリングに向けた統一的物理言語の構築
WorldMark:インタラクティブなビデオ・ワールドモデルのための統一ベンチマークスイート
LLaTiSA:視覚的知覚から意味論に至る、難易度層別化された時系列推論に向けて
画像生成器は汎用的なビジョン学習器である
LongCat-Next: モダリティを離散的なtokenとして語彙化する
FIPO: Future-KLの影響を受けた方策最適化による深い推論の導出
強化学習におけるグループレベルの自然言語フィードバックを用いたBootstrapping型探索
エージェント型AIに対するスキル検索拡張
SketchVLM:ビジョン言語モデルは思考を説明するために画像を注釈付けし、ユーザーをガイドすることができます。
RSRCC: 検索拡張ベスト・オブ・N 順位付けによって構築されたリモートセンシング地域変化理解ベンチマーク
LongSpeech: 長尺音声における文字起こし、翻訳、理解のためのスケーラブルなベンチマーク
ClawMark: 複数ターン・複数日間にわたるマルチモーダルcoworker agents向けのライブワールドベンチマーク
Tuna-2: ピクセル埋め込みは、マルチモーダルな理解と生成においてビジョンエンコーダを上回る (訳注:学術文脈における「beat」は、パフォーマンス比較の文脈において「~を上回る」「凌駕する」等の表現で訳すのが一般的ですが、タイトルとして簡潔に「勝る」「凌ぐ」の意味を込めて「上回る」としました。また、技術用語「Pixel Embeddings」は「ピクセル埋め込み」、「Vision Encoders」は「ビジョンエンコーダ」と訳しています。)
ビジョン・言語・アクションの安全性:脅威、課題、評価、そしてメカニズム
ReVSI:VLMの3D推論能力を正確に評価するための視覚的空間知能評価の再構築
スキルから人材へ:現実の企業として異質なエージェントを組織化する
World-R1: テキストから動画生成に対する3次元制約の強化
意味論的進行関数を用いたビデオ解析および生成
SmartPhotoCrafter: 自動写真画像編集のための統合的な推論・生成・最適化フレームワーク
コンテキストは常に不十分である:長大な文書集合に対するスケーラブルな質問応答のための構造化推論
AgentSearchBench: 実世界のAI agent検索におけるベンチマーク
FlowAnchor: Inversion-freeなビデオ編集に向けた編集信号の安定化
内部表現を用いたLLMの安全性確保:有害コンテンツの検出
DiffNR: 疎な視点からの3D断層再構成に向けた拡散モデルによるニューラル表現最適化の強化
Agentic World Modeling:基盤、能力、法則、そしてその先へ
強靭な分散型事前学習のためのDecoupled DiLoCo
EVENT TENSOR: 動的MEGAKERNELをコンパイルするための統一的抽象化
速い動きと遅い動きの認識:ビデオにおける時間の流れの学習
長期的タスクに向けたLLMの意思決定とSkill Bank agentの共進化
StyleID:スタイルに依存しない顔識別のための、知覚を考慮したデータセットおよび指標
UniT:人間からヒューマノイドへのpolicy学習および世界モデリングに向けた統一的物理言語の構築
WorldMark:インタラクティブなビデオ・ワールドモデルのための統一ベンチマークスイート
LLaTiSA:視覚的知覚から意味論に至る、難易度層別化された時系列推論に向けて
画像生成器は汎用的なビジョン学習器である
LongCat-Next: モダリティを離散的なtokenとして語彙化する
FIPO: Future-KLの影響を受けた方策最適化による深い推論の導出
強化学習におけるグループレベルの自然言語フィードバックを用いたBootstrapping型探索